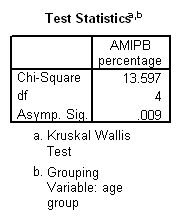Syntactical complexity of speech as measured by the Index of Language Complexity (ILC)
correlates with working memory capacity
This thesis presents a new objective measure of linguistic complexity based on measuring the frequency of ‘optional’ syntactical elements of spoken human language, and report that linguistic complexity correlates significantly and positively with working memory capacity. This is consistent with human linguistic performance being a sexually-selected trait ‘advertising’ the genetic fitness of the speaker.
Previous methods of measuring linguistic complexity lack objectivity, reliability or a convincing theoretical rationale. We devised the Index of Language Complexity (ILC) as an objective, linguistically-principled and plausible measure of syntactic linguistic complexity.
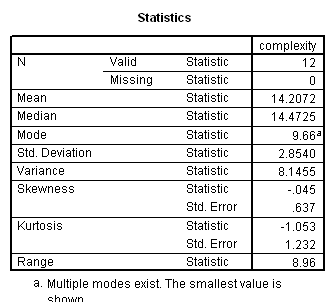
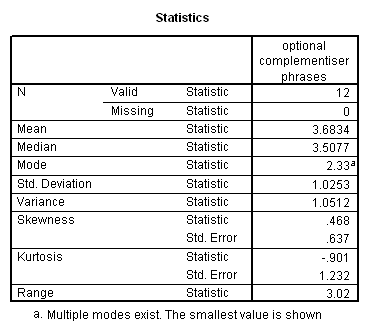
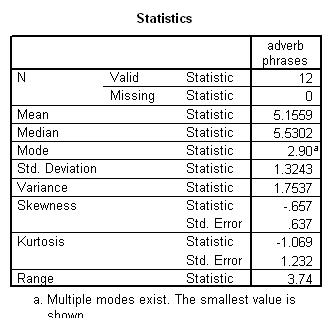
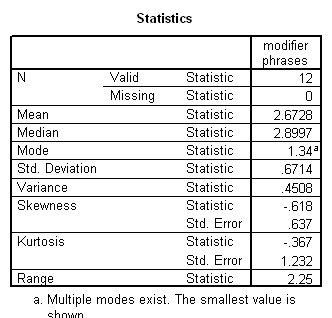
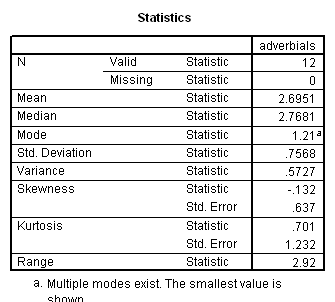
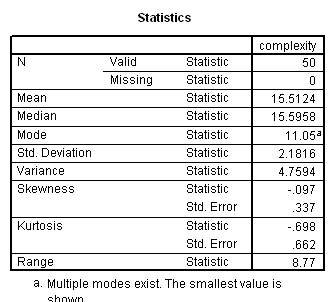
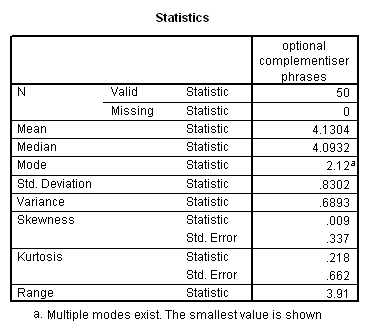
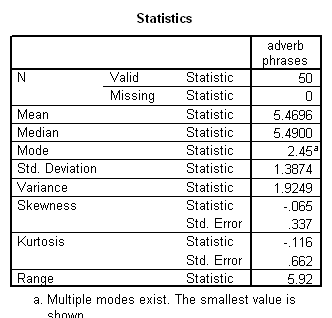
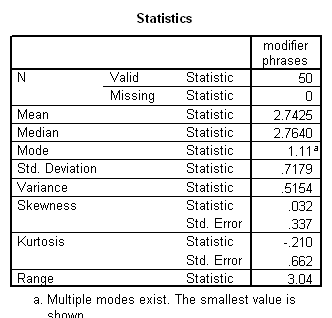
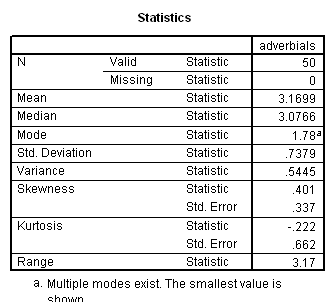
Language complexity was conceptualized in terms of ‘optional’ syntactical elements, which serve to modify the obligatory syntactical elements, potentially enriching basic ‘factual’ communications with socially-inflected interpretations. The ILC score was defined as the combined frequency of occurrence per 100 intelligible transcribed words of 1. optional complementiser phrases, 2. adverb phrases, 3. modifier phrases and 4. adverbials.
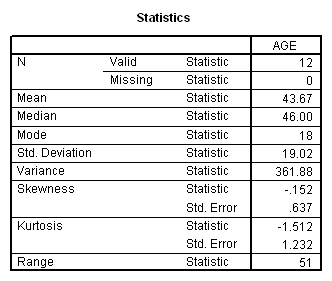
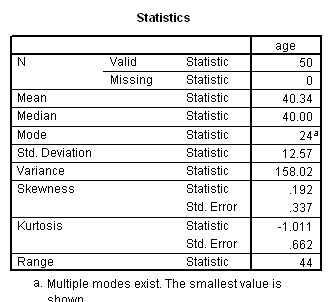
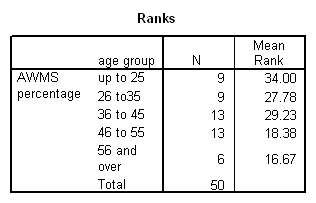
Fifty native British-English speakers were studied (25 male, 25 female; age 22-66). Spoken language was elicited using standard stimuli such as asking for explanations of factual information, telling a story in response to pictures, encouraging speculations on general topics. Speech was recorded and transcribed.
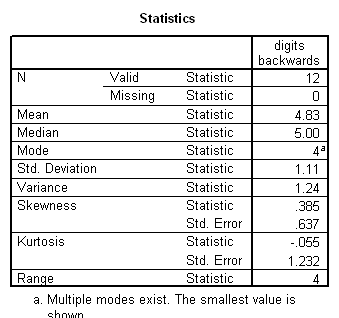
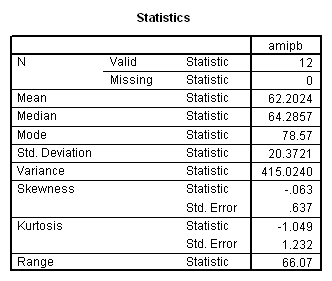
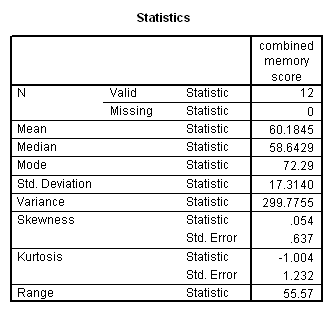
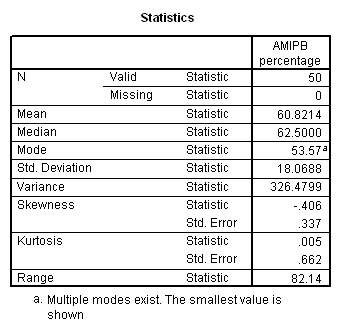
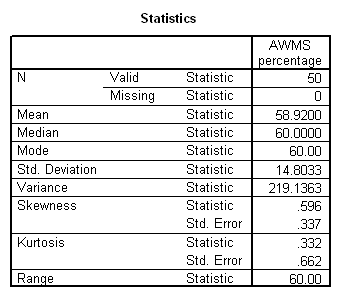
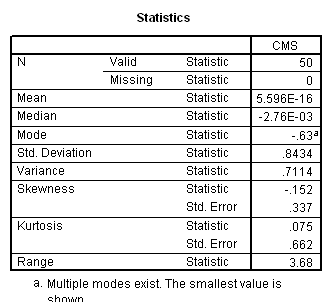
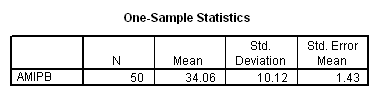
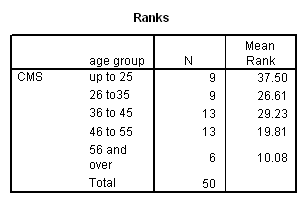
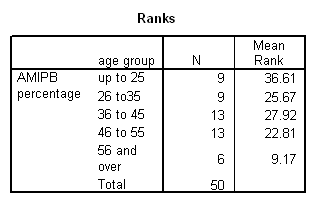
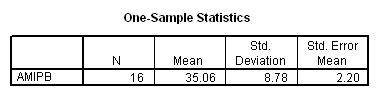
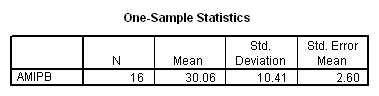
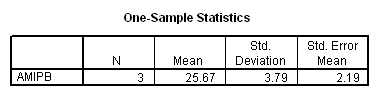
Working capacity was measured using a Combined Memory Score (CMS) which averaged the standardized scores of the Adult Memory and Information Processing Battery (AMIPB) subtest (recall of a short story) and a modified Working Memory Span test (recall of specific words from increasing numbers of sentences, followed by a judgement task to interfere with rehearsal).
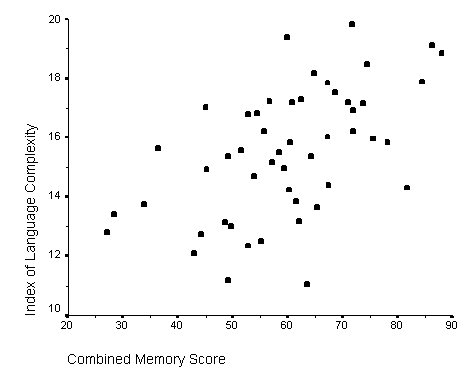
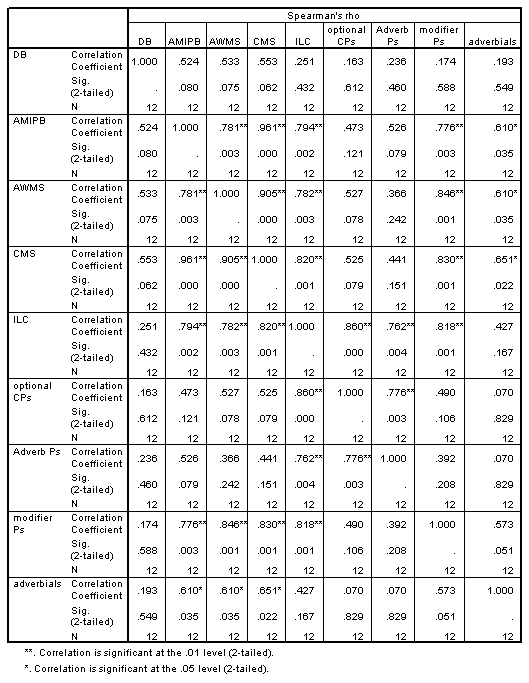
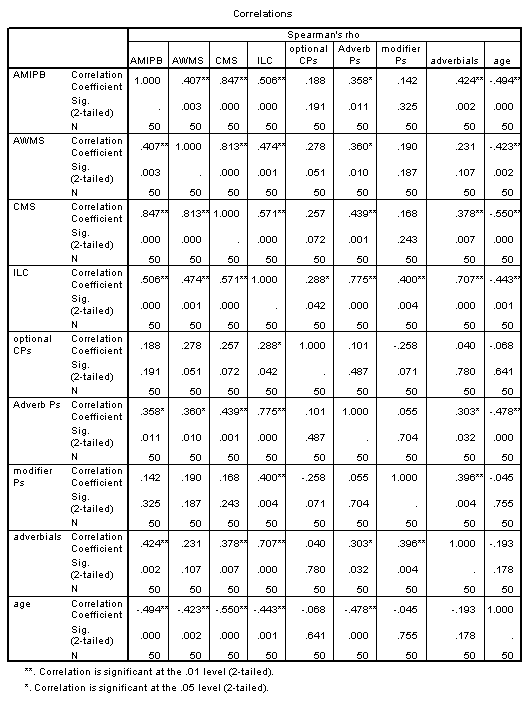
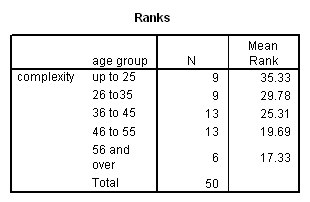
Results showed a significant positive correlation between language complexity (ILC) and working memory capacity (CMS) (see Figure). There was also a significant positive correlation between CMS and each of the four components of the ILC, consistent with internal validity of the ILC.
Spearman's rank order correlation: 0.820, p = 0.001
The correlation between CMS and ILC score is consistent with syntactical complexity being constrained by working memory capacity. This may imply an evolutionary expansion of working memory as the crucial element enabling the evolution of human language. For instance, the ability of bonobos and chimpanzees to communicate with humans is enhanced by visual symbol boards, which may function to expand working memory capacity.
It seems that people spontaneously tend to produce language at approximately the maximum syntactic complexity allowed by their working memory capacity.
Working memory is a vital substrate of ‘creative intelligence’ which Geoffrey Miller sees as the basis for human sexual selection for ‘good genes’, because creative intelligence requires a well-functioning brain, and most deleterious genetic mutations will damage brain function.
Syntactically sophisticated language may therefore function as an honest advertisement of biological fitness, potentially explaining why articulate, eloquent speech is so attractive.
Language complexity, working memory and social intelligence by Christina Susan Fry, supervised by BG Charlton
(PhD thesis; University of Newcastle upon Tyne, UK; 2002)
1. General introduction
Many studies have shown that ability varies from one individual to another in the comprehension of complexity in language, and that this spectrum of ability is correlated with working memory capacity. This study was intended firstly, to devise an objective and valid instrument to measure complexity in language production; secondly, to refine a measure of working memory; and thirdly to determine the relationship between the ability to produce complexity in spontaneous speech and working memory ability.
In order to do this, it was necessary first to devise a complexity metric, for the purpose of delineating and quantifying those elements that constitute complexity in production. This complexity metric, the Index of Language Complexity, was formulated on the basis of evolutionary theory, syntactic criteria, and evidence from language development and disorders. Existing assessments of complexity were examined but rejected, since many of the existing measures show a lack of objectivity, and none takes into account the contribution of what is proposed as the major reason for language to have evolved, namely, the transfer of social intelligence information.
The measure of complexity used in this study (the Index of Language Complexity) centres on the optionality of the elements expressed. In expressing a proposition, none of the obligatory elements may be omitted without causing the utterance to become ungrammatical. Optional elements may, by definition, be freely omitted, but it is these elements that help to express the speaker’s attitude, and it is by means of them that social intelligence information is signalled. Their very optionality makes such elements vulnerable to loss in language disorder, or lower ability levels.
It is hypothesised that people speak in as complex a manner as they are able, and that lower levels of complexity in spontaneous speech are due to the constraints imposed by working memory limitations. Complex language therefore advertises working memory ability, as well as demonstrating social intelligence.
A pilot study (study 1), which comprises the bulk of this thesis, was conducted on 12 subjects, firstly to determine which stimuli would be suited to the task of measuring working memory and eliciting sufficient spontaneous speech data; secondly to establish a workable method for transcription, and categorisation of the data; and thirdly to provide data on the basis of which theoretical expectations of complexity could be tested, and complexity criteria refined. Study 1 established instruments for the measurement of complexity and working memory, and a standard methodology for eliciting, transcribing, and categorising data.
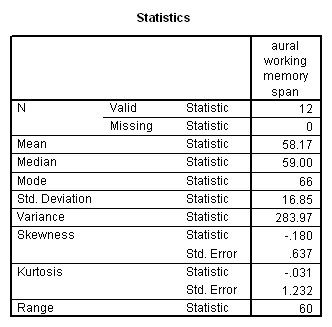
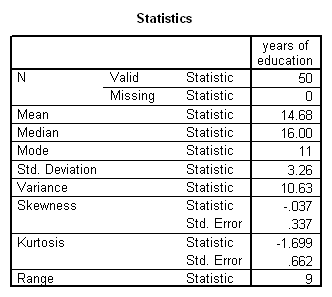
The replication study (study 2) investigation was of spontaneous speech data, collected from 50 normal adults (aged 22 to 66 years) using a test interview as the stimulus. The test interview included two tests of working memory: one an existing neuropsychological test, the other a newly-created version of the working memory span paradigm. This Aural Working Memory Span test took into account word class, word length, word frequency, and age of acquisition.
Two tests of working memory were amalgamated to create the Combined Memory Score, and the Index of Language Complexity provided a quantitative measure of complexity in language production.
This thesis is organised in three parts. The first consists of introductory literature reviews of the three areas of interest: social intelligence, working memory, and language. The second part, which comprises the greater part of the thesis, deals with the pilot study (study 1): the considerations involved in the formulation of the test interview, the development of the complexity metric, and the method for transcription and categorisation. The third part sets out the details of the replication study (study 2), its findings, and their implications. The test stimuli and transcriptions are given in the appendices.
1. Social intelligence
Social intelligence concerns how individuals perceive, recall, think about and interpret information about the actions of themselves and others (Reber & Reber 2001:687), and it is of vital importance to the reproductive success of social animals, such as humans. A socially skilled person is able to affect others positively, with the effect that he intended, and is capable in turn of being affected by others (Ylvisaker et al. 1998:271). An individual who is unable to perceive the dispositions and intentions of others will not be able to produce adaptive social behaviour, since he will be unable to take into account the complexities of social life and contrive suitable responses (Byrne & Whiten 1997:2). Impaired social intelligence involves a loss of social concepts and rules, difficulty in drawing inferences about causes of behaviour, and impaired perception of social cues (Ylvisaker et al. 1998:273). The consequences of impairments in this field can be catastrophic, outweighing those of other cognitive disabilities (Broks 1997:100). The cumulative emotional effect of social failure leads to anger, hostility, depression, and withdrawal, and the individual has no goals, no activities and no friends (Ylvisaker et al. 1998:275). In evolutionary terms, this spells “reproductive death”, since, once social success is equated to good biological fitness, social failure means lack of fitness (Humphrey 1988:21).
Clearly possessing good social intelligence skills brings personal benefits to the individual, and living in a group, all of whom possess such skills is equally advantageous. A study of people in rural Zambia (Serpell 1977, cited by Kagitcibasi 2000:337) showed that the children thought intelligent by the adults were not those who performed well on (culturally appropriate) intelligence tests, but rather those who were socially responsible and attuned to others’ needs. The highest value was placed on group well-being and interdependence, in preference to individual independence and self-reliance (Kagitcibasi 2000:337). The individual benefits from simultaneously preserving the overall structure of the group and yet out-manoeuvring others within it, but such social gamesmanship entails calculating the consequences of both one’s own behaviour, and the likely behaviour of others, and the ensuing balance of advantage and loss (Humphrey 1988:19). An individual needs considerable skill in social manipulation to achieve personal advantage to himself at the expense of others in the group, but without causing so much disruption that he is no longer accepted as a group member (Byrne & Whiten 1997:3).
1.1 Theory of Mind
In order to guess correctly how another person (B) will respond to an action of his, it is necessary for an individual (A) to be able to make inferences about B’s mental states (his beliefs and desires), and for this A needs Theory of Mind (ToM). Having ToM means that A can recognise firstly that B can have a particular belief, secondly that B’s belief may be different from A’s own belief, and thirdly that B’s belief may be mistaken. By about the age of four, most children can realise that a second person can have a different belief to their own, and that it can be a mistaken belief, but this realisation never develops in people with autism, who suffer from “mindblindness” (Baron-Cohen 1995).
It is through ToM that intentionality is interpreted: most people can cope with three levels of intentionality, some with four e.g. [A hopes [that B believes [that C thinks [that D knows X]]]] but by five levels of intentionality almost everyone is confused (Dunbar 1998:103). Although intentionality is expressed here through language, language is not necessary for access to knowledge of ToM in adults (Siegal et al. 2001:297). Two people have been reported (Varley et al. 2001) who both have severe aphasia and are unable to access language propositions in any modality, but who nonetheless pass tests of ToM. The researchers point out (Varley et al. 2001:492) that reasoning about others’ belief therefore does not take place through language propositions.
It seems probable that language is necessary for the full development of ToM. Japanese culture places great value on an indirect style of communication, avoiding the overt statement of that which could be inferred (Bishop 1997:207). Because it is of such importance in the culture to be able to anticipate the need of others (so they are not forced to make a direct request), mothers tell their children overtly what people are thinking and feeling in various situations: this has been shown in transcripts of mother-child interactions (Clancy 1986, cited by Bishop 1997:207). Deaf children born into hearing families are not usually exposed to native use of Sign until they reach school age. Communication with their family is generally limited, and does not include the normal focus on mental states that gives the basic grounding in shared beliefs (Siegal et al. 2001:298). Deaf children of hearing families perform on ToM tasks at a level comparable to children with autism (Siegal et al. 2001:298). Their difficulties do not generalise to causal reasoning in other domains, and are specific to reasoning about false belief (Siegal et al. 2001:298). The late signers’ problems with ToM reasoning can persist into late adolescence (Siegal et al. 2001:298).
It has been proposed (Cosmides & Tooby 2000) that a specialist, expert cognitive system exists specifically for reasoning about co-operation for mutual benefit and the detection of cheating. This sort of cognitive specialisation would have resulted from some of the most important adaptive problems faced by our ancestors: the need to optimise social interactions, and to detect and understand the consequences of behaviours both reliably and economically (Cosmides & Tooby 2000:1259-60).
If social intelligence constitutes a cognitive module, in the Fodorian sense, a specific neural architecture dedicated to the operation of that module would be expected. The central element in social intelligence is its intimate connections to emotion and the “irreducible richness of the spectrum of affects” (Brothers 1990:39). The individual receives powerful signals through the emotional coloration of his social experiences (Brothers 1990:41). These links with emotion are reflected in the brain areas subserving social intelligence.
1.2 Neural architecture of social intelligence
There is growing evidence that social intelligence is represented in the brain by the ventromedial prefrontal cortex, the amygdala, and the right somatosensory cortex and insula (Adolphs 1999:470). In a typical real-life situation the component structures of the system work in parallel (Adolphs 1999:477). The amygdala is involved in the fast and automatic evaluation of stimuli with emotional or social importance, and in allocating resources to process stimuli that are ambiguous but potentially important (Adolphs 1999:474,477). The right hemisphere is predominant in attentional systems which select which external stimuli should be focused upon, and hence are essential to survival (Geschwind & Galaburda 1987:45). The ventromedial prefrontal cortex is involved in associating perceptual representations of current stimuli with elements of previously encountered situations, triggering re-enactments of the corresponding emotional state; while the right somatosensory cortex provides the detailed representation of the body state (Adolphs 1999:474,477). The right hemisphere is important in both the subjective experience and external expression of emotion, as well as the recognition of emotion manifested by others (Geschwind & Galaburda 1987:45).
Damage to the frontal areas of the brain can cause impairments in social behaviour, while leaving other cognitive functioning intact (Broks 1997:113), and published case studies describe people who score in the high or superior IQ range, yet are unable to hold down a job or sustain marriages or friendships. People who have suffered damage to their ventromedial prefrontal cortex are unable to plan future activity, or to respond to punishment, and show inappropriate social behaviour, with a lack of concern or empathy for others (Adolphs 1999:474). People with orbitofrontal damage show a dissociation between fully intact abstract knowledge about social situations and badly impaired ability to evaluate real-life situations or draw conclusions about motivations, because they have lost access to the internal cues that should be generated by the actions of others (Brothers 1990:36-7). The somatic marker mechanism (SMM) is the means whereby the internal cue of the emotional value of an action is acquired, represented, and retrieved (Adolphs 1999:475).
1.3 Somatic marker mechanism
Making a good decision means selecting a response that will be ultimately advantageous in terms both of reproductive success, and of the quality of continued existence (Damasio 1994:169). The thought of a bad outcome brings about a transitory unpleasant “gut feeling”, which leads to the rejection of the response that triggered it: this is the somatic marker at work (Damasio 1994:173). The “gut feeling” is the somatic (body) state, the current state of all the bodily systems: the muscles, joints, skin, nerves, viscera, blood chemistry, etc. (Charlton 2000:160).
The neural substrates of most of the structures important to social intelligence reasoning are also important to normal emotional functioning (Adolphs 1999:477). Damasio (1995:20) describes an emotion, which is expressive, as being a collection of changes to the state of the body and brain responding to the content of thoughts about a particular entity or event. By contrast, a feeling is experiential, being the awareness of the changes induced by the emotion, juxtaposed with the mental image that triggered those changes (Damasio 1995:20-1).
The simultaneous holding of both the changes wrought by the emotion and the triggering mental image is performed in working memory, over a time scale ranging from hundreds to thousands of milliseconds (Damasio 1994:197). Working memory constitutes the arena where perceptual feedback about body states marks possible outcomes as positive or negative, and this evaluative process influences the operation of continued and attention working memory (Damasio 1994:197-8).
Associations between a particular class of situation and a particular body state are made in the ventromedial prefrontal area (Damasio 1996:1414). These links are dispositional (implicit) representations, potential patterns of activity in small assemblies of neurons, which hold the potential to reactivate an emotion (Damasio 1994:102). When there arises a situation some aspect of which has previously been encountered, related dispositions are activated, leading to the recall of pertinent information and emotional marking (Damasio 1996:1415).
The somatic marker increases the accuracy and efficiency of decision making, because it leads to an immediate rejection of an unpleasantly-marked possibility, and thereby lessens the number of alternatives left to be chosen between (Damasio 1994:173). At a conscious level, the somatic marker mechanism marks outcomes as positive or negative, and thereby leads to the deliberate avoidance or pursuit of a particular response (Damasio 1991:406). The somatic marker mechanism also works covertly, exciting or inhibiting subcortical neurotransmitter systems, by which means it provides subtle markers that suffice to interrupt an ongoing thought or action, switching attention to one set of representations rather than another (Damasio 1991:406). By biasing cognitive processing in this way, somatic markers steer decision making towards those outcomes that are advantageous to the individual (Adolphs 1999:475).
This kind of emotional processing not only guides the individual’s own behaviour, but can also be used to create models of other people through simulation (Adolphs 1999:477), resulting effectively in Theory of Mind. What another person is likely to do can be predicted by running in one’s brain a simulation of the same processes that the other person is running in his (Adolphs 1999:476). In other words, the somatic marker mechanism is used in the mental modelling and evaluation of past and future events: it is therefore vital for planning.
1.4 Summary
This chapter has established that social intelligence is necessary to humans for optimal biological functioning, and has discussed some of its probable neural mechanisms.
The next chapter looks at working memory, which is essential for the manipulation of social intelligence representations.
2. Working memory
The focus now moves to working memory, because social intelligence, in the guise of evaluation and planning, requires working memory for the temporary storage and manipulation of information pertinent to social intelligence.
This introductory section outlines what is meant by working memory. Section 3.2 deals with the established model of working memory, including discussion of the recently-proposed episodic buffer in section 3.2.1, and of long-term working memory in section 3.2.2. Working memory capacity is the topic of section 3.3, followed by chunking (in section 3.3.1) and individual variation (in section 3.3.2). Section 3.4 goes into working memory and ageing, and section 3.5 discusses working memory and social intelligence.
2.1 Working memory
There is general agreement (Gordon 1997:306-7) that information (including facts about language) is stored cortically where it is used, in that region or combination of regions responsible for the underlying functions. When access to stored information is needed, activation is required not only in the relevant storage area but also in the multiple prefrontal regions deemed to be involved in memory search and co-ordination, as well as in the temporary storage of information and the intermediate products of processing (Gordon 1997:308). This is the function of working memory (WM), acting as a scratchpad that allows both old and new information to be briefly maintained in an active and manipulable form (Gordon 1997:307). The contents of long term memory (LTM) would be worthless, were it not for WM, which enables the stored long term memories to be brought together with ongoing sensory input in order to meet current demands (Bradshaw & Mattingley 1995:209). People with dorsolateral prefrontal brain damage exemplify such a deficit, as, despite having relatively intact long term memory, they are unable to integrate past events and immediate requirements on a moment to moment basis (Bradshaw & Mattingley 1995:209).
The defining quality of WM is its transient, on-line nature, providing a temporal bridge between both internally and externally generated events (Goldman-Rakic 1997:559). Its purpose is to bring representations to mind, and to keep them activated while cognitive processes operate on them. There is evidence at the cellular level for the role of prefrontal neurons in the maintenance of representational information in the absence of the original stimulus (Goldman-Rakic 1996:1448). It appears that WM hinges on a network of brain areas, depending on the task, stimuli and strategy involved, with the prefrontal regions playing an executive, supervisory role (Bradshaw & Mattingley 1995:210). Encoding and retrieval of semantic material, as well as other verbal processes engages inferior lateral, and/or anterior prefrontal regions, in addition to the insula (Goldman-Rakic 1996:1450). It is postulated that the increase in WM in humans has not so much added to the length of activation, but has rather allowed simultaneous access to more, and more complex, representations (Charlton 2000:181).
2.2 Working memory model
The now standard view is that WM is a tripartite system (Baddeley 1996:13469), with a central executive controlling attention, and two slave systems: a phonological loop to hold and manipulate speech-based information, and a visuospatial sketchpad functioning in the same way for visual images. Baddeley remarks (1996:13469) that, although it is far from complete, the tripartite model has been remarkably successful, both in accounting for experimental data, and in providing a framework for investigation.
Figure 3-1 Working memory tripartite model
The central executive is seen as a limited-capacity attentional system that controls the phonological loop and visuospatial sketchpad, and relates them to long-term memory (Baddeley 1999:66). The central executive has the capacity to focus attention, and to switch attention from one focus to another, as is needed to co-ordinate social behaviour (Baddeley 1996:13471). It is also a fractionable system that is involved more in encoding than in retrieval (Baddeley 2001:117). Cappa notes (2000:74) that executive functions (including action planning, reasoning, and problem solving) cannot be modular in the Fodorian sense of being computationally autonomous and informationally encapsulated, because they require access to unrestricted information, in order to function adequately. Moreover, functional imaging studies (some using functional magnetic resonance imaging (fMRI), and some positron emission tomography (PET)) suggest a common network of regions in the mid-dorsolateral, mid-ventrolateral, anterior insular, and anterior cingulate regions, which are recruited to solve diverse cognitive problems such as response selection, WM maintenance, and stimulus recognition (Duncan & Owen 2000:476,480).
An alternative view (based on the functional architecture of non-human primates) is that the central executive may be seen as an emergent property of the interactive operation of multiple domain-specific processors each connected to domain-relevant storage sites in posterior regions and to motor pathways (Goldman-Rakic 1996:1445,1450-1). This conception seems plausible, in view of evidence about frontal-subcortical circuits, sharing a prototypic structure, which are contiguous while remaining anatomically segregated, and about frontal lobe syndromes which are recapitulated by the similarities in performance deficits caused by damage at various levels of each circuit (Cummings 1993:873-7). The multiple domain model is also compatible with the idea of convergence zones holding a record of temporal conjunctions of activities in other structures (Damasio 1996:1416).
The phonological loop holds auditory information for some 1½ -2 seconds (crosslinguistically constant) before the traces decay, although they may be maintained for about 10 seconds by articulatory rehearsal (Fabbro 1999:94). In a study of regional cerebral blood flow (rCBF), the two components of the phonological loop were localised in different areas of the brain: the phonological store in the left supramarginal gyrus (BA40), and the subvocal rehearsal system in the left Broca’s area (BA44) (Paulesu et al. 1993:344).
The phonological loop is thought to have evolved as a system to mediate language learning, with the primary purpose of storing novel speech input while more permanent memory records are constructed (Baddeley et al. 1998:170,158-9). A visuospatial “phonological loop” is claimed to exist in prelingually deaf signers. The internal structure is said to be strikingly similar to the phonological loop for speech, although American Sign Language does not appear to support as long a memory span as does the auditory phonological loop (Wilson & Emmorey 1997:317,319).
Tasks using the visuospatial sketchpad are thought to place heavier demands on the central executive, as many uses of visual imagery are less automatic than is phonological coding (Baddeley 1996:13470). The more visual aspects of imagery depend on the occipital lobes, while the more spatial aspects reflect activity in the parietal lobes, although the frontal lobes may also be involved in an imagery controlling function (Baddeley 1999:64-5). Imaging studies using PET found spatial WM to be mediated by a network of predominantly right hemisphere regions: the premotor and superior parietal areas mediate spatial rehearsal, while the inferior posterior parietal and anterior occipital areas mediate the storage function (Smith & Jonides 1998:12065).
There is evidence for other WM buffers: Jonides et al. (1996:82) report a number of studies that suggest the existence of a motoric WM, an auditory memory that does not store a phonological code, a semantic or propositional code and a dissociation between spatial and visual-object information.
2.2.1 The episodic buffer
Baddeley (2000a) has recently proposed a fourth WM component, the episodic buffer. The episodic buffer uses a multimodal code to provide temporary storage of information from the subsidiary systems and from LTM, binding such information into a unitary episodic representation (Baddeley 2000a:417). The buffer holds episodes by which information is integrated across space and possibly across time (Baddeley 2000a:421), hence it is called episodic.
Figure 3-2 Episodic buffer (Baddeley (2000:421))
The shaded areas in the lower box represent crystallised cognitive systems capable of accumulating long term knowledge, while the unshaded areas represent fluid capacities such as attention and temporary storage (Baddeley 2000a:421).
Baddeley (2000a:420) reports evidence for a store capable of operating beyond the timescale assumed for the slave systems, that can temporarily hold and manipulate information such as that involved in the comprehension of a prose passage, which involves the activation of existing structures in LTM. Information such as a schema from LTM may be used to organise new material into chunks, but this raises the question of how this information is integrated and where the newly-formed chunks are stored (Baddeley 2000a:419).
Evidence for the episodic buffer as an integrated store of information from different modalities and systems is adduced (Baddeley 2000a:421) from the effect of visual similarity on verbal recall and from the impact of meaning on immediate recall of sentences and prose. The episodic buffer is assumed to have a limited capacity, to be controlled by the central executive, and to play an important role as a conduit for information passing into episodic LTM, and for retrieving such information (Baddeley 2000a:421). As well as storing a limited number of chunks of material, the episodic buffer is a modelling space for the combination and manipulation of information, to plan future actions or interpret recollected experience (Baddeley 2001:118).
The episodic buffer emphasises the integration of information, and is conceived of as using a common multi-dimensional code, so that it can serve as an interface between a range of systems that each use different codes (Baddeley 2000a:422,421). It is anticipated that the episodic buffer will have a limited capacity because of the computational demands brought about by the binding problem caused by simultaneously accessing a wide range of codes (Baddeley 2000a:421). The binding problem concerns how to bind together all the aspects of a complex object or representation, so they are perceived as pertaining to the same entity. Binding may be either static when a representational unit stands for a specific conjunction of properties, or dynamic when representational units are tagged to indicate whether they are bound together, so bindings of units in the representation stand for conjunctions of properties (Hummel 1999:85). Although dynamic binding is more flexible than is static binding, one of its disadvantages is that it requires much more attention and WM, such that there are likely to be firm limits as to the number of distinct tags available for dynamic binding (Hummel 1999:85). Perception of illusory conjunctions of properties by people with neurological deficits suggests that the parietal cortex plays a role in the binding problem (Treisman 1996:174).
Baddeley suggests (2000a:421) that the central executive can retrieve information from the store in the form of conscious awareness, and that the central executive can reflect on, manipulate and modify that information. The episodic buffer constitutes a mechanism for creating new cognitive representations, since the central executive can influence the content of the buffer by attending to a given source of information, whether it be perceptual, from another WM component, or from LTM (Baddeley 2000a:421).
2.2.2 Long term and working memory
The relationship between WM and LTM is not clear-cut, and a number of differing conceptions of the relationship exist (Collette et al. 2000:49). Baddeley’s conception (1996:13472) of WM is as a gateway, providing an interface between perception, attention, memory and action: he specifically rejects (2000a:422) the idea that WM might be simply the activated portion of LTM. For Logie (1996:41) WM is seen as a workspace, a set of cognitive functions to temporarily store and process information, with the slave systems acting as working buffers for information that has yet to be processed or is about to be recalled overtly, since sensory input passes through LTM to reach WM (Logie 1996:55,41). Cowan envisages WM as consisting of a limited-capacity focus of attention, plus a temporarily-activated portion of permanent memory information, including some automatically activated information (Cowan 1998:77).
Evidence from highly skilled performance by experts led Ericsson and Kintsch to propose (1995:211-3) that WM includes a mechanism (long-term working memory (LT-WM)) based on storage in LTM, which is kept accessible by retrieval cues. Expert skill in particular domains and activities (e.g. mental calculation, chess, medical diagnosis, or remembering dinner orders) allows an individual to acquire LT-WM and hence to extend his WM for that particular activity (Ericsson & Kintsch 1995: 234-8,213-4). The increase in WM capacity seen in experts is specific to their domain of expertise, and is related to their level of skill (Ericsson & Kintsch 1995:238).
Text comprehension is claimed to be an acquired skill, so, rather than maintaining temporary information in WM, skilled readers have the ability to access LTM from retrieval cues held in the active portion of WM (Ericsson & Kintsch 1995:228-9). Text comprehension has, of course, only been possible as a skill base since the invention of writing, and prior to that all comprehension would have been of verbal material, the complexity of which would be restricted by performance limitations on the speaker. There must be a certain element of acquired skill in language production ability, such that people whose livelihood relies on their ability to communicate effectively (such as lecturers or barristers) will necessarily have had many hours of rehearsal and will no doubt have built up routinised elements. However, it seems likely that much of their expertise in communication would be restricted to imparting their specific field of knowledge, leaving them at no particular advantage in normal social situations.
2.3 Working memory capacity
Miyake and Shah (1999:464) raise the question of the functional or evolutionary significance of WM limitation, asking why WM should be limited, since individuals with large WM capacities have an advantage over those with smaller capacities.
There are two elements to consider with regard to WM limitation: the first is developmental, in that WM capacity will necessarily be constrained and limited by the volume taken up by the neurons dedicated to WM. It therefore seems likely that childhood limitations on WM are the result of the brain’s physical size and lack of myelination. WM is known to increase during childhood, and a child’s brain undergoes huge growth in infancy, doubling in weight in the first year of life, and attaining three-quarters of adult size by the age of three (Smith 1970:342).
Verbal WM span increases dramatically between infancy and adulthood: a four year old child has a digit span of two or three items, whereas a fourteen year old has a span of about seven (Gathercole & Baddeley 1993:25). Large individual differences in capacity are found in childhood: 10% of a group of three year olds had a digit span of four, whereas 36% of the group only achieved this span two years later (Baddeley et al. 1998:159). Listening span ability is reported (Siegel 1994, cited by Gathercole 1999:411) to increase steeply until the age of sixteen, in contrast to other memory abilities in which developmental increases flatten off at about 11-12 years (Gathercole 1999:411).
The second element to consider about WM limitation is that of inter-individual variation, between adults. As Miyake and Shah point out, (1999:464) large WM capacity is adaptive, being positively related to factors such as intelligence and status. In regarding limitation as something to be selected for in evolutionary terms, they seem to have disregarded the deleterious effects that disease, adverse environments, and random impairments necessarily have on WM. There is no selective advantage for low WM: instead, the variation in human WM (like the variation in height or symmetry) is due to disease or adverse environment, which result in individuals being dragged down, to a greater or lesser degree, from the optimum (Bruce Charlton, pers. com., 28th August 2002). It is also probable that variations in working memory are genetic in origin. It has been reported that more than half of the individual differences in adult IQ test performance are due to genetic factors (de Geus et al. 2001:489), and research on twins suggests that individual differences in working memory and general cognitive ability arise from individual variations in frontal lobe functioning, with a significant part of the variance in working memory being due to genetic factors (Wright et al. 2001:54). It is also suggested that the genetic contribution to cognition may not fixed, as new genes appear to be expressed in the course of brain maturation (de Geus et al. 2001:493).
Nevertheless, a number of possible explanations for WM limitation are advanced by Miyake and Shah (1999:464): firstly, to prevent excessive brain activity (that might create positive feedback loops) and to promote focused and coherent processes; secondly, as a result of limitations due to synchronous oscillations (one of the suggestions put forward for tackling the binding problem); or thirdly, to facilitate certain kinds of learning (Miyake & Shah 1999:464-5). They claim (Miyake & Shah 1999:465) that there is evidence that severely restricted WM may be useful in detecting subtle statistical regularities in the environment, and that this ability is crucial to language acquisition. Kareev remarks (1995:268) that, in an environment where some order exists, small samples mean that people (and especially young children) are likely to encounter examples suggesting the presence of that order. Cowan (2001:108) gives the example of a correlation between height and voice pitch being more likely to be noticed in a sample of 4-8 individuals than across a larger sample, so a smaller sample increases the chance that a moderate correlation would be noticed at all. In this way, a limited WM capacity helps to avoid missing a correlation, but gives a higher likelihood of false alarms, although these are refuted by subsequent data (Kareev 1995:267-8). This is widely acknowledged to be the situation in child language acquisition, where the child moves from a subset of the adult language and moves towards the superset (Haegeman 1991:419).
Making an inference places heavy demands on WM, as it requires storing information from previous sentences, while concurrently processing new information, so people with a lower WM capacity not only take longer to process syntactically complex information, but they also have considerably lower accuracy in comprehension (Just & Carpenter 1992:129). People with low WM spans may be doing fundamentally different things from those with high spans, when reading (Daneman & Carpenter 1980:464). There is undeniable variability among individual brains as to the size and location of cortical areas (Brown & Hagoort 1999:8) and individual differences in cognitive performance must be expected as an inevitable concomitant of this. Evidence from electroencephalograms (EEGs) suggests that people who score highly on the WAIS-R test of general cognitive ability were better able to focus and sustain attention during a WM task (Gevins & Smith 2000). EEG results indicated that subjects with high ability developed strategies that made relatively greater use of parietal regions, whereas those with low ability relied more exclusively on frontal regions (Gevins & Smith 2000). Activation of different brain areas have been reported (Raichle 1993:584) for people holding lists of nonwords, depending on whether people’s performances on the task were good (premotor and cingulate) or bad (occipital and cerebellum).
2.3.1 Chunking
Chunking is the process whereby memory is increased by gathering together bits of cognitive or perceptual information into larger units, known as chunks, which are then processed as single units. What constitutes a chunk is fairly elastically defined: as Simon puts it (1974:484) “a chunk of any kind of stimulus material is the quantity that short-term memory will hold five of”. A chunk functions as a single entity, so it is not possible to access relations between items within a chunk, although relations between the chunk and other chunks, or other items, can be accessed (Halford 1998:145).
The mean memory capacity among adults is three to five chunks, with a maximum range of two to six chunks in individuals (Cowan 2001:91,114). By building larger and more enriched chunks, with each chunk holding more information, the amount of information held can be increased, although the number of chunks remains the same. As larger numbers of concepts need to be organised into a single chunk, WM is involved to a greater extent, because all of those concepts must be held simultaneously within WM in order to be grouped together into one chunk (Daneman & Carpenter 1980:464). However, as Daneman and Carpenter point out (1980:464), although the actual process of forming rich chunks imposes a temporary strain on WM, it nevertheless brings a benefit in that having a quantity of concepts recoded as one chunk then reduces the load on WM and releases functional capacity for subsequent processing (Daneman & Carpenter 1980:464). An undergraduate subject was reported to have increased his digit span (presumably forward-span, rather than reverse-span) from under 10 digits to 80 digits, by chunking the numbers into meaningful units (representing foot race times, ages, or dates) and then organising these chunks into a hierarchy (Ericsson et al. 1980, cited by Bock 1987:341). The limit on the number of chunks was still seemingly observed, however, as the subject gathered the digits into groups of three or four digits, and then generally used three groups in his supergroups (Ericsson et al. 1980, cited by Cowan 2001:104).
Daneman and Carpenter propose that the chunks formed by subjects with higher spans will be qualitatively different from, and richer than, those formed by lower span subjects, and that the difference between good and poor performers lies in the efficiency of their processing (Daneman & Carpenter 1980:456, 461, 464-5). Differences in processing efficiency may be attributable to a greater proportion of the available WM capacity being absorbed by slower and less efficient processes (Daneman 1984:368). The time devoted to lower level processes, such as word retrieval, could not then be used for other, higher level, processes (Daneman 1984:371).
2.3.2 Individual variation
There seems to be general agreement (Kintsch et al. 1999:420) that no single all-encompassing factor exists that is responsible for WM capacity limitations. Although computational and architectural limitations (assumed to be universal) may differ across individuals, it appears that individual differences are based on the characteristics of individuals, and may be related to knowledge and skill (Kintsch et al. 1999:421). This proposal ignores disease-related effects, which bring about decreased levels of attention and concentration, as well as effects from brain damage or mental handicap.
Differences in individual WM capacity are thought (Engle, Kane & Tuholski 1999:104, 103) to reflect differential ability in controlled processing, required to maintain goals in the face of interference or distraction. Controlled processing therefore pertains to the functioning of the central executive, rather than the WM system as a whole (Engle, Kane & Tuholski 1999:104).
Individuals are thought to differ in the functioning of the prefrontal cortex, especially the dorsolateral region (BAs 9, 10, and 46), which is the area that is critical to both WM and controlled attention abilities (Engle, Kane & Tuholski 1999:105,116-7). Frontal lobe injury leads to impaired executive control over other cognitive activity, which results , inter alia, in poor abstract thought, reduced skill in problem solving, and a failure to plan ahead or monitor behaviour (McDonald 1998:492). The cognitive deficits associated with frontal lobe damage show up particularly in everyday activities, as carelessness, unreliable judgement, poor adaptability to new situations, and blunted social sensibility (Lezak 1995:91). There is also some evidence that the prefrontal cortex is involved in performance on tasks that reflect gF, general fluid intelligence (Engle, Kane & Tuholski 1999:122). The prefrontal cortex is considered to be critical to both the functioning, and individual differences in WM, controlled attention, and fluid intelligence (Engle, Kane & Tuholski 1999:122).
2.4 Working memory and ageing
Cognitive function declines progressively across the life-span, and this decline is both regular and of considerable magnitude (Park 2000:6). The decline has been shown in tests of speed of processing, WM, and both free- and cued-recall (Park 2000:6). Four mechanisms have been proposed to account for age-related decrements in cognitive functioning, namely speed of processing, WM, inhibitory function, and sensory function (Park 2000:8). Cognitive slowing means that, in a complex cognitive task, older adults may no longer have available to them the products of the earlier stages of processing; while the selection of the most recent among multiple-choice answers is increased by aural presentation in place of written presentation of answers (Park 2000:10-11). Deficits in inhibition have been cited as the reason why older people are more likely to maintain information that is subsequently disconfirmed (Park 2000:15), although Tompkins et al. (1994) found that their subjects without brain damage had no difficulty in revising inferences. Lindenberger and Baltes (1994) (cited by Park 2000:16-7). found that nearly all the variance in a wide range of tests of cognitive ability was accounted for by sensory functioning, as measured by simple tests of visual and auditory acuity, in their study of a large sample of older adults (aged 70-103 years).
Age is reckoned to have a greater effect on nonverbal than verbal intelligence, as exemplified by scores on the Wechsler Adult Intelligence Scale (WAIS), where performance IQ (PIQ) begins to decline around age 50, whereas verbal IQ (VIQ) does not decline until about 60 years (Reuter-Lorenz 2000:97). A possible confounding factor is that PIQ tests demanded inhibition of irrelevant elements in the stimuli, whereas VIQ tests had minimal selective attention requirements, and that both inhibitory processes and selective attention are deemed to depend on prefrontal cortex, which is affected disproportionately by age (Reuter-Lorenz 2000:97). Decreased activation in the left dorsolateral frontal region has been observed in normal ageing (Grady et al. 1995, cited by Cappa 2000:71), and, since this region is implicated in encoding semantic information, it is suggested (Cappa 2000:71) that this could be the neural correlate of defective encoding, and hence age-related memory impairments.
A study by Wingfield et al. measured performance in groups of younger and older adults on a spoken version of the Daneman and Carpenter WM span test, and found that whereas the younger group’s average WM span was 4, the average WM span was only 2.5 in the older group (Wingfield 2000:183). Although it is generally agreed (Grady & Craik 2000:224) that memory performance declines with age, some areas of memory show a greater decline than others. Recognition memory, and short-term memory (tested by Digits Forwards) suffer slight age-related decrements; whereas losses on free- or cued-recall, and WM tasks are substantial (Grady & Craik 2000:224-6). PET imaging studies show that, whereas younger adults have left lateralised prefrontal cortex activity during VIQ tasks, frontal cortex activity in older adults is bilateral (Reuter-Lorenz et al. 2000, cited by Grady & Craik 2000:226). It is suggested (Grady & Craik 2000:226) that this recruitment of frontal cortex in older adults could be compensatory.
2.5 Working memory and social intelligence
Having established some features of WM, the next step is to discuss its relationship with social intelligence.
Baddeley and Logie (1999:28-9) give considerable importance to aspects relevant to social intelligence, in their definition of WM as
“those functional components of cognition that allow humans to comprehend and mentally represent their immediate environment, to retain information about their immediate past experience, to support the acquisition of new knowledge, to solve problems, and to formulate, relate, and act on current goals.”
WM must necessarily play an integral part in manipulating social intelligence information, by permitting the creation and orchestration of complex representations of other individuals and social scenarios. It is argued (Nelson 1990, cited by Naito & Komatsu 1993) that the basic function of memory is to provide guidance for action and to predict what will happen. The definition of intelligence has, similarly, been proposed to be the ability to guess correctly, and the ability to discover unexpected orderliness (Barlow 1983:208). In view of the congruence between these functions, it is to be expected that there will be a relationship between memory and intelligence.
WM, particularly the central executive component, is considered to be highly connected with general fluid intelligence (gF), the ability to solve novel problems and adapt to new situations (Engle, Laughlin, Tuholski & Conway 1999:310, 313). A frequently-cited earlier study (Kyllonen & Christal 1990:426) claims that general reasoning ability and WM capacity are very highly correlated. It should be noted, however, that some of their WM tasks were extremely similar to their reasoning tasks. For example, AB Grammatical Reasoning (a reasoning task) and ABCD Grammatical Reasoning (a WM task) both required subjects to process sentences of the form A precedes B; while both Mathematics Knowledge (a reasoning task) and ABC Numerical Assignment (a WM task) required subjects to solve equations. It should not, therefore, be surprising that the overall WM and reasoning tasks correlated so well, as they seem to have been testing largely the same abilities. Although they claim (Kyllonen & Christal 1990:392) that their WM tasks test both storage and processing, at least one of the tasks (Digit Span) was a recognition, not a recall task; whereas other tasks required subjects first to store information, then to process that stored information. The tasks were therefore successive, rather than simultaneous.
The ability to guess correctly requires the efficient use of all the available information (Barlow 1983:208), and such information will presumably be held and manipulated in WM. A problem arises where the amount of available information is overwhelmingly large: it is at this point that Barlow’s second aspect of intelligence, that of discovering unexpected orderliness, comes into play. The intelligent individual is someone capable of finding meaningful associations in an enormous quantity of data, since this requires knowledge of the associative structure of a body of information (Barlow 1983:209). The task of guessing correctly in the face of insufficient information or completely novel circumstances similarly requires intelligence (Barlow 1983:208-9), although it is to be assumed that any such situations will be internally represented as social intelligence information.
2.6 Summary
This chapter has surveyed what is meant by working memory, and the current model of its functioning. It has discussed long-term working memory, working memory capacity, chunking, and individual variation in ability. The effects of ageing on working memory were reviewed, as was the relationship between working memory and social intelligence.
The theme of social intelligence is pursued in its relationship with language, the topic of the next chapter.
3. Language
This chapter examines firstly the interaction between language and social intelligence, in section 4.1; then that between language and working memory, in section 4.2. Section 4.3 deals with what constitutes complexity in language production. The measurement of complexity is discussed in section 4.4, and this is followed by the argument for individual variation in language, in section 4.5.
3.1 Language and social intelligence
Predication, the sharing of information, has been described as the “core business” of language (Levelt 2000:152). Much, however, hangs on the kind of information that is to be shared. Although, as Levelt points out (2000:151-2), language can be used for exchanging experiences, transmitting skills, and planning joint actions, a more likely scenario is that proposed by Dunbar (1996:123), namely that language evolved as an aspect of social intelligence, for the promulgation of gossip, the exchange of socially relevant information, and the management of reputations.
Language is dependent on two component systems: a social cognition network responsible for lexical acquisition, and a grammatical system responsible for utterance analysis and computation (Locke 1999:380). Locke (1998:191) distinguishes between speaking which conveys information encoded in spoken language, and talking which is sound-making to maintain social cohesion with others. Talking is socially-oriented, and is heavily reliant on support from non-verbal communication (Locke 1998:192). He points out that, although propositional speaking often does occur during talking, it is optional in many circumstances (Locke 1998:192). Children are involved in the social interaction of talking, long before they develop speaking to exchange information, but through talking, they become aware that the activity can be used to communicate thoughts (Locke 1998:192; Locke 1999:378).
From the earliest stage, infants respond to vocal affect, and in this way come to recognise and predict caregivers’ behaviour (Locke 1999:382). There is a clear consequence for survival in the child’s ability to monitor the affect of others who are capable of judging danger, as he becomes increasingly mobile (Locke 1996:256). Later, when he names things, the child demonstrates to others that he knows and can say these names, thereby signalling his claim to personhood and membership of the social group (Locke 1999:383).
Under the Chomskyan paradigm, the principles of language are assumed to be innate and invariant, with the functional category options that instantiate a given language being fixed during the process of language acquisition (Radford 1997:12). Functional categories represent such concepts as definiteness, perfectivity, passivity, habituality, and relationships between elements, all of which may be considered necessary for conveying social intelligence information. It is claimed (Cinque 1999:106-7) that functional categories are represented in adult grammars in a universally invariant order (although any particular language may instantiate only a subset of them). During the process of acquisition, the child has access to only those functional category options relevant to his current stage of development.
The emergence of behavioural patterns is related to the functional maturation of the brain and cycles of myelination (Lecours 1975:121). If the information conveyed by functional categories depends on the representation of body state feedback, the timing of the availability of the functional categories could depend on the myelination of the areas concerned with its cortical representation. This could provide an explanation for the child’s sequential awareness of particular elements of the triggering data during language acquisition.
A young child, even a child with impaired language, needs only one exposure to a new word to acquire its meaning (Dollaghan 1987:220). A young child acquires amazing numbers of new words every day: a two year old knows some two hundred words (Locke 1997:277), but by six, he knows some ten thousand, and by eighteen some sixty thousand (Bloom & Markson 1998:68). Since it is assumed that exposure to a new word evokes an emotional response, subsequently generating a feeling, and dispositional representation, rapid access to emotional responses is required. It is notable that, by three years, the myelination of the subcortex is complete (Thatcher et al. 1987), which would speed up emotional responses. As the somatic marker mechanism is presumed to be associated with the meaning of words and propositions, it is tempting to speculate that somatic markers may constitute Logical Form, the hypothesised interface between the language faculty and the conceptual-intentional system of cognition (Chomsky 1995:2).
When a word is learned, activations pass between the word-formation system (Wernicke’s area) and the motor-control system (Broca’s area), via both the cortical route (arcuate fasciculus), and the subcortical route through the basal ganglia and thalamus (Damasio & Damasio 1992:67). Language processing is thought to involve the parallel operation of both the cortical “associative” and subcortical “habit” systems (Damasio & Damasio 1992:67). This involvement of the basal ganglia implies that word learning is mediated by the SMM, as the connection is formed between the word, the concept, and the body state representation.
The medial temporal circuit, connected with the temporal and parietal lobes, subserves declarative memory (learning and storage of information about facts and events), and probably words as well, since they are also arbitrary. Circuits connecting the basal ganglia and frontal cortex subserve procedural memory (learning and processing of motor, perceptual and cognitive skills) and probably also grammatical rules (Ullman et al. 1997:267). The cross-linguistically identical theta roles associated with a given verb are almost like a mini schema (or cognitive framework), and attest the verb’s original nature in motor activity. When the verb is first enacted as a body state representation, with the relevant agent, theme, goal, etc., the expectation of their presence will be encoded with the representation of verb itself, and will also be accessed when the verb is accessed. It has been noted (Tomasello 2000:156-7) that a child’s earliest words are item-based, organised around a concrete schema, and that semantically similar verbs are used in only one type of sentence frame.
The earliest verbs a child acquires are generally concrete activities (Tomasello 2000:156), which may be assumed to bring about specific body state representations. Verbs that depict mental states are not acquired until appreciably later in development, around 2;6 to 2;10 (Limber 1973:172). Presumably these mental state verbs are interacting with the nascent ToM mechanism, since the child must appreciate that people have mental states before he can speak about those states, since it has been noted (Hoff-Ginsberg 1993:567) that children do not truly attempt to communicate ideas until the age of about three, when they have developed an understanding of the mental states of others.
One class of learning disabilities is in integration, and consists of a deficit in acquiring meaning and symbolic significance (Johnson & Myklebust 1967:21). This class of problems is exemplified in echolalia (when the speaker repeats what he hears) and word-calling (when the word-caller identifies the word he sees in print), yet in neither case is any meaning associated with the words (Johnson & Myklebust 1967:21). It is possible that these individuals have a diminished, or damaged, somatic marker mechanism, and are consequently unable to form the connection between a word and their own body state feedback which would allow them to impute meaning to the word.
The relation between word and meaning is also lost or damaged in people with Wernicke’s aphasia, or transcortical sensory aphasia, who have damage to the left parietal lobe. Such people produce many paraphasias (real words, perhaps related in meaning to the target word, but perhaps apparently randomly selected) and neologisms (possible, but non-occurring, “words” ), as well as an increased number of indefinite terms (something, this, here). There is also a frequent occurrence of semantic paraphasias after subcortical damage (Lesser 1990:406). People with semantic dementia (associated with focal temporal lobe atrophy) have a profound, progressive, and often precipitous, loss of semantic knowledge, affecting not only language but also object recognition and factual knowledge (Hodges et al. 1992:1798,1803).
3.2 Language and working memory
Working memory is a necessary prerequisite for processing syntax, in both comprehension and production (Hagoort et al. 1999:277). Parsing principles in language comprehension suggest (Kimball 1973:40) that, although semantically the unit of perception is the sentence, syntactically the unit of perception is the phrase. What was then called short-term memory (STM) holds a chunk (defined as a node and all its immediate constituents (Kimball 1973:38)) until it has been parsed syntactically; whereupon the chunk is removed from STM, and is available only to semantic processing.
As the length of working memory is presumed to be approximately 1 to 2 seconds (Baddeley 1986:93), and speech to be delivered at the rate of two to three words per second (Levelt 1999:112), it may be seen that the number of words that would be expected to be held in working memory corresponds closely to Miller’s magical number of seven plus or minus two (Miller 1956). The number of unrelated words that can be remembered is, indeed, approximately six (Baddeley & Hitch 2000:134).
However, it is well-known that speech is packaged into tone units (also known as intonation units, or information units) that indicate which elements belong together in an utterance (Leech & Svartvik 1994:18,194). Each tone unit averages some four or five words, contains a stress nucleus, and represents a separate piece of information, e.g. |the man told us |we could park |at the railway station | (Leech & Svartvik 1994:18,194). It is common for the speaker to lengthen the word immediately before a clause boundary, and to pause for a beat (perhaps about 250 msec) between clauses (Wingfield & Stine-Morrow 2000:363). Evidence from event-related potential (ERP) recordings suggests that the detection of intonational boundaries is very important in speech perception, and that listeners adjust their syntactic strategies according to prosodic cues (Van Petten & Bloom 1999:104). It must be assumed that this form of chunking allows the listener to process a number of tone units consecutively.
Meaning plays a large part in determining how much can be remembered, and the average adult is able to recall sentences of 24 or 25 syllables correctly (Lezak 1995:364). Indeed, memory span for sentences is approximately 16 words (Baddeley & Hitch 2000:134), and the final sentence in the Sentence Repetition subtest in the Multilingual Aphasia Examination (Benton & Hamsher 1989), consists of 18 words comprising 24 syllables, viz: The members of the committee have agreed to hold their meeting on the first Tuesday of every month. Cases have been reported where a person has a very short span for unrelated words, but a relatively well preserved recall of meaningful sentences (Lezak 1995:364). The implication of this is that the presence of meaning seems to mobilise additional memory mechanisms in support of the phonological loop.
3.2.1 Memory in language comprehension
Working memory has long been thought to play a role in reading comprehension, influencing in particular the retrieval of facts, and the computation of anaphoric pronominal reference (Daneman & Carpenter 1980:450). Subjects’ performances on the reading span test and listening span test were shown to correlate significantly with their ability to answer factual questions about a short passage of text, and to compute the referent of an anaphoric pronoun in the passage (Daneman & Carpenter 1980:455-6, 459). It should, however, be noted that this is an epiphenomenon of text and reading, in that, in almost all spoken interactions, the hearer would be able to question the speaker about the identity of the referent, were it not clear.
Working memory is implicated in the reading of “garden path” sentences, where the initial interpretation [baU] has to be revised in the light of following material (e.g. The violinist took a bow. … It had been propped on the music stand) (Daneman 1984:375). It should be noted firstly, that such sentences are extremely unlikely in speech, because either pronunciation or prosody will disambiguate them; and secondly, that they may be peculiar to English, since a more inflected language would not have the necessary homographs.
The creation of inferences also is sensitive to working memory differences. Daneman (1984:376-7) found that high span subjects were significantly more able than low span subjects to integrate clues spread throughout a 25-page detective story, and to name the perpetrator correctly. The necessity to store information, and then use it in order to parse, disambiguate, and integrate subsequent text, taxes both the storage and processing functions of working memory which compete for limited capacity resources (Daneman & Carpenter 1980:450-1). In spoken interaction, however, the hearer can simply ask for information if he fails to understand the speaker.
Processing embeddings makes demands on working memory, the classic example being an object-trace relative clause (often referred to as a centre-embedded relative) such as The reporteri that the senator attacked ti admitted the error (Just & Carpenter 1992:128). The greater difficulty of an object-trace over a subject-trace relative (e.g. The reporteri thati attacked the senator admitted the error) has been explained as being because the same element (reporter) functions as both subject and object (Just & Carpenter 1992:129). In linguistic terms, in an object-trace relative, the head of the chain is further from the foot and must cross more nodes than is the case in a subject-trace relative, under the Chomskyan paradigm. Reading time experiments show that performance on comprehension of object-trace relatives is slower in subjects with low spans than in those with high spans (Just & Carpenter 1992:130).
3.2.2 Memory in language production
There is general agreement on a broad outline of the production process (Bock & Levelt 1994:945). This proceeds in a top-down fashion, from the speaker’s intended meaning at the message level; through the functional level, where lexical selection and the assignment of syntactic functions occur; to the positional level, where the constituents are assembled in an ordered set of word slots and morphological slots; and down to the phonological level, where phonological segments and prosody are encoded, ready for the output systems (Bock & Levelt 1994:945-6). Language production is assumed to be incremental, allowing limited parallel processing to occur across stages, with higher levels delivering information concerning only part of the element under construction piecemeal to levels lower in the hierarchy, before the whole representation of that element is complete at the higher level (Berndt 2001:379).
In order to plan and organise output, information must be retrieved from long term memory, and integrated in real-time with other information passing through working memory (Olson 1973:156). Message generation is therefore dependent on working memory function, and is thought (Barch & Berenbaum 1997:409) to demand more capacity than other aspects of language production. Among the long term memory items that must be held activated are general world knowledge, and knowledge about lemmas, which are representations of semantic and syntactic information. Limited capacity buffers, specific to each level of processing, maintain representations of knowledge activated from the long term store (Martin & Freedman 2001:264). There is an obvious conflict between the top-down manner in which processing from message to output (described above) is assumed to occur, and the bottom-up approach assumed as the syntactic tree is constructed by successive applications of the operation Merge, in the Minimalist Program paradigm. It is proposed (Martin & Freedman 2001:278) that syntactic planning is incremental, with a buffer to retain clause fragments as they are planned, so that they can be integrated with the structure of earlier fragments to create a syntactically coherent whole.
Evidence from speech errors indicates that, although the words involved in most word exchange errors originate in the same clause, some 20% come from adjoining clauses, and hence it is assumed that no more than two clauses can be planned at once (Garrett 1980, cited in Bock & Levelt 1994:967). However, as Bock and Levelt point out (1994:971) speakers rarely know precisely how their sentences will end before they begin them. Indeed, there is evidence from reaction time studies (Ford & Holmes 1978:42,47) that speakers plan a subsequent clause during the end of the previous clause, and that each clause is independently formulated into its surface form as the sentence is being produced. Clearly there is a difference between a matrix clause and an embedded clause, in the length of activation required. A matrix clause, by definition, is that in which other clauses are embedded, and consequently it must be held in working memory until the end of the utterance, whereas, in many cases, the representation of an embedded clause can be terminated as soon as the clause is uttered.
In producing an utterance, a speaker must undertake a considerable amount of parallel processing, simultaneously formulating several elements at different levels. As Levelt points out (1999:112) there is no more complex cognitive-motor activity than speaking, since it requires the speaker to co-ordinate his semantic, syntactic, and phonological systems, while at the same time he must also monitor the content, grammaticality, and articulation of what he has produced. Not only must the speaker correct his articulatory and grammatical errors, but he must also take into account the needs of the listener.
Conforming to the Gricean conversational maxims of quantity, quality, relation, and manner (Grice 1975) requires that the speaker should supply any necessary background information, and monitor the listener’s comprehension, making repairs when they are needed. The generalised requirement of relevance necessitates that the speaker should keep activated in working memory the topic he is addressing, and adhere to it. The maintenance of cohesion and coherence across a conversational turn requires shifts of the speaker’s attention between the ongoing string and previous utterances (Thomas & Fraser 1994:589). Clearly the speaker must also obey the discourse requirements of his culture, observing such things as politeness formulae, which will be observed consciously, and therefore demand attentional resources, although it is likely that the production of variants that are sociolinguistic markers will be below the level of consciousness (Wardhaugh 2002:206), and should therefore not create additional demands on attention.
3.3 Complexity in language production
This section surveys those elements which are acquired very late in childhood or adolescence, which are particularly susceptible to damage in cases of aphasia, and which create particular problems for people with known language disorders or disabilities.
Whereas some groups have no particular problems with working memory, such as those with Specific Language Impairment (SLI) (Fletcher 1999:350), other groups have lower than normal adult working memory capacity. For example, this is the case in childhood, where WM capacity typically increases two- or three-fold between the ages of 4 and 14 (Gathercole 1999:410), as span on a Digits Forward task increases from 2 or 3 at four years, to about 7 at fourteen years (Gathercole & Baddeley 1993:25).
Working memory deficiencies are also evident in people with mental retardation, who have problems in developing strategies for chunking information, so they have to recall unrelated bits of information, which quickly overloads their memory capacity (Owens 1989:119-120). As IQ falls, information processing becomes slower, and problems with language, especially in production, increase (Hulme & Mackenzie 1992:13-14). The language development of people with Down’s syndrome often ceases at the age of 12, with a Mean Length of Utterance of about 3 (Hoff 2001:343), and they rarely progress beyond the simple phrase structures of a typical two year old (Pennington & Bennetto 1998:87). Most people with Down’s syndrome fail to acquire knowledge of sentential embedding, or of how to use complex questions (Tager-Flusberg 1999:319). There is, however, tremendous variability in linguistic function within and across subgroups of mental retardation, and people whose morphosyntax is comparatively spared have relatively intact verbal working memory whereas only those who have digit span of four or more achieve complex syntax (Fowler 1998:311,314-5).
It is assumed that the elements which are late-acquired, easily damaged, or problematic for these groups represent loci of conceptual and/or computational complexity in language production. The following sections (4.3.1 to 4.3.3) discuss such evidence concerning those elements, the optional Complementiser Phrases, adverbs and adverbials, and modifier phrases (attributive adjectives), which are considered to exemplify both syntactic complexity and relevance to social intelligence.
3.3.1 Optional Complementiser Phrases
The term optional Complementiser Phrase (hereafter CP) is used to refer both to relative clauses, and to those clauses introduced by a subordinating conjunction which function as adjuncts but not as complements of the verb. These clauses are represented in a syntactic tree as being headed by a CP element.
Relative clauses require syntactic movement, and chain formation, consequently incurring computational costs, and the difficulties that nested embeddings resulting from relative clauses present in both production and comprehension have long been noted (Limber 1973:183). Even in adult speech, complete and grammatical utterances containing nested embeddings are much less frequent than might be expected, and a variety of devices is used instead, including recapitulation of elements, insertion of a coreferent pronoun in the relative clause, and anacoluthon (the breaking off of one clause, to start another) (Limber 1973:183).
The ability to produce relative clauses develops throughout childhood, and the expansion of relatives to include modification of objects rather than subjects, and centre-embedded clauses are signs of mature written varieties (Scott 1988a:54-5).
In child language acquisition, the order in which the subordinating conjunctions emerge appears to be partly related to the difficulty of the concepts they encode (Bowerman 1979:287), and, in adult language, syntactic complexity may, to at least some extent, represent the complexity of the relations between the concepts expressed (Barch & Berenbaum 1997:408). It is inherently low-frequency structures that indicate growth of complexity (Scott 1988a:58). High-frequency subordinating conjunctions are when and because, which together account for some 75% of all adverbial clauses produced by 9 to 19 year olds; mid-frequency subordinating conjunctions are if and so (that); while although, as, even if, provided that, and unless are low-frequency subordinating conjunctions (Scott 1988b:70-1). The low-frequency items are regarded as being sensitive indicators of syntactic development in adolescence (Scott 1988b:71), and an 11 year old whose subordinating conjunctions are still limited to because, if, and when, would have a subtle linguistic impairment, as he is unable to exploit the full range of language (Scott 1988a:58).
People with language learning disabilities (LLD) have problems in receptive language in dealing with terms expressing spatial or temporal relations e.g. before, after, and first (Montgomery 1992:518). Relational terms such as before and after also present great problems to people with various forms of mental retardation (Fowler 1998:302).
Subordinating conjunctions such as although, unless, until, because have been reported to be difficult for people with LLD to comprehend, possibly because of the subtlety of the relations they encode (Montgomery 1992:518). They may possibly also present difficulties because of the additional memory and attention load of maintaining both the main and the subordinate clauses in working memory until the end of the utterance.
People with schizophrenia have been reported to use fewer clausal and sentential connectives (Thomas et al. 1990:207) and to use fewer embedded clauses than do control subjects (Morice & Ingram 1982:15).
It therefore seems plausible to include optional CPs among those elements that constitute complexity and represent social information.
3.3.2 Adverbs and adverbials
Adverbs and adverbials may occur as adjuncts giving additional information (e.g. seldom, yesterday, in the rain), disjuncts providing a comment (e.g. fortunately, perhaps), or conjuncts connecting to the context (e.g. therefore, on the contrary). People with language learning disabilities have problems with the productive use of such terms as yet, after all, nevertheless (Montgomery 1992:523), which exemplify each of these three kinds.
Only a few conjunct adverbs (anyway, now, so, then, though) occur in the speech of children up to 12 years, but more seemingly develop during adolescence, as adults use three times as many conjuncts (Scott 1988a:55-6).
Children with SLI have problems in producing adverbials in the form of Prepositional Phrases (PPs) (Gavin et al. 1993:200,204), avoiding them with both transitive and intransitive verbs (Fletcher 1999:361), and adverbials expressing time are particularly difficult for such children (Fletcher 1990:448). It has been noted that children with SLI produce significantly fewer adverbial predicates than do normal children, and that they are less likely to give information indicative of time, place, manner, or quantity (Johnston & Kamhi 1984:75,78).
Adverbs and adverbials are also considered to be instances of complexity, and to give socially related information.
3.3.3 Modifier phrases
Attributive adjectives are the form of modifier phrase that appears to give most trouble. People with reduced memory spans have been shown to have difficulty in both producing phrases containing attributive adjectives (e.g. AN green leaf, AAN small green leaf) whereas they can produce the same content predicatively (e.g. the leaf is green, the leaf is small and green) (Martin & Freedman 2001:269). It is noteworthy that the control subjects did not perform at ceiling levels, producing only 90% correct AN phrases and 70% correct AAN phrases (Martin & Freedman 2001:270).
The lack of internal elaboration in noun phrases, by way of attributive adjectives and prepositional phrases, has been noted in the speech produced by people with and without agrammatism, and with both fluent and nonfluent aphasias (Berndt 2001:390). A cross-linguistic study of agrammatic speakers of Swedish, French, German, Polish and English found that subjects could produce under 40% of AN structures and only 25% of AAN structures, and that there was a tendency to produce attributive adjectives postnominally, regardless of whether that was legal in the speaker’s language (Ahlsen et al. 1996:549,553-4,557).
Children with SLI also have difficulty in producing noun phrases (NPs) containing one or two attributive adjectives (Gavin et al. 1993:200), and the investigator has personally witnessed a class of 8 and 9 year olds with SLI struggling to produce an utterance of the form there’s a red frog on your hand.
Attributive adjectives are also plausible examples of syntactic complexity and social intelligence information.
3.4 Measuring complexity
A major difficulty in investigating language complexity in production lies not only in defining precisely what the term complexity means, but also how it should be measured. This is taken up in section 4.4.2 to section 4.4.13, where measures of complexity used in a number of earlier studies are discussed.
The preponderance of research into language complexity has been in the field of comprehension, where testing is methodologically simpler. Typically the investigator provides a stimulus containing the phenomenon under investigation, and then asks the subject a question about that stimulus (e.g. Baddeley et al. 1985; Daneman & Carpenter 1980).
The computation of anaphoric reference over varying distances has been shown to correspond to performance on a reading span test (Daneman & Carpenter 1980:456). This was tested by having the subject read a story and then answer a question about the referent. An example of this is a passage (Daneman & Carpenter 1980:455) about a meeting of jungle animals, which concludes …The proceedings were delayed because the leopard had not shown up yet. There was much speculation as to the reasons for the midnight alarm. Finally he arrived and the meeting could commence. The probe question tested the subject’s ability to name the referent of the pronoun in the final sentence by asking Who finally arrived? The number of sentences between the pronoun and its referent varied in the different passages used. The advantage of the stimulus-question sort of test is that it produces a limited number of simple answers that are either right or wrong, and are consequently easy to score.
Another sort of stimulus used in comprehension tests is a sentence containing a centre-embedded relative clause, which may be either subject-trace e.g. The reporter that attacked the senator admitted the error, or object-trace e.g. The reporter that the senator attacked admitted the error (examples from Just & Carpenter 1992:130). A number of different studies have shown that object-trace relative clauses are more difficult to process, for example by requiring increased reading times (Just & Carpenter 1992:129-130). In comprehension studies, where a limited number of possibilities are presented to the subject, the scoring will necessarily be more straightforward than where the subject could present an almost infinite variety of possible responses, as is the case in studies of production.
The elements claimed to instantiate complexity in language comprehension (anaphoric reference, ambiguous or garden path sentences, and subject- or object-trace relative clauses) are essentially syntactic phenomena, and hence it is at the level of syntax that a correlation between complexity and working memory has been demonstrated by previous researchers (e.g. Baddeley et al. 1985; Daneman & Carpenter 1980). For this reason, this study was confined to complexity instantiated in syntactic elements, and no analysis at semantic or pragmatic levels was attempted.
3.4.1 Existing analyses of complex language
Several methods already exist for describing and analysing language complexity at a syntactic level, and are reported below: however, none was considered suitable for use in the present study. Some of these analyses were intended to be purely theoretical (and/or solely to describe complexity in comprehension), and many were intended for use only with a circumscribed section of the population (young children, people with aphasia, or people with learning disabilities).
In all the analyses outlined below, the data are divided into sentences, utterances, or Text Units: these latter are described as “minimal domains of utterance organisation” (Edwards et al. 1993:218). It should be noted that the construal of what constitutes any of these units must necessarily be at least partly subjective, where the criterion is prosody, grammaticality, or completeness of a thought. Analyses based on such units may be dependent either on the length of a unit (for counts of the number of Xs per unit) or on underlying assumptions about what makes unit A more complex than unit B (Cheung & Kemper 1992:56). This latter may again introduce subjectivity.
Where an analysis is dependent on the length of unit (be it sentence, utterance, or text unit) much will hinge on the precise rules for what counts as a unit: for example, what happens about co-ordination within, versus of, IP? Clearly, longer units are more likely than shorter units to contain more of the elements counted as complex. Where an analysis makes assumptions that some constituents are more complex than others, this hierarchy may be motivated by developmental chronology (as is the case in Developmental Sentence Scoring (section 4.4.5), Index of Productive Syntax (4.4.6), and Developmental Level (4.4.8)) or by purely theoretical considerations (as with Yngve depth (4.4.2) and Frazier depth (4.4.3)). The former are reliant on the validity of the acquisition data and the analysis imposed upon that data: the latter, if not validated empirically, are dependent on the validity of the theoretical framework.
Another problem with breaking down the data into units for analysis is that, given the nature of spontaneous speech, many units will contain mazes (exact, amended, or elaborated repetitions), or will be ungrammatical or incomplete. If an analysis looks only at complete and grammatical units, much of the data will necessarily be discarded. It has been shown that stuttering occurs more frequently with verbs of higher valency, and in utterances of greater length and/or complexity (Yaruss 1999:338,343), and it is likely that longer and/or more complex utterances present more of a challenge to working memory, and hence will be more likely to contain mazes, or to be ungrammatical or abandoned when incomplete. If these units are discarded, much useful and relevant data will be lost. The listener, after all, does still hear and process the entirety of the speaker’s output: not simply those parts that are deemed complete and grammatical. What, then, is the motivation for discarding large portions of the data from the analysis?
Analyses intended for use on language from young children will concentrate on the elements relevant to acquisition (e.g. the presence of functional categories, or absence of agreement errors): these analyses cannot be expected to be suitable for describing data from normal adults, where such elements are assumed. Similarly, an analysis (such as Developmental Level (4.4.8)) intended to describe the language of people with learning difficulties, where subordinate clauses are rare, is liable grossly to understate the complexity of normal speech, if its highest level of achievement is “more than one use of sentence combining in a given sentence” (Rosenberg & Abbeduto 1987:26), since this should be frequent in normal speech, and therefore warrants a further level of analysis (such as examination of the kinds of elements that are combined).
Analyses intended for use with language produced by people with various forms of aphasia (Quantitative Analysis of Agrammatic Production (section 4.4.10), Shewan Spontaneous Language Analysis (4.4.11), and Reading Aphasia Project (4.4.12)) pay attention to elements which are assumed in normal language production, such as the absence of agreement errors and the presence of verbal auxiliaries. Because these analyses are intended for therapeutic use, problem elements are also logged, such as the absence of verbal complements, and the presence of paraphasias, or of prosodic irregularities. These elements are not relevant to language production by normal subjects.
Existing analyses of complex language are outlined in the following sub-sections (4.4.2 to 4.4.13). None of these existing measures captures the essence of complexity as a manifestation of social intelligence, as it is conceived in this study.
3.4.2 Yngve depth
Working in the theoretical framework of the mechanical translation of languages, Yngve (1960) produced a model of sentence production and a hypothesis of a depth limitation in language, based on the amount of temporary storage necessary to produce a string, in terms of those constituents planned but not yet articulated. The calculation of depth requires the construction of a syntactic tree (based on the model of syntax current at the time) whose branches are numbered from the right, and whose terminal nodes are numbered according to the sum of numbers on the branches leading to them. Any form of leftward branching increases the Yngve depth, for example, when [[[[[very] clearly] projected] pictures] appeared] they applauded has a maximal depth of 5, at the terminal node very (Yngve 1960:455). Branching to the right, however, requires only a minimum of storage (Yngve 1960:451). The model of syntactic structure used by Yngve has been superseded, but inflated depths would be produced by employing more recent developments such as X-bar notation (Cheung & Kemper 1992:59).
The analysis is predicated upon the division of the data into sentences, which, in itself, is problematic. The depth metric, based on the amount of temporary memory needed to produce that sentence (Yngve 1960:450) is therefore necessarily affected by sentence length. This would be a particular problem if a co-ordinated clause introduced by and were to be counted as a continuation of a sentence, as this would inflate the Yngve depth by 1 for each co-ordination added (Cheung & Kemper 1992:59).
The scoring, since it requires a syntactic tree for every utterance, is very time consuming, and would be impractical for a large corpus. It is also not clear how mazes should be treated, as the examples given in Yngve’s paper are of idealised data. The analysis was intended only as a theoretical exploration of syntactic phenomena (such as the preference for binary branching, and the tendency for “heavy” constituents to come at the end of a sentence), and was not validated empirically on speech data.
3.4.3 Frazier depth
Frazier’s measure originated in research on natural language processing, and her aim (1985:129) was to produce a general metric focusing on syntactic complexity in sentence comprehension. The claim is that complexity correlates with the amount of superstructure that must be assigned to words, and can be computed over groups of three words, with S and S-bar nodes assigned higher values than nonterminals (Frazier 1985:156,159,163), although the reasons for the three word window and the differential values are based on intuition (Frazier 1985:159,163), rather than empirical observation. Complexity is determined by dividing the number of nonterminals in the sentence by the number of terminals (Frazier 1985:156). Complexity lies in the number of nodes that must be hypothesised, in order for the current chunk of words to be properly attached to the existing structure, and hence the amount of complexity varies across a sentence (Karttunen & Zwicky 1985:14).
Computation of the Frazier depth means that a syntactic tree must be constructed for every utterance, and, requiring complexity counts for each three-word window, scoring is both laborious and impractical. There is a preference for ternary branching (Frazier 1985:156) which is at odds with current linguistic theory, and some subjectivity in the higher values assigned to S and S-bar nodes (Frazier 1985:163) both of which make the analysis of somewhat dubious value. The analysis was intended as a purely theoretical construct, aimed at explaining comprehension phenomena, and was not validated empirically.
3.4.4 Mean Length of Utterance
Mean Length of Utterance (MLU) is a straightforward measure of the mean number of words produced per utterance, although a similar measure counting the mean number of morphemes per utterance (Brown 1973) is sometimes used in descriptions of early child language. MLU is very easy to compute (total words divided by total utterances), but has the disadvantage of requiring the specification of precisely what constitutes an utterance, which is by no means self-evident. Whether such elements as sentence fragments, rephrasings of a previous utterance, or fillers are counted as utterances makes a large difference to the computed measure.
MLU as a measure has minimal usefulness in early child language acquisition and very severe aphasia. It may be considered to give an approximation of grammatical development up to an MLU of 3, but thereafter MLU does not give an accurate estimate of grammatical complexity (Scarborough et al. 1991:41). MLU (in morphemes) was found to be sensitive neither to increases in phrasal complexity beyond an MLU of 2.75, nor to an increase in clausal complexity beyond an MLU of 4.5 (Blake et al. 1993:150). Beyond the three-word stage, the simple length of an utterance is not the same as its complexity, since any of a wide variety of additional elements may be included in the utterance, and the length of an utterance can be prolonged almost indefinitely by the co-ordination of clauses introduced by and. For these reasons, MLU (in either words or morphemes) is irrelevant to the measurement of the complexity of normal adult production.
3.4.5 Developmental Sentence Scoring
Developmental Sentence Scoring (DSS) (Lee & Canter 1971) is based on the developmental order of those elements acquired between 3 and 7 years, and gives weighted scores (of zero up to 8) to pronouns, verbs, negatives, Y/N questions, and Wh-questions. Embedded and other clauses are scored as “secondary verbs” (infinitival complements) or “conjunctions” (a mixture of co-ordinators, and subordinating and co-ordinating conjunctions). Later developing forms score more highly. An additional point per sentence is added if the sentence is completely correct, grammatically (Lee & Canter 1971:320).
The data set is to be elicited in a conversation between a child and an adult, and must consist of a sample of 50 complete sentences (complete meaning the use of at least a noun and a verb in a subject-predicate relationship) (Lee & Canter 1971:317). The final score is the total of the scores for each of the sentences, divided by the number of sentences, and norms are provided for ages between 3 and 7 years. It is intended as a clinical tool for planning language therapy, not as a test of syntactic development (Lee & Canter 1971:335).
The data in the present study were not collected in dyadic conversation, as is required for the DSS. The insistence on complete sentences necessitates firstly, division of the data into sentences (which, as already discussed, is problematic), and secondly, incomplete sentences being discarded from the analysis (causing the loss of a large proportion of the data). Finally, DSS is intended as a descriptive tool with a therapeutic purpose, to highlight a child’s errors and inconsistencies: it is therefore not suitable for the analysis of normal adult language, which is assumed to be free from such problems.
3.4.6 Index of Productive Syntax
The Index of Productive Syntax (IPSyn) (Scarborough 1990) is intended to analyse the language of pre-school children, aged 2 to 4 years, based on 100 successive utterances (excluding imitations, self-repetitions, and routines) recorded during play sessions with a parent (Scarborough 1990:3). IPSyn provides a checklist of 56 structures: noun phrases, verb phrases, questions and negations, and sentence structures, in developmental sequences. Up to two tokens of each of the listed structures may be scored, with subsequent occurrences of the structure being disregarded. The total score is the sum of the points scored, but, as is the case with any summation scores, this does not give any indication as to which particular elements are or are not present within a subject’s data. IPSyn’s validity for older children or adults has not been determined (Scarborough 1990:11).
Scarborough suggests (1990:12-3) that the checklist of forms could be expanded, should older pre-schoolers be being assessed, so IPSyn is clearly inadequate as it stands to deal with the language of normal adults.
3.4.7 Complexity Index
The Complexity Index (Hirschman 2000) was devised to quantify the results of a therapeutic intervention used with 9 and 10 year old children with Specific Language Impairment. The aim of the therapy was to use metalinguistic instruction about basic grammatical constituents to increase the complexity of both written and oral language produced by the children with SLI. The data set for each subject consisted of an oral narrative, retelling one of Aesop’s fables (the fox and the crow), and a written story based on a sequence of pictures. The data were divided into sentences, and any incomplete or repeated sentences, in either oral or written stories, were excluded from the analysis.
The Complexity Index (counted separately for the oral and the written data) consists of a subordination ratio (subordinate clauses divided by total number of clauses) added to a phrasal ratio (1/4 of various kinds of phrase divided by total number of clauses). The phrasal ratio was divided by four because there were approximately four times as many phrases as subordinate clauses, which would otherwise have been overwhelmed (Hirschman 2000:259).
This analysis has the disadvantages of dividing the data into sentences (always problematic) and of discarding incomplete sentences, but it could potentially be used to describe normal adult production, since its level of description is sufficiently general. However, some of the categorisations, such as counting the use of a phrasal verb (e.g. come along, fly away) as an instance of complexity, or the restriction of relative clauses to those that modify a noun phrase acting as subject or object (Hirschman 2000:258-9) appear to be linguistically unmotivated.
3.4.8 Developmental Level
Developmental Level (Rosenberg & Abbeduto 1987) was created to describe the complexity of language produced in conversations between a group of seven adults with learning disabilities of unknown etiology. The data were divided into conversational turns (all successive utterances by a speaker until the initiation of speech by another speaker) which were scored for the presence of complex sentences. The scoring method is not specified in detail, but appears to be one point for each sentence at each level.
Developmental Level classifies sentences into seven levels of complexity, based on normal childhood developmental order, concentrating on the presence of co-ordination, relativisation and subordination. For example, Level 1 is an infinitival complement clause; Level 2 is a co-ordinated subject noun phrase or sentence; Level 3 is a relative clause modifying an object noun phrase, or a clause introduced by the complementiser that; and Level 7, the highest level of complexity, is the combination of more than one type of embedding.
Level 7 sentences consist of any combination of constituents drawn from Levels 1 to 6 (but not counted as such), and, even in learning disabled adults, Level 7 was the most frequently used level (Rosenberg & Abbeduto 1987:27). This metric is therefore unlikely to be suitable for normal adult language, as it would underestimate the amount of complexity, since any additional embeddings (i.e. two or more) would remain uncounted.
In addition to the problem of the construal of the data as sentences, some of the descriptions of the grammatical entities do not correspond to the example given, such as a “wh-infinitive clause” exemplified by remember where it is?.
3.4.9 Brief Syntactic Analysis
The Brief Syntactic Analysis (BSA) (Thomas et al. 1996a) was devised to describe the language of people with mental health problems. The original 98-variable analysis (Morice & Ingram 1982) differentiated successfully between people with schizophrenia or mania and normal controls, but required considerable expertise as well as being complicated and time consuming to implement (Thomas & Fraser 1994:591). The BSA was therefore produced as a simplified form, and measures (inter alia) percentages of sentences containing any form of semantic or syntactic error, and numbers of pauses and other dysfluencies, because these elements are of value in discriminating between different groups of patients (Thomas et al. 1996a:334-5).
The elements concerned with complexity, in addition to MLU in words, are the percentage of well formed major sentences (i.e. clauses free from semantic or syntactic errors), the percentage of sentences with no embeddings, the percentage of sentences containing embeddings, the mean number of subordinate clauses in sentences containing subordination, and the mean maximum depth of embedding in sentences containing subordination. Complexity is thus seen to exist solely at the level of clausal embedding, since this appears to be diagnostic, since people with schizophrenia show low complexity in their speech, even in the earliest stages of the condition (Thomas et al. 1996b:338).
In addition to the problem of construal of the data as sentences, no account is taken of any form of complexity other than embedding, yet different forms of embedding are not counted separately. This analysis appears to have little to offer when describing the speech of normal subjects.
3.4.10 Quantitative Analysis of Agrammatic Production
The Quantitative Analysis of Agrammatic Production (Saffran et al. 1989) requires a corpus of only 150 words, and measures the morphological and structural characteristics of language produced by people with agrammatic (nonfluent) aphasia. Data are elicited as a retelling of a fairy story, Cinderella for preference, and the analysis divides the data into utterances, based on syntactic and prosodic boundary markers, after the removal of a variety of nonpropositional elements including perseverations, stereotyped utterances and anything that is subsequently repaired.
Because the analysis is intended to describe the output of people with agrammatism, it concentrates on such aspects as the presence of determiners, the number of auxiliary verbs in a verb phrase, and the well-formedness of sentences (although a “sentence” may contain violations of verbal subcategorisation (Saffran et al. 1989:471)). This level of analysis would be inappropriate for language from normal speakers, since most of the elements it counts are assumed to be present in normal speech (barring occasional speech errors), and there is no differentiation between types of embedding. Other forms of complexity appear to be ignored.
3.4.11 Shewan Spontaneous Language Analysis
The Shewan Spontaneous Language Analysis (SSLA) system (Shewan 1988) was designed to describe language produced by people with different forms of aphasia, and to differentiate their performance form that of normal controls. It takes as its stimulus a picture description task, and measures such elements as speech rate, speech melody, articulatory disturbances, paraphasias (word substitutions and neologisms) and repetitions, in addition to a count of semantic units. The syntactic analysis expresses as percentages relative to the total number of utterances both the number of complex sentences, and the number of morphosyntactic errors (including omitted subjects, verb or determiners). The analysis divides the data into utterances, on the basis of content, intonation and pausing (Shewan 1988:124), and this number is used as the denominator for calculating the frequency of other elements, such as errors and paraphasias.
The SSLA would not be appropriate to describe the output of normal speakers, since it includes very many elements that are irrelevant to normal adult production, such as melody and articulation (both judged subjectively). A complex sentence is defined as containing a main clause and one or more dependent clauses, but no account is taken of any additional subordinate clauses, of the type of subordination, or, indeed, of any form of complexity other than embedding.
3.4.12 Reading Aphasia Project
The aims of the Reading Aphasia Project were to produce a method for analysing speech, to compile profiles of aphasic production features, and to compare these profiles with those of normal controls (Edwards & Knott 1994:55). The analysis is based on Text Units (TUs), which may be lexical, phrasal or clausal, and the links between TUs, called Immediate Grammatical Relations (IGRs), which include subordination, relativisation, ellipsis, and co-ordination (Edwards et al. 1993:219). The analysis also logs problem units, which include units that are incomplete or that contain unintelligible elements, stereotypic expressions, repetitions and paraphasias (Edwards & Knott 1994:56).
The division of the data into different types of TU is clearly clinically useful, to detect changes over time or after therapy, but, in describing normal adult production, would be unnecessary and even unhelpful. The fact that the TU can consist of such a variety of elements means that dissimilar elements are being compared. The analysis is intended to provide information about the grammatical limitations of its subjects (Edwards 1995:336), which is irrelevant to normal production.
3.4.13 Mean Clauses per Utterance
Mean Clauses per Utterance (MCU) (Kemper et al. 1989) is based on three samples of language, two oral and one written. The oral material is elicited by standard questions on employment history and current activities, and by asking subjects to speak about the person they most admire. The written data is about the most significant event experienced by the subject. As the name suggests, MCU divides the data into utterances, and counts the mean number of clauses per utterance: main, subordinate and embedded. A wide ranging mixture of elements is included (Kemper et al. 1989:53) under the heading of utterances: sentences, sentence fragments, additions to previous utterances, and both lexical and non-lexical fillers. Some of these (particularly the fillers) will clearly not contain clauses, so the baseline number of utterances, and hence the computed measure, will be affected by the precise criteria for the definition of a separate utterance. The precise definition of what constitutes a clause is also important, since when non-finite forms are included as clauses, the measure is greatly affected. A terminological distinction is made (Kemper et al. 1989:53) between a subordinate clause (inflected for tense, and introduced by a subordinating conjunction) and an embedded clause (including relative clauses, wh-clauses, clauses introduced by a complementiser, and non-finite complements), which seems pointless, because both types are subsequently counted together.
MCU was intended for use with language from elderly normal adult populations, and has been shown to correlate positively with both Digits Forward and Digits Backward (Kemper et al. 1989:60), although Digits Forward is not considered to be a working memory task. The heterogeneity of the definition of clauses is unhelpful (since it is likely that complement clauses will predominate), and any computation over utterances must be suspect, because of the subjectivity involved in construing an utterance.
3.4.14 Summary of existing analyses
For a variety of reasons, none of the existing methods is suitable for analysing complexity in normal adult language production. Some analyses were intended solely as theoretical explorations, without any operational use or empirical validity, and were therefore purely dependent on the validity of the theoretical framework. Other analyses were intended for use only on language produced by very young children, or by adults with aphasia, mental illness, or learning disability. Although these analyses were empirically tested on their relevant populations, it is not to be expected that they should also be applicable to language from normal adults. Many of the analyses ignore any form of complexity other than at the clausal level, and all require the division of the data into sentences, utterances, or other units as the basis for analysis.
The essence of complexity, as it is conceived in this study, lies in its connection with social intelligence, and with working memory. Social intelligence information is conveyed by means of complex language, to demonstrate an individual’s understanding of the social milieu, and to make possible the potential manipulation of others’ beliefs and behaviour. Working memory forms a constraint generally on social intelligence understanding and computation, and, more particularly, on the production of complex language.
The following section deals with some of the sources of differences between individuals in language ability. These same factors will necessarily also lead to inter-individual differences in working memory.
3.5 Sources of individual differences in language
Linguistics is concerned with the steady state (Ss) of competence (knowledge of his language) attained by the ideal speaker-hearer in a homogeneous language community (Chomsky 1965:3-4), with the implicit assumption that all individuals speaking the same language share a linguistic competence. There are many performance phenomena, such as illness, fatigue, or intoxication, which could affect an individual’s language abilities on a fluctuating basis, yet there are also potential sources of permanent differences between individuals in their linguistic ability. Chomsky, speaking in a debate (reported in Piatelli-Palmarini 1980:175) notes that the steady state attained may well be different between people of different educational levels, and that he considers a correlation between linguistic performance and intelligence to be likely.
Fillmore suggests (1979:88) a difference in competence, in that individuals vary according to how well and how successfully they manage their native language across a number of dimensions, and that this variation forms a continuum with children at one end, and what he calls “the speech-impaired" at the other. Fillmore points out (1979:88,91,95) that some informants have greater metalinguistic awareness than do others, and that speakers may vary in their ability to acquire the language of the community, in their knowledge of the processes necessary for creating new expressions, and in their active mastery over such processes
This sounds not dissimilar from the picture presented by children with language learning disability (LLD), who experience problems with comprehension, production, or both, that become less obvious and less detectable during adolescence (Montgomery 1992:513-4). Children with LLD have been shown to have deficits in all aspects of short term memory, in encoding, storage and retrieval strategies: they also have word finding difficulties which result in frequent hesitations and substitutions in their speech (Montgomery 1992:515-6). Such children are also noted for their inferior metalinguistic abilities, especially in detecting syntactic and morphological errors; and for being deficient at monitoring their own comprehension in order to assess whether or not they understand something (Montgomery 1992:516). Particular problems occur when children with LLD are required to do parallel processing, attending to several dimensions simultaneously (Montgomery 1992:517), which is required for thinking about a topic and producing an answer concurrently.
The most obvious sources of differences in language ability, attributable to an individual’s age, sex, and idiosyncratic brain configuration, are surveyed below.
3.5.1 Age differences
The loss of neurons is one of the consequences of the ageing process, and is associated with a diminution in the capacity for sending nerve impulses and an increase in reflex times (Tortora & Grabowski 1996:423). It is therefore to be expected that processing times will be longer in older people. Age-related deterioration across a wide range of tasks have been variously attributed to working memory capacity reductions, to slowing of processing, or to a deficit in inhibition allowing unwanted tasks to take up resources, although these explanations are not mutually exclusive (Wingfield & Stine-Morrow 2000:374).
Elderly people (with no neurological damage) have been reported (Thompson 1988) to have greater difficulty in understanding inference, anomaly and ambiguity, and to use fewer embedded sentences, more pronouns than nouns, and a greater range of indefinite words. The tip-of-the-tongue phenomenon occurs increasingly with age, although the decrease in ability in confrontation naming is slight until the age of about 70 (Wingfield & Stine-Morrow 2000:374). Elderly adults tend to pause for longer, and use more indefinite words (e.g. thing) where a specific word would be more appropriate (Wingfield & Stine-Morrow 2000:375).
The incidence of left-branching embeddings decreased with increasing age in a study of written and spoken language by Kemper et al. (1989), although right-branching clauses were not affected. It is claimed (Kemper 1988:73) that this decrement is a result of working memory limitations, since left-branching structures impose higher demands than do right-branching clauses. Elderly adults also have difficulty computing anaphoric reference over larger distances (Wingfield & Stine-Morrow 2000:379).
3.5.2 Sex differences
Differences, brought about by prenatal hormonal manipulation, between the brains and behaviours of male and female animals have been well documented (Kandel et al. 1995:586-90). The existence and nature of sex differences in human brains, are, however the matter of some debate, with different studies producing contradictory results.
The pattern of cerebral asymmetry is arguably different in males and females, with differences between the sexes in the rate of maturation of cognitive functions in the two hemispheres leading to greater hemispheric specialisation at an earlier age in males (Kandel et al. 1995:590). Left cerebral dominance for language has been reported to be more pronounced in men than in women (Beatty 1995:375), and the splenium (the caudal part of the corpus callosum, the large bundle of axons linking left and right hemispheres) has been shown to be larger in women than in men, suggesting there are more fibres connecting the posterior parts of the female brain (Beatty 1995:379-80). Kimura (1992:86) notes that, following damage to the front of the brain, women are more likely than men to suffer from aphasia, implying a difference between males and females in brain organisation, with language being represented more anteriorly in females. During stimulation mapping for object naming tasks, women were found to have essential language sites only in the frontal lobes (Ojemann 1991:2284).
It is likely that the effect of sex hormones during the brain’s development brings about the organisational differences between male and female brains, and that these same mechanisms also produce variation within each sex (Kimura 1992:87).
3.5.3 Anatomical differences
There is undeniable variability among individual brains as to the size and location of cortical areas (Brown & Hagoort 1999:8) and individual differences in cognitive performance must be expected as an inevitable concomitant of this. The variability in the lateralisation of language, together with the variable anatomy of the speech areas of the brain means that similar lesions may have different effects on the language of one person compared with that of another (Kertesz 1993:655-6). There is tremendous variation between individuals in the gross anatomy of the brain, not only in its size and weight, but also in the configuration of sulci and gyri. It is well known among neuroanantomists that the primary sulci (which form earliest during pregnancy) are relatively constant; the secondary sulci (which form late in pregnancy) are more variable; and the tertiary sulci (which form in the final few weeks of pregnancy and after birth) are extremely mutable (Jacobson 1991:448). Even the major landmarks, the central sulcus (or Rolandic fissure) and the lateral sulcus (or Sylvian fissure) which appear at 14 and 20 weeks of gestation, respectively (Chi et al. 1977:87,90) are subject to considerable variation (Whitaker & Selnes 1976:845).
Large variations also exist between individuals in cytoarchitecture (the organisation of cells within the characteristic laminar pattern), and it has been noted that sulci and gyri correspond fairly well with the boundaries of cytoarchitectural fields, giving rise to striking individual differences (Whitaker & Selnes 1976:845-6). Even more variable than brain size, weight, cytoarchitecture and convolutional patterns, is the blood supply of the brain, with the arteries and veins varying in their location, number and branching patterns (Whitaker & Selnes 1976:848-9).
Some variability is of genetic origin, but some results from viral or other infections, since there are regional differences in brain growth and the brain is most vulnerable during periods of fast growth (Casaer 1993:52-3). As Whitaker and Selnes remark (1976:846) “each person’s brain may be as individual as his physiognomy”.
Imaging studies, using a variety of techniques, have shown that language centres are neither homogeneous nor confined to the classical areas of the perisylvian cortex, but instead consist of nonadjacent focal areas, which include the temporal pole, the lingual and fusiform gyri, dorsolateral prefrontal cortex and the insula (Neville & Bavelier 1998:254). There is remarkable variability in the functional organisation of language in the brain, with a system for a given language function including both essential areas (in frontal and temporoparietal regions) and widely dispersed neuronal activity elsewhere in the cortex, all activated in parallel (Ojemann 1991:2281-3). Considerable variation also exists in the location of the essential areas. In subjects undergoing stimulation mapping for object naming, no frontal perisylvian essential areas could be identified in 15%, and no temporoparietal essential areas in 17% (Ojemann 1991:2284).
Striking neural reorganisation and plasticity characterise the language system during its development, and its final organisation reflects its experience-dependent status (Neville & Bavelier 1998:265-6). The creation of tertiary sulci appears to continue throughout adult life (Stuss 1992:13) and the myelination of some frontal and association areas continues well into adult life (Yakovlev & Lecours 1967:5,64). Once an axon becomes myelinated, conduction velocity increases dramatically (from about 2 metres per second to about 50 metres per second (Casaer 1993:55)) but it can no longer conduct many different kinds of stimuli, becoming restricted to stimuli with specific characteristics (Yakovlev & Lecours 1967:68). The interest in myelination lies in identifying which areas in the brain are interacting so intensively that they require signalling pathways with fast conduction velocities, at what age they do so (Casaer 1993:56), and hence the myelination of an area demonstrates the parallel between anatomical and behavioural maturation (Lecours 1975:121). The protracted nature of myelination in those areas most concerned with the comprehension and production of abstract language has been noted (Lecours 1975:125,132,134) and continues throughout adulthood.
During stimulation mapping tests for object naming and reading, different patterns of language areas were observed, depending on whether subjects had higher or lower verbal IQs, thus demonstrating a relationship between the organisation of language cortex and language abilities (Ojemann 1991:2284). It is likely, therefore, that the substantial individual variation in cortical language organisation underlies some individual differences in verbal abilities (Ojemann 1991:2286).
3.6 Summary
This chapter looked at the relationship of language with both social intelligence and working memory. It discussed the instantiation of complexity in language production, and examined previous methods of analysing language complexity. The final section outlined various sources of differences in ability.
The following chapter summarises the background of the present study, and sets out its aims and intentions.
4. The current investigation
Previous studies of working memory and complex language (e.g. Baddeley et al. 1985; Daneman & Carpenter 1980) have concentrated on ability to deal with complexity in language comprehension, often only in the written modality. In such research, the elements considered to represent complexity included anaphoric reference, garden path sentences, inference creation, and object-trace relative clauses. Studies measuring language complexity during the course of language acquisition (e.g. Lee & Canter 1971; Scarborough 1990) have viewed complexity as comprising the elements that arise incrementally in the normal developmental sequence, whereas those measuring language production in people with aphasia (e.g. Saffran et al. 1989; Shewan 1988) have been concerned with evaluation to guide therapeutic intervention, rather than the production of complexity per se. Research on language production in groups of people with mental health problems, particularly schizophrenia (e.g. Hymowitz & Spohn 1980; Morice & Ingram 1982) has examined complexity, defined only in terms of the presence of subordinate clauses.
None of these studies has examined the relationship between working memory ability and the production of language complexity. In none of the previous research has the evolutionary significance of complex language been addressed, and in none has the definition of complexity been considered from an evolutionary standpoint. This study proposes that language is an aspect of social intelligence, that language production is constrained by working memory, and that language complexity is the means of displaying working memory ability. Complex language therefore constitutes an honest signal of genetic fitness.
In an environment principally composed of one’s conspecifics, the individual who best understands the workings of the social group, and can manipulate it to his own ends, will be at an advantage (Bradshaw 1997:163). Within a social group, keeping track of those who repay favours, and those who cheat is essential, and remembering others’ reputations becomes crucial (Ridley 1996:69-70). In such a situation, the number, and especially the intricacy, of mental representations that can be held in mind and manipulated simultaneously will be of critical importance to the success of an individual within the social group. These mental manipulations are clearly dependent on working memory.
Memory makes it possible to cope with a complex but structured world, where the past can be used to predict the future (Baddeley 2000b:292), and it is working memory that provides the interface between memory and cognition (Baddeley 2000b:292). Working memory provides a computational space where old and new information can be maintained temporarily in an activated form while it is manipulated (Gordon 1997:307). That working memory ability varies between individuals has been demonstrated in numerous studies of working memory and language comprehension (e.g. Baddeley et al. 1985; Daneman & Carpenter 1980). Such previous research has shown that a correlation exists between working memory capacity and ability in the comprehension of language described as complex.
This study assumes that there is also variation between individuals in the ability to produce complex language. (This is implicit in the measures of complexity surveyed in the preceding chapter.) It is hypothesised that an individual will speak as complexly as he is able, with lower complexity being attributable to working memory constraints.
The current investigation compares ability in the production of complex language with performance on tests of working memory. It is proposed that complex language production is constrained by working memory ability, and hence that a relationship is to be expected between working memory and the production of language complexity. The production of complex language can, in this way, advertise an individual’s prowess in working memory. The elements that constitute complexity in language production are the same elements that instantiate information relevant to social intelligence, and thus social intelligence can also be demonstrated by complex language.
The aims of this study are:
· to devise an improved method for measuring working memory
· to devise a methodology for eliciting, recording, and categorising complex language
· to devise a precise and objective method of measuring language complexity
· to measure the continuum of ability in the production of complex language
· to examine the relationship between working memory and complexity in language production.
Working memory is measured on two tests: one a standard neuropsychological test (the Story recall subtest of the Adult Memory and Information Processing Battery); and the other a newly-devised version of the working memory span task, in the aural modality, the Aural Working Memory Span test. These tests are amalgamated to constitute the Combined Memory Score, an internally consistent measure which offers greater precision in the measurement of working memory.
A test interview, which includes the working memory tests, is formulated as the stimulus to elicit spontaneous speech. Methods are devised for the transcription and analysis of the complex language data generated by the test interview.
The Index of Language Complexity, formulated on the basis of evolutionary and linguistic theory, and evidence from both language acquisition and disorders, provides an objective measure of complexity in language production. The Index of Language Complexity is used to demonstrate and measure the continuum of ability in the production of complex language.
The relationship between working memory and the production of complex language is examined, measured, and found to be significantly correlated. The analysis and measures generated in study 1 (the pilot study) are subsequently tested separately, in study 2 (the replication study), on a larger independent data set, where the correlation is reproduced between working memory and the production of complex language.
The next chapter forms part of the introduction to study 1, and describes the development of the test interview.
5. Study 1: introduction: test
The overall aim of study 1 was to measure individual variation in the ability to produce complexity in spontaneous speech, and to establish whether there was a relationship with WM abilities. The first necessity therefore was to devise a test format which would elicit samples of speech suitable for measuring complexity and incorporate tests of working memory.
Study 1 was used as a pilot to ascertain what would constitute a viable test of language complexity, and to establish a workable method for the collection and transcription of the spontaneous language generated in response to the test materials.
The second purpose of study 1 was to refine the concept of complexity, based on theoretically principled reasons, and to devise criteria for categorising complex spontaneous language in a quantifiable yet simple manner.
The following chapter describes the development of the categorisation process, while the categorisation method is detailed in the study 1 method chapter.
This chapter describes the development of the test format. The first section concerns general characteristics of test stimuli, while section 6.2 deals with the subtests which were tried out and retained; and section 6.3 sets out those subtests which were tried but eventually rejected.
5.1 Elicitation stimuli
The kind of stimulus used to elicit spontaneous speech from the participant greatly alters the characteristics of that speech. Most studies of children’s language are based on dyadic interactions during free play sessions; whereas studies of language from people with aphasia tend to use either questions about the person’s aphasia-inducing trauma (Edwards 1995), or a re-telling of a fairy story (Saffran et al. 1989). Language from people with mental health problems may be from semi-structured interviews (Barch & Berenbaum 1997:405), conversations (Thomas et al. 1996b:339), or free-topic narratives (Morice & Ingram 1982:14). Studies of language from elderly people have used interviews on former employment and current activities, and expositions on the person they most admire (Kemper et al. 1989:52), or story telling (Kemper 1992).
Interviews may be unstructured (when the interviewer’s questions depend on the nature of the subject’s responses), semi-structured (when the interviewer has a schedule of topics, with some freedom in how to follow up responses), or structured (when the interviewer follows a schedule containing all the questions to be asked) (Pawlik 2000:381). The interview used in this study is structured in format, since every subject was asked all the questions.
It is clear that any conversation or dyadic interaction will place on the participant turn-taking and conversational repair demands that are not present in narrative, story telling or re-telling tasks. A structured interview may be presumed to be intermediate between these tasks, as it requires the participant to monitor the need for repairs possibly more actively than during a narrative, but not does not impose the turn-taking and turn-holding pressures of true conversation. The use of the same set of stimuli for all participants should minimise any differences between individuals that could be due to topic variation.
5.2 Test formulation
Since one of the purposes of study 1 was as a pilot, to establish what would constitute a workable test interview, the format of the test was amended during the course of the study. The original version of the test included Serial Subtraction, NART, Picture Description, Cognitive Estimates, the long version of What & Why, and the short version of Speculation. (See below for a description of these tasks). Sentence Repetition was subsequently added briefly but removed, while Nonword Sentence Repetition was tried only informally. The amendments were made both in the light of subjects’ performances and/or feedback, and as a result of informally trying out new questions or subtests on people who had already done the test, and were available for subsequent consultation. The subtests which were tried out, but were eventually excluded from the test, are described in section 6.3.
In its final state, the interview as a whole comprised three tests of memory (Digits Backward, AMIPB Story Recall, and Aural Working Memory Span) interspersed with three langage tasks (What & Why, Story Telling, and Speculation). The memory tests were intended to measure the subjects’ working memory abilities, while the language tasks were sets of stimuli to elicit spontaneous speech which would later be analysed and quantified. With the exception of the visual stimulus for the Story Telling task, all the tests were entirely oral in nature, both in the administration and in the subject’s response.
5.2.1 Linguistic variation
Any analysis of language should consider the influence of a range of speaker variables which have been demonstrated to produce systematic variation across a speech community (Mesthrie 1994:4900). Such speaker variables include social class, ethnicity, age, and gender (Milroy 1987:94). It is also necessary to bear mind the effect of situational factors, such as participant, topic and setting (Milroy 1987:182), since these can bring about stylistic variation within the ideolect of a speaker (Bell 1984). The potential impact of these sources of variation is discussed individually below, since their effects needed to be considered when formulating the test stimuli.
5.2.1.1 Social class
The notion of social class is not well-defined (Milroy 1987:99), and, where social class is treated as a sociolinguistic variable, it should be regarded as a proxy for distinctions in life-style, attitude, belief, wealth, power, and prestige (Milroy 1987:101). Social class (however defined) has been shown to have a differential effect on the production of phonological variables, and the degree to which non-standard forms of language may be used (e.g.Chambers & Trudgill 1980). However, the present study is not concerned with the level of phonology, and there is no a priori reason to expect that non-standard forms should be any less complex than standard variants.
5.2.1.2 Ethnicity
Ethnicity, which is taken to refer to the sense of “macro-group ‘belongingness’” (Fishman, J.A. 1997:329), is often associated with expression of a particular social identity, although it is not always marked by linguistic distinctiveness (Milroy 1987:103). Perhaps the best known effects of ethnicity on language are to be seen in the many studies of Black English (e.g.Labov 1972), which describe the various linguistic features to be encountered in that variety. However, no indication is given of different levels of syntactic complexity (as defined in this study) being produced by people of differing ethnicities. There was no a priori reason, therefore, to make ethnic group membership a criterion for subject selection, although the requirement that participants should be native speakers of British English assumes that they have a British cultural identity.
5.2.1.3 Age
Where the production of a linguistic variable varies across age, it may point to ongoing change within a speech community (Romaine 1994:80), and the influence of age as a sociolinguistic variable may also be reported in tandem with social class, gender, or style as groups of speakers produce different phonological variants (e.g.Chambers & Trudgill 1980:91-4). It is known that the full range of syntactic competence is not available until late adolescence (e.g.Scott 1988b), and advanced age has been demonstrated to affect the comprehension of anaphors (Wingfield & Stine-Morrow 2000) and of inference (Thompson 1988), and the production of embeddings of all levels (Cheung & Kemper 1992).
It is therefore to be expected that age will demonstrate an impact on linguistic complexity, and the effects of age are investigated within the present study, with both lower and upper age limits being included in the criteria for recruitment of subjects.
5.2.1.4 Gender
The effect of gender on the differential use of phonological variants is well documented (e.g.Chambers & Trudgill 1980:71-4), and a variety of other manifestations of different language use in males versus females has been reported. Many of these differences are at the level of pragmatics, dealing, for example, with interactional strategies (Fishman, P.M. 1997), or the tendency to interrupt (McCormick 1994:1357). This pragmatic level is not the concern of the current study.
It has been claimed (McCormick 1994:1357) that males and females talk about different topics, that females discuss their feelings more, and that males talk for longer stretches than females. The subjects in the present study are all presented with the same stimuli, so no choice of topic is available to them when answering questions, with only a circumscribed choice for the storytelling task. The possibility of females discussing their feelings more, or of males talking for longer does not constitute a problem, since the aim of the interview is to elicit spontaneous language, and no time limit is put on answers.
It has been reported (Lakoff 1973; cited by Wardhaugh 2002:316-7) that women have a particular range of adjectives (e.g. aquamarine, exquisite) which are only rarely used by men. It appears that the sets of adjectives used by males versus females are different: however, it does not appear to be suggested that women use adjectives in contexts where men do not do so.
5.2.1.5 Situational factors
Variation in a speaker’s style is his accommodative response to his audience, primarily his addressee (Bell 1984:145). Casual speech in a linguistic interview may be considered to be an analogue of spontaneous everyday conversation (Bell 1984:150), yet a speaker nonetheless shifts his style in response to his interlocutor, seeking to match or approach the hearer’s speech characteristics (Bell 1984:158-9), in an attempt to modify his persona to accommodate to the addressee (Giles & Powesland 1997:233). Such convergence with (or divergence from) the speech characteristics of the interviewer would not be expected differentially to affect the complexity of the spontaneous language produced by the participants, since all subjects are exposed to the same interview stimuli, delivered by the same interviewer.
Bell claims (1984:161) that audience variables have more effect than non-personal variables such as topic and setting. Different topics may bring about a style shift, with the implication that, for example, the topic of education causes a speaker to use a style that echoes the way he would talk to a teacher (Bell 1997:247). Since every participant is asked to talk about every topic, any possible variations in style should be evenly spread. The use of routines, wherein a subject reproduces a set of practised elements, should be obviated by the novelty of the stimuli.
The setting for linguistic interviews is, in the Labovian paradigm, kept as informal as possible, in attempt to minimise any status differences between the interviewer and the participant (Mesthrie 1994:4903), since these could lead to a more formal style being adopted by the speaker. Labov notes (2001:104) that casual speech is essential for obtaining optimal information on the distribution of word classes, as this is most clearly demonstrated in the vernacular. In the present study, an attempt is made throughout to maintain an empathetic and informal approach, in order to diminish the situational strangeness inevitably engendered by the interview format.
5.2.1.6 Syntactic variation
A major source of variability in usage is at the level of syntax, because, as Milroy (1987:144) points out, “there is no simple isomorphic relation between function and form”. However, although many alternative means of expression are available to the speaker, they are not necessarily semantically neutral or functionally equivalent (Mesthrie 1994:4907). Since it is hypothesised within the present study that people produce as much complexity as they are capable of, on every possible occasion and in every possible environment, it is assumed that the choice to produce a less complex form will be the result of working memory constraints. The analysis is concerned not with the presence of any specific individual variant, but rather with the presence of the class of optional elements which arise late in the process of acquisition and create difficulties in various forms of language disorder.
It may happen that there is accommodation towards the standard language used by the interviewer, as observed by Cheshire (c1988:16-7), but there is no a priori reason to assume that dialectal or non-standard syntactic variants should be any less complex (as defined by this study) than the equivalent standard usage.
5.2.2 Test description
The tests are described below: first the three language tasks, then the three memory tasks. The test stimuli discussed here are given in the Appendix.
5.2.3 What & Why
This test is used as a stimulus to elicit complex language, and consists of ten open-ended questions concerning general world knowledge, which are administered orally, and to which the subject replies orally. The questions are posed sequentially, with the second following on the end of the subject’s reply to the first, and so on. What & Why is broadly similar to the Comprehension subtest of the WAIS (Wechsler 1955), except that no account is taken of the semantic content, nor the level of generalisation of the answers. Six of the questions ask why some facet of daily life is the way it is, e.g. Why do footballers earn more than nurses?, and four questions ask what a well-known saying means.
The earliest form of the test amalgamated new questions with some questions from the WAIS Comprehension, and some from the WISC-R S children’s test (Wechsler intelligence scale for children: revised: Scottish standardization (WISC-R S) ca.1987). Examples of the questions were Why do we need child employment legislation? (rephrased from WAIS), and Why should people not pick wild flowers?. The idea was that the subject should not have ready-prepared answers, but rather have both to think and speak at the same time. The intention had been that the topics chosen would stimulate a variety of adverbial clauses in the replies, but a number of the questions, e.g. Why should people pay their taxes? produced only narrow and prosaic answers, and were therefore dropped from the test. The questions were reduced in number and the topics refined, such that only those that encouraged more complex language remained. In the final version, two questions came from WISC-R, one from WAIS, and three were new.
The test included questions asking subjects to explain the meaning of proverbs, firstly because it is quite a demanding task to produce an explicit explanation, and secondly as a means of evoking metaphorical language. It has been noted (Lezak 1995:603) that proverbs were commonly used in conversation two or three generations ago, and hence elderly people can often provide an immediate and unthinking definition for the more familiar proverbs. However, perhaps since the teaching of metaphors is not so prominent in the educational system as it used to be, the proverbs proved difficult for younger subjects, who tended, therefore, to give only the immediate, concrete explanation, because they did not know the abstract, figurative meaning. As an example, an 18 year old subject, unfamiliar with the saying strike while the iron’s hot, gave the explanation if your iron’s cold, it won’t get the creases out of your clothes. It is the unfamiliarity of proverbs, rather than their abstractness, that makes them difficult to interpret (Lezak 1995:603). The four proverbs chosen for inclusion in the final version of this test were consequently very well-known, and were recognised by the majority of the subjects.
5.2.4 Story Telling
There were a number of reasons why it was considered desirable to include a story telling task. Firstly, asking the subject to tell a story is a relatively non-threatening examination method; secondly, pictures are valuable stimuli for eliciting habitual speech patterns; and thirdly, story telling is a particularly rich test medium, since it shows the subject’s ability to organise and maintain ideas, while also providing information on lexical choice, grammaticality, and syntactic ability (Lezak 1995: 774-5, 543). In addition, story telling may reveal subtle deficits in expressive abilities that are not apparent in less demanding tasks (Lezak 1995:537).
Another reason for the inclusion of a story telling task was that chronological versus non-chronological (logical) organisation of subject matter is considered to be one of the major determinants of syntactic structure (Scott 1988b:77). It was to be expected that, in answering the stimulus questions, the subject would adopt the non-chronological or logical organisation that is suited to explanations, whereas story telling specifically entails a chronological approach. The main requirement for narrative is sequentiality, and a minimal narrative may be defined as a sequence of two temporally ordered clauses (Georgakopoulou & Goutsos 1997:59).
5.2.4.1 Narrative structure
A seminal definition of narrative, widely used as a basic framework for study (Linde 1992:25) is as “a method of recapitulating past experience by matching a verbal sequence of clauses to the sequence of events” (Labov 1972:359-60). It must be recalled that Labov‘s study was based on narratives produced by black adolescents in response to a question asking whether they had ever been in a fight with someone bigger than themselves, the so-called “danger of death” question (Labov 1972:354). The narratives thus elicited were necessarily first-person accounts of actual events, and were of undoubted emotional salience for the speaker. In contrast, the narratives elicited in the present study are created around the character(s) in the picture stimuli, and are therefore third-person, imaginary, and of no affective significance for the speaker. A further confounding factor lies in the ages of the subjects. Labov’s speakers were young adolescents (aged 10 to 16 years), who might be assumed not yet to have completed the final stages of language acquisition which lead to mastery of stylistic registers and complex syntax (Scott 1988a, 1988b). Indeed, Labov comments (1972:394) that the preadolescents have some way to go in their ability to use language for the purposes of narrative, as opposed to its use in ordinary conversation. The subjects in the present study, by contrast, are older, and may be expected to have achieved full language competence, and therefore have a fuller range of expression available to them (other cognitive demands permitting).
The normal form of a narrative of personal experience is set out by Labov and Waletzky (1967:32-41), and amended by Labov (1972). Some speakers may provide an abstract, in the form of one or two clauses summarising the story and encapsulating its point (Labov 1972:363). It may be assumed that the appearance of an abstract would be more likely when a personal anecdote is being recounted (and could therefore be drawn, in its entirety, from memory) than when, as in the present study, a story is being fabricated piecemeal on the spur of the moment. The abstract also serves to establish the speaker’s right to the floor in a conversational setting (Gülich & Quasthoff 1985:180), whereas in the present study, there is no turn taking requirement. Preceding the first narrative clause comes an orientation section, which serves to familiarise the listener with the person, place, time and behavioural situation of the story. This section is characteristic of most narratives, but is reported (Labov & Waletzky 1967:32) to be typically lacking in narratives of children and “less verbal adults”. The complication section follows, and depicts the series of events that comprise the complicating action of the story. This, however, is not sufficient to indicate to the listener the importance of the events, nor to distinguish the complication from the resolution (Labov & Waletzky 1967:34).
At this point the evaluation section is introduced to state the ensuing result, and to emphasise its importance (Labov & Waletzky 1967:34-5). The evaluation delineates the (often self-justificatory or self-aggrandising) attitude of the narrator (Labov & Waletzky 1967:37), and may be returned to more than once during the narrative, in repeated cycles (Labov 1972:369). Such evaluation sections are described as being typical of narratives of personal experience (Labov & Waletzky 1967:34) where they uphold the claim to reportability: the story’s point and raison d’être (Labov 1972:366). The criterion of reportability means that that completely ordinary and anticipatable events cannot be made into a narrative (Linde 1992:25). Evaluations are, however, lacking from narratives of vicarious experience (Labov & Waletzky 1967:34), exemplified by the retelling of an episode from a television programme (Labov 1972:367). Since subjects in the present study are specifically asked to tell a story in the form of the plot of a film, there is no requirement on them to demonstrate reportability, and avoid the “so what?” factor, which was so imperative for Labov’s subjects in their personal narratives (Labov 1972:366). Indeed, subsequent experience in the present study showed that a number of stories were mundane, and, if not strictly archetypal, could certainly be considered to be adhering to an established cognitive script or schema. The resolution section of a narrative, revealing the result or resolving action, comes after the evaluation, and may be followed by a coda, which functions as a device for returning the verbal perspective to the present (Labov & Waletzky 1967:39).
Personal narratives are concerned with the presentation of self: who the speaker is, what he has done, and how he is to be perceived by the listener (Linde 1992:26). As such, narratives include major life events considered central to the creation of personal meaning, and the coherent formation of such stories is a task that requires individual creativity (Linde 1992:26). Considerable variation is observed (Labov & Waletzky 1967:40) in the degree of complexity, number of structural elements, and means of performing the various functions within a narrative. Labov and Waletzky point out (1967:41) that the simplest possible narrative would consist of a single line of complication with no resolution, and that it is the evaluative function that requires the transformation of a simple A-then-B relationship into the more complex form of a personal narrative. It is also noted (Labov & Waletzky 1967:41) that a story is re-shaped by many re-tellings: this element of pre-formed and practised narration is avoided in the present study by presenting novel stimuli, in preference to eliciting previous personal experience.
5.2.4.2 Language in narrative
Certain characteristics of narratives have been reported. These include the frequent appearance of direct speech (especially as a replay of the narrator’s own utterances), the repetition of the same content in either the same or different form, and the atomisation of the event continuum where the speaker goes into inordinate detail (Gülich & Quasthoff 1985:187-8). The most striking feature of narratives, however, is the fundamental simplicity of their syntax, which contrasts sharply with the much more complex structure of ordinary conversation (Labov 1972:377).
The simple auxiliary structure of narrative contrasts with the rich variety of auxiliaries and modals found in conversation, and when futures and modals do occur in narratives, it is in the evaluation section (Labov 1972: 377-8, 381). Tense is generally thought to be deictic, in expressing the relationship between the time of the occurrence of an event, event time (ET), and speech time (ST) which is the time of speaking about it (Wales 1986:425). Aspect is not seen as deictic, because it is concerned with the internal structure of the situation (Wales 1986:425). In data from older children, it has been noted that perfective events are generally described using past tense, with imperfective events portrayed through progressives (Wales 1986:426). Progressives indicate that an event is happening simultaneously with another, and sometimes two present participial forms are concatenated (e.g. I was sitting waiting) to set the scene for the narrative as a whole, or to suspend the action during the evaluation (Labov 1972:387-8).
The third temporal concept, reference time (RT), is concerned with an identified temporal context which may express the relationship ‘simultaneous with’, ‘prior to’, or ‘subsequent to’ (Weist 1986). The development of the RT system occurs in two stages, with the earlier stage of restricted RT happening around the age of three years (Weist 1986:367). This stage is characterised by the onset of temporal adverbs, and such early adverbial clauses as those introduced by when (Weist 1986:367). The second stage, the free RT system, is present in children of about four years, and is characterised by the presence of clauses introduced by before and after (Weist 1986:367-8). The restricted RT system is sufficient for the appearance of the simple past tense, which expresses the configuration ‘RT simultaneous with ET, both prior to ST’ (Weist 1986:369-70). The preferred tense for narration is the historic present, particularly in introducing direct speech (Gülich & Quasthoff 1985:188), and the simple past tense is used to convey the temporal ordering of events (Linde 1992:24).
During the evaluation, subordinate clauses may appear (Labov 1972:390). Some of these embeddings are introduced by the complementiser that: such clauses are treated in this study as representing part of the subcategorisation frame of the verb. This sort of embedding on verbs of saying and knowing is universal and automatic among all speakers (Labov 1972:390-1). Subordinate clauses may function as qualification, being introduced by such conjunctions as while or though: alternatively they may be causal, being introduced by since or because (Labov 1972:390). Such clauses are treated as optional CPs in this study.
Double attributive adjectives e.g. big red house are reported to occur rarely, and even single attributive adjectives are uncommon in subject position, although the principal antagonist may warrant complex description to justify the narrative’s claim to reportability (Labov 1972:389-90). The canonical form of the basic narrative clause (Labov 1972:376) indicates slots following the complement(s) where it is expected that manner, instrumental, locative and temporal adverbials will appear. Labov comments (1972:376) that locative adverbials occur particularly frequently in narratives.
Dysfunctional aspects of narratives are also reported (Labov 1972:392) such as confusion of persons, anaphora and temporal relations. It is assumed in the present study that such problems result from constraints on working memory.
5.2.4.3 Story telling stimuli
Although story telling tests exist, the existing stimulus pictures were considered to be of too low a quality to use, since they comprise small, and frequently poorly recognisable, black and white line drawings. It could therefore be argued that tests based on such stimuli would constitute a test more of visual acuity than of story telling ability. Lezak suggests (1995:774) that a test can easily be improvised from magazine illustrations or photographs: the current test utilised just such materials, culled from newspapers and magazines. The pictures chosen were of an ample size (covering half to three-quarters of an A4 page); the majority were in colour; and all depicted one or more people in surroundings suggesting a possible story line. Three other smaller pictures had been used in the early stages of study 1, but were replaced as larger, coloured pictures became available. (Copies of all the picture stimuli are in the Appendix.)
Description of stimulus picture
colour
used
woman and baby orang utan, looking at each other
colour
x
man and woman, looking tense and despairing
monochrome
x
two men in conversation, in the street
monochrome
x
girl and boy, in the back seat of a car
colour
ü
man and baby, in a room strewn with tools
colour
ü
three mud-spattered cyclists, in the countryside
colour
ü
small boy crying, with bullies in the background
colour
ü
two men in conversation, drinking coffee
monochrome
ü
woman in an airport or station arrival/departure hall
colour
ü
Table 6-1 List of pictures used as stimuli for Story Telling
The subject was asked to pretend that the illustration represented a scene from a cinema film, and to tell the story of what had led up to that scene, what was currently going on, and the likely outcome. The structure, length and level of detail in the story was entirely up to the subject.
5.2.5 Speculation
As with What & Why, this test, which is also designed to stimulate the production of complex language, is presented orally, and sequentially. The subject was asked to speculate about a number of topics, based on his own experience and opinions.
Questions ranged from the prosaic How did gardening and cookery programmes on the television come to be so popular? to the unlikely If you won £1 million on the lottery, how would it change your life? or impossible If you had to be an animal, which animal would you choose to be?
Such speculation would require the formulation and evaluation of a number of possible alternative answers, and was expected to elicit complex language. The questions were formulated so as to require no knowledge, but to rather provide a springboard for opinions and conjectures.
5.2.6 Digits Forward / Digits Backward
Digits Forward (DF) and Digits Backward (DB) are tests of memory, and consist of orally administered strings of digits, which are to be repeated back orally to the examiner (Lezak 1995:359,366). The strings in DF are repeated in the same order as they were given, whereas in DB the strings are repeated in reverse order. The simpler test, DF, is administered first, and, at the end of it, the subject is given the instructions for DB. An example is given to reinforce the need to reverse the order of the digits, and DB then follows the same procedure as DF. After the instructions have been given to the subject, the examiner reads out, at approximately one per second, a string of digits (e.g. 2, 4, 9), and the subject immediately repeats the string (or what he can remember of it). The strings of digits are of increasing length, and when the subject repeats the string correctly, the next length string is given. If the string is incorrect, a second string of the same length is given. If this second string is correct, the next length string is given; however, if it is incorrect, the test is terminated. The test proceeds until two consecutive errors are made, and the subject’s score is the highest length string he could repeat correctly.
DF measures the subject’s freedom from distractibility (or efficiency of attention), whereas DB is an effortful activity that involves mental double-tracking, since both the memory and reversing operations must be carried out simultaneously (Lezak 1995:359,367). It is generally considered that digit span is governed by working memory, especially the phonological loop (Hodges 1994:111), although it is quite possible that subjects may encode the digits using visualisation techniques or tactile memory in its stead.
This test followed the standard format of DF/DB, adopted by a number of neuropsychological tests (Lezak 1995:357), in that DF consisted of strings from three up to nine digits in length, while the strings in DB were from two to eight digits long. These strings were quasi-random, as they were based on lists, generated in Excel, of random digits (from 1 to 9), but with the constraints that no digit should appear more than once in a string, and that no more than two digits should appear in either a consecutive or a reversed consecutive sequence. A second form of the test was generated at the same time, in case of problems in administering the test, such as dysfluencies in reading out a string, or coughs, sneezes or other interruptions during a string. In such a case, the equivalent string from form 2 of the test was used before reverting to form 1 for the rest of the test.
The normal range for DF is 6 +/- 1, and for DB it is 4-5 (Lezak 1995:358,367), with the normal difference between an individual’s DF and DB scores being one.
5.2.7 AMIPB Story Recall
Working memory was tested by the Adult Memory and Information Processing Battery (AMIPB) Story Recall subtest (Coughlan & Hollows 1985). The AMIPB was developed in response to the need for a battery of tests with specific standardisation data, including information on age, IQ, social class, and academic achievements (Coughlan & Hollows 1985:18), as many of the older batteries have only haphazard norms (Lezak 1995:499). The AMIPB battery test materials are new, although the tests are based on familiar clinical procedures (Coughlan & Hollows 1985:19). The AMIPB was developed comparatively recently in Leeds, and is widely used in neuropsychological testing in the North East of England, in preference to older batteries originating in America. The AMIPB Story Recall subtest was selected because of its recency, because it was developed for use with speakers of British English, and because it has a detailed scoring system.
The AMIPB (form 1) story, which deals with the theft of a woman’s handbag and her subsequent pursuit of the thief, contains twenty-eight units of information, and is analogous to a supraspan test, since more data are presented than can be fully absorbed (Lezak 1995:456). In addition to providing a measure of the contribution of meaning to recall, the story recall task is a more naturalistic medium than smaller speech units (such as word lists, or sentences) for testing memory (Lezak 1995:456).
There is a difference between psychology researchers, who regard the duration of working memory as some 1½ to 2 seconds or up to 10 seconds with rehearsal (Fabbro 1999:94), and neurologists and neuropsychologists who are interested in what they term “immediate memory” which they recognise as lasting in the region of a minute, or possibly even several minutes (Markowitsch 2000:266). Memory on this timescale must be involved in the naturalistic recall of snippets of gossip or jokes, and will also be required for the assessment of cohesion and coherence at the discourse level. The experimenter’s telling the AMIPB story takes approximately 35 to 40 seconds, and the subject’s re-telling (assuming full recall) may be assumed to take the same time or longer, allowing for pauses for thought. The AMIPB task, at some 1 to 2 minutes, therefore taps into the immediate memory timescale, while also constituting a working memory test, by requiring the simultaneous storage and manipulation of information.
The subject is informed that he will be told a story, which he will be asked to tell back again. The story is then read aloud to the subject by the examiner, and the subject immediately retells as much as he can recall of the story. Lezak points out (1995:456-7) that (in a population of neurological patients) few people repeat a story recall test exactly, and that substitutions of synonyms or suitable phrases are generally credited as being correctly recalled. Under the AMIPB scoring scheme, any correctly recalled idea (or an accurate paraphrase thereof) is awarded two points, and any vaguely or partially recalled ideas receive one point. Detailed guidelines with examples of scoring are also given in the AMIPB. For example, for the idea unit and found a boy, a response of youth, lad, teenager, young man would score two points; while thief, intruder, man would score one point. Among normal subjects, those ideas that are recalled are generally presented in the same words as were used in the original telling of the story, and, probably due to the priming of those vocabulary items, very little spontaneous generation of language appears to take place.
The scoring is done later, from the recording of the interview, and the points are then added together to give the subject’s score. In this study, the AMIPB score was converted into a percentage of the possible total score (i.e. 56). This was firstly to allow ease of comparison with scores on the Aural Working Memory Span; and secondly to allow scores on AMIPB Story Recall and on Aural Working Memory Span to be amalgamated into a Combined Memory Score (which represented the average of the two standardised scores).
age group
mean score
SD
18 -75 years
34.3
11.1
18 -30 years
39.2
10.5
31 -45 years
33.0
10.1
46 -60 years
34.1
10.9
61 -75 years
30.7
11.1
Table 6-1 Story Recall norms (form 1) Coughlan and Hollows (1985:56-60)
The AMIPB scores had been standardised on subjects aged from eighteen to seventy-five, and consequently the age-range of the subjects in the present study was covered. The presence of these standardised scores means that not only can a subject’s performance be judged with respect to that of other subjects, but also, should this be desirable, in more finite terms, through the percentiles given in the norms for four different age groups. Coughlan and Hollows note that the percentile markers and cut-off scores become less stringent with increasing age (Coughlan & Hollows 1985:55): this reflects the degradation of working memory across the different age-groups, not merely in the eldest group.
5.2.8 Working Memory Span
The Aural Working Memory Span test used in this study is an oral test, and was developed from the listening span task (Daneman & Carpenter 1980), the working memory span test (Baddeley et al. 1985), and an auditory working memory task for use with older adults and stroke patients (Lehman & Tompkins 1999; Tompkins et al. 1994). In the paradigm established by these tests, sentences are presented orally to the subject in sets. At the end of each sentence, the subject performs a judgement task; and at the end of a set, he recalls the required words. The sets are of increasing length, and the span is a measure of the number of sentence-final words that the subject can recall accurately.
5.2.8.1 Previous studies
In Daneman and Carpenter’s listening span test (1980), the subject had to say whether each sentence was true or false, and at the end of each set of sentences, to recall the final word of each sentence in that set. There were five sets of sentences in each group, and the sentences, of nine to sixteen words in length, having been taken from general knowledge quiz books, were intended to be of moderate difficulty (Daneman & Carpenter 1980:458). Example sentences are You can trace the languages English and German back to the same roots and The Supreme Court of the United States has eleven justices. They remark (Daneman & Carpenter 1980:458) that, since the reading version of the test proved to be so difficult, credit was given for any correctly recalled final words, regardless of the order of recall. The criterion for cessation was not stated for the listening span task, but the reading span task was terminated when a subject failed all the sets of a level.
Baddeley et al. (1985) used as their stimuli simple person-verb-object sentences, half of which were classified as sensible and half as nonsense: these latter sentences were semantically anomalous. Example sentences are The girl sang the water and The policeman ate the apple. The sentences were presented orally, but, since this test was administered to a number of people at the same time, the subjects responded on paper, and were presented with all the test stimuli, rather than stopping at a pre-determined failure criterion. The subject had to judge whether each sentence was sense or nonsense (by ticking a box), and then, according to instruction, recall either the person or object involved in each of the sentences in the set, in the correct order.
Tompkins et al. (1994) used as stimuli simple active declarative sentences based on common knowledge, ending in a one- or two-syllable noun, verb, or adjective. In each group, there were three sets of two, then three, four, and five sentences, presented on a tape recording. Subjects responded verbally with recalled words, and true / false judgements were made by pressing buttons on a response box. Example sentences are Cows like to eat grass and You keep books in ovens, and words could be recalled in any order. No explicit criterion for the cessation of the test was stated, but the existence of such a criterion may be inferred from internal evidence in the papers.
5.2.8.2 Aural Working Memory Span (AWMS)
Following the established paradigm, the Aural Working Memory Span (AWMS) test in this study consisted of statements which are matters of basic world knowledge, and which should be immediately and self-evidently true or false. The target words were selected to be non-culture-specific, and the number of true and false statements was balanced within each set, and each group, as well as over the test version as a whole. The truth / falsity judgement was used, firstly, to ensure that the entire sentence was processed, preventing subjects from simply concentrating on the final word (Daneman & Carpenter 1980:458), and secondly, to serve as a form of Brown-Peterson distraction task, preventing the rehearsal of the material to be remembered (Lezak 1995:432). The truth / falsity judgement had no intrinsic value, although previous researchers have noted that their subjects believe that the truth judgement matters (Daneman & Carpenter 1980:458), and do their best to answer correctly, rather than answering at random to make the memory task easier.
The sentences took the form of simple, short, declarative statements, containing neither negation, which is generally considered to increase the difficulty of processing, nor embedding, which increases syntactic complexity (and would also lead to the verb’s appearing clause-finally in the German version of the test). Statements which are inherently difficult to process (e.g. the day after yesterday is today) were also avoided. It was inevitable that there would be a degree of strangeness in the sentences, partly because it is unusual to state the obvious (e.g. you see with your eyes), and partly because the untrue statements are necessarily semantically anomalous (e.g. penguins drive cars).
The stimuli were presented as groups of three sets of firstly two, then three, then four, then five sentences. Although some previous studies have used more sets per group, it was decided to fix the group size at three sets, to avoid the danger of stimulus overload, wherein the subject becomes confused by too much stimulation (Lezak 1995:443). The criterion for cessation of the test was failure on two consecutive sets: this criterion is commonly used in neuropsychological testing, as, for example, in Digits Forwards and Digits Backwards.
5.2.8.3 Working Memory Span Scoring
The scoring of working memory span tests may reflect either a subject’s performance to a given level, in terms of the size of set whose sentence-final words may be recalled; or a subject’s performance overall, in terms of the total number of sentence-final words correctly recalled. Daneman and Carpenter’s scoring system reflected the highest level of span achieved by a subject; that adopted by Baddeley et al. reflected the subject’s overall correct performance; whereas that of Tompkins et al. combined overall errors on the truth / falsity judgements with those on words recalled.
Daneman and Carpenter’s method yielded a fairly transparent measure of span level achieved. Correct recall of three sets of final words out of the five sets was scored as reaching that span level, while recall of two sets of final words out of the five sets was scored as .5 (on top of the span level below). It should be noted that, because there was no limit on the number of wrong answers a subject could make, there were numerous permutations of correct and incorrect answers at the final level by which a given score could be achieved. For example, the ten permutations resulting in a score of .5 at any level are shown in the columns of the table below.
set
correctly recalled?
1
ü
ü
ü
ü
2
ü
ü
ü
ü
3
ü
ü
ü
ü
4
ü
ü
ü
ü
5
ü
ü
ü
ü
Table 6-2 Ten possible ways of scoring .5
The listening span scores of their undergraduate subjects (n=21) ranged from 2 to 4.5, with a mean of 2.95 (SD .72) (Daneman & Carpenter 1980:460).
Baddeley et al. scored overall performance, counting the total number of items recalled in the correct serial position. They report working memory spans based on two experiments, on subjects aged 18 to 60 (Baddeley et al. 1985:124,127). In the first experiment (n=48), where each group contained four sets of three and four sentences, the mean score was 20 (SD 4) of a maximum score of 28 (Baddeley et al. 1985:124). It would, however, have been possible to score 24 by being correct on only the first three words in the sets of four sentences, as is shown in the table below.
sentence
4 sets of three sentences
sentence
4 sets of four
sentences
1
ü
ü
ü
ü
1
ü
ü
ü
ü
2
ü
ü
ü
ü
2
ü
ü
ü
ü
3
ü
ü
ü
ü
3
ü
ü
ü
ü
4
x
x
x
x
score
3
3
3
3
score
3
3
3
3
cumulative score
3
6
9
12
cumulative score
15
18
21
24
Table 6-3 A possible way to score 24
In their second experiment (n=102), where groups contained five sets of three and four sentences, the mean score was 25.4 (SD 4.9) of a maximum score of 35 (Baddeley et al. 1985:127). In a similar way to that shown in the table above, it would have been possible to score 30 by being correct on only the first three words in the five sets of four sentences. Provided that the subject could give the first three words of every set correctly, he could score 15 at level three, plus a further 15 at level four, giving a cumulative score of 30. This scoring system does not, therefore, truly reflect maximum capacity.
The scoring system adopted by Tompkins et al. counted errors in both word recall and true / false judgements, giving a maximum of forty-two in each, although the true / false errors were so rare that they were not analysed (Tompkins et al. 1994:904). However, it would appear that this error score reflects the number of errors resulting from only those sets attempted, not from the full test, since reference was made (Tompkins et al. 1994:904) to the span levels reached, and to the different numbers of trials for different subjects. In discussing their digit recall tasks (Lehman & Tompkins 1999:776), the researchers stated that they had chosen error scores in order to circumvent the restricted range of scores normally yielded by span scores, and noted that their results for span scores were similar to those for the error scores. For the control group (n=25) of adults from 51 to 77 years of age, the mean score for word recall errors was 6.4 (SD 4.6) (Tompkins et al. 1994:904). This scoring system gives no indication of the maximum span level achieved.
5.2.8.4 Aural Working Memory Span scoring
The scoring system selected for this study was similar to that of Daneman and Carpenter, in that it yielded a transparent span score. Subjects were scored as achieving a span level only when they correctly recalled all three sets in the group. Recall of one set was scored as .3 (on top of the span below); and recall of two sets was scored as .6 (on top of the span below). Therefore, for example, a subject who correctly recalled all three sets at level two, plus one at level three would score 2.3; and a subject who correctly recalled all three sets at level three, plus two at level four would score 3.6.
level 2
level 3
level 4
set 1
set 2
set 3
set 1
set 2
set 3
set 1
set 2
set 3
ü
ü
ü
ü
x
x
test ended
ü
ü
ü
x
ü
x
x
test ended
Table 6-4 The two ways of scoring 2.3
level 3
level 4
level 5
set 1
set 2
set 3
set 1
set 2
set 3
set 1
set 2
set 3
ü
ü
ü
ü
ü
x
x
test ended
ü
ü
ü
ü
x
ü
x
x
ended
ü
ü
ü
x
ü
ü
x
x
ended
Table 6-5 The three ways of scoring 3.6
Since there were three sets in a group, and the test was terminated after the second consecutive failure of a set, there was one possible way of scoring a whole number, two ways of scoring .3, and three ways of scoring .6 (as exemplified in the rows in the tables above). While this is recognised as being anomalous, it is less so than the Daneman and Carpenter scoring system. Rather than performance being split into two possible scores at each level (whole number versus .5), in this study, performance is split into three possible scores (whole number versus .3 versus .6). In this way, the additional level of score offers a means of increasing discrimination between levels of performance.
The Aural Working Memory Span scores were also converted into a percentage (of the maximum possible score of 5), in order to make the scores comparable with those on AMIPB Story Recall, and to permit the two scores to be averaged to create a Combined Memory Score (as averaged z-scores).
5.2.8.5 Aural Working Memory Span: selection of target words
It was important that the sentence-final target words, which were to be held in memory, should be comparable in length, imageability, abstractness, word class, and frequency. For this reason the sentence-final target words were mono- or bi-syllabic, imageable, concrete nouns or adjectives, and of high frequency (i.e. at least five per million in published word frequency lists).
The Kucera and Francis (1967) word frequency list is based on a million-word corpus drawn from American English printed texts published in 1961, while the Hofland and Johansson word frequency list (Hofland & Johansson 1982) is based on a corpus drawn from closely matched British English texts published in the same year. Whereas it could be argued that these lists are outdated, they have the virtue that it was easy to spot and avoid the ephemera of forty years ago, so the words chosen from the lists would be comparatively independent of time.
In these frequency lists, no distinction is made between homographs (words identical in spelling, but with different pronunciations and meanings) consequently sow /soU/ ‘plant seed’ is not distinguished from sow /saU/ ‘female pig’. Neither is any distinction made between homologues (words with identical spelling and pronunciation, but different meanings), so bear ‘animal’ and bear ‘carry’ are listed as one entity (Hofland & Johansson 1982:7; Kucera & Francis 1967:xxi). This means that words with homographs and homologues have artificially high frequency ratings, and moreover the list user is unable to tell which of the meanings is most frequent. Both Kucera and Francis, and Hofland and Johansson, list words as graphic forms, rather than lemmas (Hofland & Johansson 1982:7,20) so, for example, chair, chaired, and chairs are counted separately, with no indication as to how many instances of chairs represent plural nouns versus present tense third person singular verbs. A word appearing with different frequencies in singular and plural forms could be used in either number in the test.
This coincidence of word forms from different syntactic classes is an epiphenomenon of modern English, and would not be encountered in languages which are more inflected. There seemed no reasonable way round the problem of priming from forms that exist both as verb and noun (e.g. train, plant, bank) or verb and adjective (e.g. wet, dry, light) short of omitting them entirely, which would have drastically diminished the supply of possible words. The supply of words is particularly critical because the Aural Working Memory Span test was devised as a bilingual test, in order to be used in a study of English-German bilingual subjects. (This bilingual study does not form a part of the present thesis.) The list of words which fulfil the criteria for selection listed above, and which also have only one or two syllables in German is very limited.
Indeed, the availability of suitable sentence-final words was the constraining factor on the number of “spare” sentences given at the end of each of the versions of the test. Of the 202 sentences in the four versions of the test, 123 sentence-final words have (in English) a homophone of the same or different word class, and 79 words do not. The noun and adjective readings are concrete and highly-imageable, whereas the verb readings tend to be more abstract or metaphorical, which increases the likelihood of the noun and adjective meanings being accessed more easily. In addition, the context disambiguated the homologues, since, in the test, only nouns and adjectives were used sentence-finally.
The non-target nouns were also of high frequency (at least one in a million), but could be of more than two syllables. It was decided that a word used as a target word in one version of the test could be used as a non-target word in the other versions, since the alternative versions were intended for repeat administration on different occasions. Care was taken to avoid semantic priming within a test, so, for example sea and ocean, or ice and snow, did not co-occur.
5.2.8.6 AWMS target words: age of acquisition
Consideration should also be given to the age at which a word is acquired, since the test could be administered to teenagers, or to people with learning difficulties who may have delayed language. In addition, words that were acquired early have been shown to remain longer in the lexicon of elderly people, or people with aphasia or incipient dementia, to whom the test might also be administered (Morrison et al. 1992). Age of acquisition could have been controlled for by using lists of those words acquired at the youngest ages, however, foodstuffs and playthings tend to predominate in such lists, making them both time- and culture-specific. In addition, the majority of the words to be used in the test would be acquired after the child’s first two or three years, which are the focus of such lists of earliest words.
The alternative approach is based on ratings of how old a rater thinks a child would have been when he acquired a specified word. Such ratings are generally considered to be broadly accurate, and ratings by adults accurately reflect the developmental sequence of vocabulary growth and age of acquisition (Morrison et al. 1997:533). Because the words selected for the test are imageable and concrete, they are also assumed to have a relatively early age of acquisition. Both raters (linguistics graduates and mothers of teenagers) rated all the target words as being acquired before the age of six.
age
à 2 years
2-3 years
3-4 years
4-5 years
5-6 years
rater 1
12
166
11
8
5
rater 2
5
158
25
9
5
Table 6-6 Rated age of acquisition of target words
There could be a conflict between age of acquisition and word list frequency, since a word may be acquired at a young age, yet not appear frequently in print. An example of this was strawberry, rated as acquired at just over two years (Morrison et al. 1997), but with a frequency of only two per million in both Kucera and Francis, and Hofland and Johansson. The converse also applied, in that a word may have high frequency in a written corpus, but be of such a specialised nature that very few people would know or use it. An example of this was hypothalamic, which has a frequency of twenty-two per million (in Kucera and Francis), but is unlikely to be recognised by people without specialist knowledge.
5.2.9 Rationale for the Combined Memory Score
The original intention had been to measure working memory using a combination of three tests: AMIPB (used in clinical neuropsychological testing), AWMS (based on working memory span tests used in psychological research), and DB (used in both disciplines). The aim of this was to reflect the scores on more than one test, to eradicate or minimise the effects of tied scores, and to give a better spread of results. From the first, it was realised that DB presented certain theoretical problems (discussed in section 10.2.1), but it was included in the study because of its wide use. However, as a result of the lack of significant correlation shown in study 1 of scores on DB with those on AMIPB and AMWS, and with complexity scores, it was decided that DB should not be included in the combined memory measure. The CMS was therefore based on the amalgamation of standardised scores on two tests: AWMS and AMIPB.
Working memory span tests, such as that of Daneman and Carpenter (1980), are widely recognised as being measures of working memory, yet the timescale over which administration and recall of such tests take place ranges from approximately 8 seconds (for lists of 2 items) to approximately 20 seconds (for lists of 5 items). In fact, it was found subsequently that recall of AWMS items commonly took longer than this for most participants, as almost everyone found the task extremely difficult, and needed to use conscious search strategies to accomplish it. It may thus be seen that even a working memory test so named does not accord well with the timescale attributed to working memory. Indeed, Baddeley and Wilson (2002:1741) cite the problem of accounting for performance on working memory span tasks as one of the reasons for postulating the existence of the recently proposed episodic buffer.
AMIPB administration and recall take place over a period of some 1 to 2 minutes, which is the timescale of immediate memory. The recall of prose is regarded as “one of the most striking limitations” of the standard tripartite working memory model, leading to the postulation of the episodic buffer (Baddeley & Wilson 2002:1738). The priming, maintenance and integration of a number of representations held in long term memory (ranging from words and phrases through to cognitive scripts) are assumed to be involved in the comprehension of a prose passage (Baddeley & Wilson 2002:1742). These representations and schemas must not only be held active, but also combined by executive processes into novel episodes, and maintained within the episodic buffer, whose contents are available for retrieval through the process of conscious awareness (Baddeley & Wilson 2002:1742).
It may thus be seen that the two working memory tests, AWMS and AMIPB, are both assumed to utilise the same cognitive mechanism of the episodic buffer, and thus their amalgamation into the Combined Memory Score is well motivated.
5.3 Tests rejected from study 1
In the earliest pilot interviews, in addition to the tests described above, a number of others were tried out. These latter tests were not included in the final format, because they increased the length of the test interview as a whole, while generally providing no useful information additional to that elicited by the tests which were included.
5.3.1 Cognitive Estimates
Cognitive Estimates (Shallice & Evans 1978) which consists of a set of orally administered questions, tests the ability to select and regulate an appropriate cognitive plan. Such abilities are attributed to the cognitive processing performed in the pre-frontal lobes of the cerebral cortex, which are also considered to be the locus of both working memory (Goldman-Rakic 1996) and social intelligence (Brothers 1990:46). In Cognitive Estimates, the subject is asked to make a best guess in answer to such questions as What is the largest object normally found in a house? or How many camels are there in Holland?. People who cannot formulate an appropriate strategy, or who have inadequate error-checking, produce very bizarre responses. It had been hypothesised that the test might reflect social intelligence abilities, but it became apparent that, in the absence of frontal brain damage, there was no variation between individuals on Cognitive Estimates in study 1. Since no information was being gained, the test was dropped.
5.3.2 Sentence Repetition
The Sentence Repetition subtest of the Multilingual Aphasia Examination (MAE) (Benton & Hamsher 1989) consists of sentences of varied linguistic structure, increasing in length from three to twenty-four syllables. The examiner reads a sentence to the subject, and the subject immediately repeats it: this continues until the subject has made four failures. The advantage of sentence repetition is the naturalistic quality of the test in comparison to digit span, and the opportunity to assess the contribution made by meaning to the subject’s span of auditory-verbal attention by comparing scores on sentence span and digit span (Lezak 1995:363-4). The average adult can recall sentences of twenty-four syllables in length, whereas people with attentional deficits have difficulties with sentences of eighteen or twenty syllables (Lezak 1995:364-5).
It should be noted that this test is from an aphasia assessment battery, and that the normally expected adult span of 24 syllables is the end of the test. It does not, therefore give any indication of above average performance. In an attempt to address the deficiency, additional sentences were formulated, containing from twenty-six to fifty syllables, increasing by two in each sentence, and echoing the varied linguistic structures found in the original MAE test. Those subjects tested on Sentence Repetition performed at above average levels, but it was found that at about twenty-eight to thirty syllables memory ceased to be verbatim, and instead all the subject could recall was the gist of the sentence. The different linguistic structures in the sentences (in both the MAE and expansion) also constituted a problem. The only element varied systematically was the number of syllables, but subordination, co-ordination and adjunction were not controlled for, and this meant that the sentences were not necessarily of incremental difficulty. For this reason, it was not obvious that any differences in performance would be attributable solely to the contribution of meaning, and the sentence repetition task was therefore eliminated from the interview.
5.3.3 Nonword Sentence Repetition
A Nonword Sentence Repetition task was devised, as a test of memory, in which the examiner reads out a short sentence including two nonwords, and the subject has to repeat the sentence immediately. This test utilised nonwords from a test of children’s phonological working memory (Gathercole et al. 1994) which, in contrast to many published nonwords, are convincingly word-like, and range in length from two to five syllables. Simply repeating the nonwords would be too easy for adults, as Gathercole et al.’s test was intended for children of four to nine years. In order to make the test sufficiently demanding for adults, without adding morphological affixes which would detract from the word-like quality of the nonwords (c.f. anti-dis-establish-ment-arian-ism), the nonwords were put into short sentences. Inserting nonwords in a sentence repetition task sought to maintain a naturalistic quality while increasing the task difficulty.
Each sentence contained two nonwords, the number of whose syllables increased gradually from two plus two to five plus five, over the course of fourteen sentences. The nonwords were placed so as to imply membership of an appropriate word class, e.g. commeecitate was treated as a verb, and stopograttic as an adjective. Examples of the sentences are If it’s hampent, Jane might bannow in the sea (2 + 2 syllables) and Susan thinks the versatrationist looks detratapilic in green (5 + 5 syllables). The resultant sentences were extremely demanding, and it seemed likely that floor effects would predominate. Another consideration was that the people with whom the task was attempted commented negatively about being asked to repeat gibberish. The task was therefore abandoned.
5.3.4 Picture Description
A Picture Description task, intended to elicit complex language, was tried out, in which the subject was asked to describe what was happening in a detailed cartoon picture, and how the characters in it would be feeling. The picture was of a similar nature to some that had been used as stimuli for first year oral examinations in the School of Modern Languages at Newcastle University, and depicted a living room filled with people and children all engaged in, or on the brink of, some activity or emotion. It had been hoped that the subjects would comment on the situations and their likely outcomes, and the mental states of the protagonists, hence giving rise to a wide variety of adverbial clauses. Although some subjects spoke about situations and emotions, most of the language produced was in the present progressive tense, and concentrated on physical events and characteristics. The test was consequently not achieving its goal, and was abandoned.
5.3.5 National Adult Reading Test
The National Adult Reading Test (NART) (Nelson 1982) consists of a list of fifty words, which are to be read aloud by the subject. These words are phonetically irregular and of low-frequency (e.g. topiary, beatify, superfluous, demesne) and consequently cannot be read aloud correctly unless the reader already knows the words and recognises their written form. The NART was originally designed to provide an approximation of premorbid IQ in people suffering from dementia, and the test includes a table of NART error scores and the corresponding predicted Full IQ values, ranging between IQ 128 (0 errors) and IQ 86 (50 errors). The NART therefore gives a quick and easy method of obtaining a measure of subjects’ IQs.
The NART was qualitatively different from all the other tests, which were oral/aural, in introducing the need for literacy, and would accordingly almost certainly not give reliable IQ estimates across a range of people with specific literacy impairments or dyslexia. Several of the subjects who undertook the NART commented disparagingly on their own performance, seeming dispirited at not knowing all the words, even though their performance indicated above average IQ (IQ 116 corresponds to 14 NART errors). Since some of the subjects were attending Adult Basic Education classes for literacy and/or numeracy, it could be assumed that many would have below-average IQs (although there may be a variety of reasons why people may not do well in compulsory schooling). It was considered unreasonable to expect people with low literacy skills to cope with such difficult words, especially when they would probably experience a high failure rate, due either to an inability to decipher the orthography, or to reading the letters but not recognising the word. It would be expected that the NART would have a differentially demotivating effect on the subjects, which provide a source of confounding. Therefore, although the NART had been providing additional information in the form of IQ, it was nonetheless abandoned.
5.3.6 Serial Subtraction
Originally the test of attention and concentration had also included a serial subtraction task, in which the subject was asked to start at one hundred, and keep taking away seven until told to stop. Younger subjects who had not been taught to do such mental arithmetic found this task difficult, and it was considered that many subjects from the Adult Basic Education classes (especially those with numeracy problems) would be unable to undertake it with any hope of success. Since the goal of testing is to obtain the best performance of which an individual is capable (Heaton and Heaton 1981, quoted by Lezak 1995:139), it would be counterproductive to cause a subject to suffer any deleterious psychological effects. Failure on such a task would cause the subject to lose face, and to experience distress or anxiety which would not be conducive to good performance on the rest of the test interview. This would represent a source of potential confounding, and serial subtraction was therefore dropped.
5.4 Summary
This chapter set out the background and rationale for the development of the test interview. The constituent tests within the interview were described, as were those tests that were considered but rejected. The development of the AWMS test was recounted in detail. (The test stimuli for all these tests are given in the appendix.)
The next chapter deals with the development of the protocol for categorising the complex language elicited by the test interview.
6. Study 1: introduction: categorisation
This chapter recounts the development of the categorisation, by which is meant the syntactic analysis and description of the spontaneous speech data. Section 7.1 describes how the procedures for the categorisation of the data were arrived at, and sets out the syntactic explanation for the selection of those elements which were categorised as representing complexity. Section 7.1.6.1 outlines the development of the Index of Language Complexity (ILC).
6.1 Development of the categorisation protocol
The categorisation protocol, like the test interview, developed over the course of study 1. At first, general theoretical considerations guided the selection of the elements to be categorised. However, the categories were refined, over time, in the light of analysis of the study 1 data, and the further examination of the literature in the fields of language acquisition and disorders, complexity measurement, and descriptive grammar.
Complexity was to be sought at the level of syntax, since this was the level in which complexity had been claimed in numerous studies of comprehension and working memory. Also, unlike semantics, syntactic complexity is amenable to relatively precise and objective measurement. It seemed reasonable to examine in particular the functional categories Determiner Phrase (DP), Inflection Phrase (IP) and Complementiser Phrase (CP) because they do not appear until a specific point in the developmental sequence has been reached (Radford 1990:275), and they may be selectively lost in aphasia. They might therefore be assumed to be loci of computational difficulty. Within DP additional complexity is represented by attributive adjectives (e.g. a APbig APfluffy cat) and degree adverbs (e.g. an AdvPextremely APfluffy cat), whereas within IP and CP complexity may appear in many more guises. IP is the site of to infinitives, auxiliaries, and finite verbs, which instantiate Aspect, Tense, Voice and Mood; while CP hosts wh- elements, subordinating conjunctions, complementisers, and V to C movement. Therefore IP and CP are involved in embedding and movement phenomena. Adverbial elements may appear in IP or CP, depending on the individual item, and co-ordination may appear at almost any level, functional or lexical. All these phenomena are as standardly represented within the Chomskyan paradigm.
Papers dealing with comprehension and working memory (Just & Carpenter 1992:128; King & Just 1991:580) have noted the difficulty, and hence presumed complexity, of object trace relative clauses (e.g. [The mani [who/whom/ that /Æ John saw ti] caught the bus]). It should, however, be pointed out that published examples of the stimulus sentences used in such experiments often sound unnatural, which might in itself be presumed to have a deleterious effect on the hearer’s comprehension.
Object-trace relative clauses serve to pick out, or to disambiguate a referent (e.g. the cakei [John bought ti yesterday] has been eaten already), but, since they impose demands on working memory, for both the speaker and hearer, it is likely that, in spontaneous speech, alternative ways of expressing the same message would be more natural (e.g. [John bought a cake yesterday] [and it’s been eaten already]). To a large extent, the likelihood of relative clauses occurring is consequent upon the perceived formality or informality of an interaction, and, since this is out of the investigator’s control, it would clearly be unwise to rely on the presence of object-trace relatives to exemplify complexity.
The computation of anaphoric referents over varying distances has also been claimed (Daneman & Carpenter 1980:450) to be dependent upon working memory. The problem with measuring anaphoric reference distances in spontaneous speech is that is not feasible to produce ecologically valid stimuli that would guarantee that subjects would produce anaphors, and particularly not to elicit varying distances from their referents.
This meant that alternative criteria for complexity had to be sought. It was clearly preferable that complexity be demonstrable among those elements that appear relatively frequently in spontaneous speech. It was therefore necessary to start from a position suggested by theory, and proceed pragmatically, in response to the spontaneous language that was actually produced by the various subjects in the initial study. The refinement of the criteria was, of necessity, an iterative process, necessitating a large number of consecutive passes through the data, as first one, then another, version of the categorisation protocol was tried out.
It is inevitable that the investigator should have experienced a subjective sense that some speakers performed “better” or “worse” than others: what was wanted was a means of making objective, and quantifying, this subjective judgement. The aim of the categorisation was to arrive at an objective definition of complexity, in terms of syntactic criteria, that would yield a quantifiable measure of ability, in order to differentiate between speakers, and to permit comparison with measures of working memory.
6.1.1 Data editing
For the earliest study 1 subjects, the retelling of the AMIPB story and the Picture Description task were transcribed, counted and categorised. However, it became apparent that most people were heavily primed by the syntactic form and lexical items of the AMIPB story, and generally repeated whatever they could recall of it more or less verbatim. Since the retelling represented the recall of primed material, rather than the subject’s own generative ability, it was decided not to include the retelling in the categorisation. The retelling was removed from the data, and the word and utterance counts amended accordingly. As described above, the Picture Description task did not perform well, and was consequently eliminated from the study. At that stage, the Picture Description material was removed from the data, and the word and utterance counts were amended.
The early version of What & Why had comprised twenty questions, and the answers to all of these had been transcribed and categorised. However, when What & Why was amended, the answers to the rejected questions were removed, leaving only the answers to those questions which were the same as, or (as with the meanings of proverbs) directly comparable to the questions on the final version. Eventually, therefore, the transcriptions and categorisation resulting from the rejected questions were removed from the data, and the word counts adjusted accordingly, although that material had been included during most of the development of the categorisation protocol.
In the field of language disorders, it is frequent practice to clean up spontaneous speech data before analysing it. An example of this is the instructions for the extraction of the corpus of narrative words in the Quantitative Analysis of Agrammatic Production, whose protocol (Saffran et al. 1989:469-70) instructs users to remove (inter alia) comments about the task; habitually used starters; words introducing direct speech; and all but the final version of material that is subsequently repaired (repeated, amended, or elaborated).
Although the original transcriptions included all the hesitations, repetitions and reformulations, these had been edited out before the categorisation was started, and the word counts were amended to exclude those same elements. Since the instances of any categorised element were computed per hundred words (using the word count as the denominator), the exclusion of hesitations, repetitions and reformulations had little effect on the data from the more fluent subjects, but it made a considerable difference in the data from subjects who were less articulate. In addition to perceptibly diminishing the amount of data available for categorisation, such editing frequently gives an unwarranted impression of articulacy in those subjects who performed most poorly.
The three examples below show the original transcription, with the words edited out highlighted in bold. As may be seen, the amount removed could vary from nothing to approximately 40% of the word score.
(subject 4) just because something good happens doesn’t mean it’s going to be good all the time or just because something bad happens doesn’t mean it’s going to be bad all the time = 31 words (nothing edited out)
(subject 5) um it’s er pre-empting something that’s happening. you don’t pre-empt something that is likely to happen. wait till it happens. don’t- um don’t set out your stall too early as it were because er you get the- you can get the- the completely er wrong reaction. um you could be too early be too boisterous er too presumptive I suppose = 60 words (including 12 words edited out)
(subject 10) right. what does it mean? um. mm. sort of like um it’s sort of- what I would say in that is another- all to do with quickness you know, if um- not very good at explaining things. um you won’t trip up if you take more- more care in what you’re doing. = 52 words (including 21 words edited out)
It was decided to count various nonpropositional elements in the data, and, at this point, all the hesitations and mazes which had previously been edited out were reinstated, and included in the word and utterance counts. (The study on the nonpropositional data is reported as a chapter, in the appendix.) The counting of mazes and abandoned utterances helped to differentiate between subjects of different ability. Hesitations (filled pauses and repetitions of all or part of a stimulus question) were counted, but did not separate performances of differing ability, probably because of the variety of possible reasons for hesitation, which could include word-seeking, monitoring, and turn-holding phenomena. Some automatisms had, until that point, been included among AdvPs (e.g. actually) or adverbials (e.g. at the end of the day), but could subsequently be categorised more appropriately, as automatisms. This also helped to distinguish between high and low performers.
6.1.2 Counting data
Previous analyses of productive language (written as well as spoken) have used various units of analysis. Propositions have been treated as units, as is the case in the P(ropositional) Density metric, which was designed to measure the reading difficulty of written texts (Cheung & Kemper 1992:62). A proposition in this case refers to a predicate expressing an action or state; a modification or quantification; and connections, expressing conjunction, disjunction, causality and contrast (Cheung & Kemper 1992:62). A similar measure, that of idea density, was used by Kemper to analyse the written diary data in the Nun Study (Snowdon 2001:109). These are measures appropriate to semantic, rather than syntactic complexity.
The Content Unit is defined as “a grouping of information expressed as a unit by normal speakers” (Shewan 1988:129), which appears to correspond very closely to a proposition in PDensity, and also to a point-scoring unit in neuropsychological story recall tests. Although it is suitable for use with highly predictable productive data, such as that from the picture description task Shewan employed, it is not compatible with more variable productive data, such as that elicited in this study.
One of the most influential units of analysis is Hunt’s T-unit, defined as “one main clause plus any subordinate clause or nonclausal structure that is attached to or embedded in it” (Hunt 1970:4). Hunt worked on written data, but his T-unit would be approximately equivalent to a definition of an utterance. It would not, however, be feasible for spoken language data, because of the problem of mazes and abandoned utterances. In addition, combining a main clause and all its subclauses and phrasal adjuncts as one unit rather defeats the point of counting separate instances of complexity.
The Text Unit (TU) used in the Reading Aphasia Project may be lexical, phrasal, clausal, minor (e.g. social formulas), or unclear (including unintelligible, ambiguous, stereotypic, or incomplete utterances), and TUs are joined together by Immediate Grammatical Relations (IGRs) (Edwards et al. 1993:218-9). Although it is seemingly clinically advantageous to have the separation into different kinds of TU when describing disordered speech, it would be unhelpful when dealing with data from normal subjects.
In this study, the frequencies of categorised elements were initially calculated both per hundred words, and per utterance, with an utterance being defined by prosodic and syntactic criteria. The speaker signals the end of an utterance by posture, gesture, or prosodically by a drop in pitch (Wardhaugh 2002:298): but syntactic criteria were also imposed by the investigator, in that (as described in the method section) an inflected clause with an overt subject, headed by and was treated as a new utterance, except where it fell incontrovertibly under the scope of a higher subordinating conjunction.
The count per utterance (that is, total number of instances of an element, divided by the total number of utterances) was necessarily always somewhat suspect, in that, for an identical word count, a subject who produced longer and more embedded utterances would have a much smaller denominator than a subject who produced shorter and less embedded utterances. It was therefore decided (albeit at a late stage) to disregard the counts per utterance, and use only counts per hundred words, as these have direct comparability. It was felt that little information was lost by discontinuing the count per utterance, since those comparisons of Mean Clauses per Utterance (MCU) that were undertaken when either all (CP and IP/VP) embeddings, or only CP embeddings were counted, showed very little differentiation between subjects of differing ability.
The subsequent sections (7.1.3 to 7.1.6.2) describe not only the development of the categorisation protocol, but also the syntactic rationale for the decisions made.
6.1.3 Inflection Phrase (IP) elements
In the initial categorisation, finite verbs and the various auxiliaries (modal, perfect, progressive, passive, and do) were counted separately, and present and perfect participles conjointly. It had been thought subjects might have differed in the amount of complexity produced through varying verb forms expressing such elements as passive voice or irrealis mood, as these have been proposed as separate functional heads within IP (Cinque 1999). It became apparent, however, that the production of differing auxiliaries was largely task-dependent, in that high numbers of progressive and perfect forms were produced while telling a story, whereas the questions in Speculation elicited numerous modal forms. It was therefore decided to drop the categorisation of verb forms.
It had originally been expected that subjects would differ in the overall depth of embedding that they could produce, and consequently, in the early analyses of the data, all embeddings at all levels were counted. Indeed, all levels of embedding have been counted in previous analyses of spontaneous speech, such as those of Kemper et al. (1989) and Morice and Ingram (1983). The import of this was that not only clauses headed by a CP element (relativiser, subordinating conjunction, or complementiser), but also those headed by an IP (to) or VP element (-ing form, e.g. John couldn’t help [wondering]) were treated as being of equal difficulty, despite the much earlier chronological development of VP and IP forms during child language acquisition (Scott 1988a:48).
It became apparent that catenative verbs and their IP or VP complements (e.g. [John seems [to be likely [to want [to manage [to be able [to keep [producing verbs]]]]]]]) were swamping the less frequent and potentially more interesting CP embeddings. Once these catenative verbs had been eliminated, there was no principled reason for continuing to count other raising, control and exceptional case marking verbs with IP or VP complements. The IP/VP embeddings were some three to four times as frequent as CP embeddings, but showed little variation between subjects, and were hence assumed not to be indicating differential performance. It was therefore decided to ignore IP and VP embeddings, and to count only those at CP. For this purpose, clauses introduced by zero forms of relativisers and complementisers were regarded as being CPs.
6.1.4 Complementiser Phrase (CP) elements
In the earliest stages, instances of each of the different forms of relativisation (i.e. wh-, that, and Æ), and of complementiser clauses (i.e. that, Æ, whether, if, and for) were counted separately. No distinction was made between restrictive and non-restrictive relatives, particularly since non-restrictive relatives appeared very infrequently. At this stage, all CPs apart from relatives and complementisers were counted together, with an additional separate count for each of because, if, and so, as these appeared frequently.
In the initial stage, instances of V to C movement were also counted, although this was dropped, as the very few questions that appeared in the data were generally as direct speech attributed to characters in the stories. Topicalisation, and expletive it or there were initially also counted separately, although they would impose very different processing demands. Topicalisation would assume adjunction movement to Spec CP or a putative Topic P; by contrast, an expletive allows the subject to remain in its base-generated position, as only the dummy element raises. In practice, both topicalisation and expletives were so infrequent that no useful information was gained counting them separately, and so they were dropped from the categorisation.
Because of their comparative infrequency, no useful information was being gained by counting the different forms of relative and complementiser clauses separately, so at an early stage all relatives were aggregated, as were all complementiser clauses. Clauses headed by a complementiser (that, Æ, if, or whether) may function as subject e.g. [[That he was lost] annoyed John]; direct object e.g. [John asked [whether/if it would rain]]; or complement (subject-predicative) e.g. [John’s problem is [that he is clever]]. Complementiser clauses are required by the sub-categorisation frame of the verb and are therefore obligatory. Similarly, it is possible for wh- clauses to function either as subject e.g. [[How to explain it] is John’s problem]; or direct object e.g. [John knows [where to go]]; or complement (also known as subject- or object-predicative) e.g. [John became [who he wanted to be]], [John can call me [what he likes]]. In such cases, the wh- clause is an obligatory element. It has been noted (Beaman 1984, cited by Georgakopoulou & Goutsos 1997:91) that complement clauses appear very commonly in spoken narratives.
At this stage, in place of keeping together all non-relative and non-complementiser CPs, a distinction was then made between those clauses introduced by wh- elements which were functioning as adjuncts versus those which were complements of the verb. Subsequently, no clauses which functioned as part of the argument structure of the verb (and which were therefore obligatory) were then counted. Adverbial clauses, relative clauses and some instances of co-ordination (described below) were regarded as functioning as adjuncts, and were therefore counted as optional CPs.
6.1.4.1 Adverbial clauses
Adverbial clauses are tensed IPs with overt subjects, introduced by subordinating conjunctions such as after, (al)though, as, because, before, once, since, unless, until, whereas, while, and whilst. The inherent meaning of the subordinating conjunctions allows the clause to function as an adverbial (Burton-Roberts 1997:207).
Some expressions of time can act as subordinators e.g. [[Directly/ Immediately/ The next time/ The minute (that) John spoke] she recognised him] (Quirk & Greenbaum 1973:314) and these were counted as introducing optional clauses.
Care was taken to differentiate the complementiser if (introducing an argument clause) from the subordinating conjunction if (introducing an optional clause). Complementiser if is replaceable by whether, and represents a subordinate yes/no interrogative which functions as a direct object of the verb e.g. [Do you know [if/whether John is here?]]. In contrast, subordinating conjunction if is not replaceable by whether, and represents conditionality in an optional clause e.g. [[If it rains] (then) John will get wet]. A new kind of conditional structure has been claimed (Denison 1998:301) to have arisen, in which there is no formal marking either of the protasis (the “if” clause) or of the apodosis (the “then” clause). Denison (1998:301) cites as an example [[You keep smoking those cigarettes] you’re gonna start coughing again]. Since this structure is reliant on prosody for its interpretation, it was not to be counted as an optional clause, but rather as two separate utterances. There are, however, conditional clauses without if, that are marked by the inversion of the subject and auxiliary e.g. [[Had John seen the clouds] he would have taken his umbrella], or by the use of the imperative e.g. [[Do that again] and you’ll hurt yourself] (Denison 1998,298,301). These clauses were counted as being optional CPs.
Phrasal or compound subordinators (consisting of preposition + that) were very common in early modern English (c1500 -1700) (Barber 1997:206-7), but many have now disappeared, such as besides that, but that, and for that, which were lost in the 19th century (Denison 1998:294-5). Other compound subordinators have arisen: in order that originated in the 18th century, and recently forms such as being (as/ that) and seeing (as/ that) have become grammaticalised (Denison 1998:295,297). The more recent forms of these compound subordinators show that that tends to be omitted and the preposition either used alone e.g. besides, or with an abstract noun e.g. besides the fact that (Denison 1998:294). There would consequently appear to be a language change underway, which is especially noticeable in a more informal register, such as that elicited in the interviews.
A difficulty arises as a result of the omission of that after so, centring on whether any given instance of so is a subordinating conjunction, or a conjunct AdvP. The omission of that after so has apparently become possible only comparatively recently, and as a consequence, the difficulty it presents does not appear to have been addressed by previous studies involving complexity. Both so and so that are subordinating conjunctions introducing clauses expressing either purpose or result, with so that more commonly used for purpose, and so for result (Quirk et al. 1985:1109) although this appears to be increasingly a matter of personal predilection. (An example of this is Mary smiled at John so (that) he felt happy, which demonstrates the possible ambiguity between purpose and result.) So appearing on its own may alternatively be a conjunct AdvP, whose function is to link the clause it introduces into coherent discourse. Unlike its near synonyms therefore, and thus, which may appear either clause-initially or following the subject and/or operator, so is restricted to appearing clause-initially (Quirk & Greenbaum 1973:254). This consequently necessitates explicit rules to distinguish AdvP so from subordinating conjunction so.
In final (purpose) clauses, there is frequently a modal auxiliary (or a subjunctive in very formal registers, or some American English varieties). In such clauses, so is replaceable by so that or in order that and conveys purpose e.g. [John booked tickets [so (that)/ in order that he could see the play]]. When expressing purpose, the subordinate clause can precede the matrix clause e.g. [[So (that)/ In order that he could see the play] John booked tickets]. Purpose clauses with the omission of that may therefore be easily differentiated from clauses introduced by AdvP so.
Consecutive (result) clauses, however, are not so straightforwardly distinguishable from clauses introduced by AdvP so. Since result is factual, not putative (Quirk et al. 1985:1108) it does not take a modal or subjunctive, and hence a clause introduced by subordinating conjunction so cannot be differentiated from one introduced by AdvP so by the presence of a modal or subjunctive. It is generally the case that a clause introduced by a conjunct AdvP cannot be moved in front of the preceding clause, whereas a clause introduced by a subordinating conjunction can (Quirk & Greenbaum 1973:241,255). However, even when so is a subordinating conjunction, the result clause cannot precede the matrix clause, since the relation expressed is that of logical consequence (Quirk et al. 1985:1109) e.g. *[ So John had to queue] [the box office was busy]. It is therefore impossible to distinguish the subordinating conjunction and AdvP by this means.
AdvP so, unlike the majority of conjunct AdvPs, is not separated from what follows it: moreover, it is separated from the preceding clause by a tone unit boundary in speech, and by a comma in writing (Quirk & Greenbaum 1973:248). A result clause introduced by so is also separated from the matrix clause by intonation in speech, and a comma in writing (Quirk et al. 1985:1072,1109). Thus, if that is omitted from a result clause, subordinating conjunction so becomes indistinguishable from the conjunct AdvP so (Quirk et al. 1985:1109). Since it was impossible, in these circumstances, to determine precisely what status attached to so, a decision had to be made on the balance of probabilities.
So is a subordinating conjunction where it precedes an AP or an AdvP (as in so [AP/AdvP] that…) as a form of correlative (Quirk & Greenbaum 1973:314), e.g. [The play was so popular [(that) it had a long run]], with an alternation being (just about) possible with [The play was popular [so (that) it had a long run]]. Where so is clearly replaceable by so that, it is a subordinating conjunction introducing a result clause e.g.[The acting was good [so that the play was enjoyable]]. Similarly, where so is clearly replaceable by such that, it is a subordinating conjunction introducing a clause in which result and manner are mingled e.g.[The seating was arranged in tiers [such that everyone could see]].
Where so is not replaceable in this way, or where so signals a summing up of what has gone before and is replaceable by therefore or thus, it was counted as a conjunct AdvP, introducing a new utterance. If so is separated prosodically, or does not continue semantically from the previous utterance, it was treated as an AdvP, e.g. So, where did it go?
Many of the subjects are native to the Tyneside and Northumberland region, and hence, where Standard English has the correlative so [AP/AdvP] that…, they have the dialectal form that [AP/AdvP] Æ (Beal 1993:209), e.g. [It was that icy [Æ John fell over]]. Such clauses were treated in the same way as the equivalent standard form.
6.1.4.2 Relative clauses
Relative clauses are headed principally by the relative pronouns who, which, that, and Æ, e.g. [John met Mary [who invited him to a party]], [The parties [Æ Mary throws] are notorious]. Relative clauses may also be introduced by whom, whose, that’s, how, where, when, and why. That’s as an alternative to genitive whose e.g. [John read a book [that’s cover was torn]] is a 20th century development. It is regarded as grammatical in modern Scots (Denison 1998:280) and its use seems to be increasing among younger speakers. What or as may occur as a relative marker in non-standard varieties e.g. [John saw some people [what /as he knew]]. In Standard English a zero relative is grammatical only when the relative marks the object (Denison 1998:280) e.g. [That’s the mani [Æ John saw ti]]: however, Tyneside English also has zero relatives as the subject of the relative clause (Beal 1993:208) e.g.[That’s the mani [[Æi was talking to John]].
Despite being standardly represented as complements of N, restrictive as well as non-restrictive relative clauses were counted. Restrictive relatives pick out a restricted set of items e.g. [[The books which/ that/Æ John has read] are on the table]; whereas non-restrictive relatives add information without restricting the set, and usually have “comma intonation” e.g. [John and Mary, [who were rather late,] finally arrived].
Sentential relatives, a form of non-restrictive relative, refer back to the preceding clause or sequence of clauses e.g. [[John asked us to visit him] which was nice]. They may occur as PPs with which as a relative determiner, in such forms as at which time, or in which case e.g. [[John might be late [in which case we’ll go without him]. Sentential relatives can also take the form [relativiser](so)ever, e.g. how(so)ever, what(so)ever, where(so)ever, who(so)ever, or the form where + preposition e.g. wherein, whereby.
6.1.4.3 Co-ordination
Traditionally, the co-ordinators are and, but, and or. Although neither partner in the co-ordination is a constituent of the other (Burton-Roberts 1997:190), both but and or seem to require that the first element be held in mind while the second, informationally optional element is processed. A tensed IP, with an overt subject, introduced by but or or was therefore counted as an optional CP e.g.[John likes Mary [but he is very shy]].
However if a tensed IP, with an overt subject was introduced by and, it was counted as an optional CP only if it fell incontrovertibly within the scope of a higher subordinating conjunction e.g. [[[Because it was raining [and he had forgotten his umbrella]] John got wet]. In all other cases, a tensed IP, with an overt subject introduced by and was treated as being a separate utterance, rather than as part of the preceding utterance e.g. [John went to the cupboard] [And he got out a towel]. Children use and as an habitual utterance initiator, and it appears that many adults never lose the habit. In narratives by children between six and twelve years, some sixty percent of the utterances have been reported to start with and (Scott 1988a:52), which is comparable to the percentages of and in stories told by adults (Scott 1988b:52).
The recent development plus is treated in the same way as and e.g. [John got soaked] [Plus he was cold]. (Also, which is not restricted to appearing utterance-initially; and as well, which appears utterance-finally, were straightforwardly counted as AdvPs). Simple juxtaposition of propositions (parataxis) e.g. [I came. I saw. I conquered] was not counted as either subordination or co-ordination, since it appears to be a discourse phenomenon, relying on the subjective interpretation of prosody. Co-ordination was counted only when the co-ordinated clause followed another clause: it was not counted when it occurred utterance-initially.
6.1.5 Determiner Phrase (DP) elements
It has been claimed (Cinque 1999:139) that noun phrases host a rich variety of functional projections, and this would account for the ordering of adjectives within DP (e.g. my pretty little daughter but *my little pretty daughter).
Degree adverbs may occur within DP, adjoined to AP, and were counted (as Adverb Phrases (AdvPs)), although they may also appear within AdvP, modifying adverbs.
6.1.5.1 Modifier Phrases
Predicative adjectives are, by definition, predicates and are therefore an obligatory part of the argument structure, as subject-predicative e.g. [the book is expensive] or object-predicative e.g.[he made Mary happy]. Since they are obligatory elements, predicative adjectives were not counted. By contrast, attributive adjectives e.g. [an expensive book] are optional elements, and these adjectives were counted separately in the categorisation. People with various forms of aphasia, as well as children with Specific Language Impairment (SLI), are well known to have difficulty with attributive adjectives.
Post-modifying adjectives themselves e.g.[the man APresponsible] are optional, and were therefore counted; however any modification of the adjective (by a PP) is complementation e.g. [responsible PP[for the mess]], and was consequently not counted. Noun modifiers e.g. [kitchen knife], [garden shed] were counted as ModifierPs, as were non-finite verbal participles, when functioning as modifiers of NPs e.g. [the falling rain], [a forgotten promise].
6.1.5.1.1 Comparison
Adjectives may appear either with a bound morpheme, or with the AdvP more/most expressing comparative and superlative morphology, depending on the length of the stem adjective, although in some cases either is possible e.g. commoner ~ more common. A noun modifier does not accept degrees of comparison (e.g. * a more garden shed). Non-finite verbal participles are not gradable (e.g.* the very falling rain) but they can be modified by general AdvPs (e.g. a tragically forgotten promise) (Burton-Roberts 1997:162).
6.1.6 Adverbs and adverbials
In the original categorisation, adverbial clauses and phrasal adverbials were categorised under the headings time, manner, place, reason, condition, and “other”. Adverbs were initially counted with adverbials, but were subsequently counted separately, because AdvPs can occupy sites forbidden to adverbials. It had been postulated that subjects might differ in the production of adverbial elements on semantic grounds, because children with Specific Language Impairment have been noted (Fletcher & Garman 1988:103) as having difficulty with producing adverbials in general, and temporal adverbials in particular. It became apparent that, as with verbal auxiliaries, the production of specific semantic subgroups of adverbial elements was generally task-dependent. Adverbials of time and place predominated in stories, whereas those of reason and condition were more frequent in answers to questions. The subdivision of adverbials was therefore dropped, and was replaced, briefly, by a distinction between conjunct and disjunct adverbials at the phrasal level. This too was discontinued as being uninformative, in favour of a simple split between AdvPs and the other forms of adverbial.
6.1.6.1 Adverb Phrases
The heterogeneity of adverbs as a class is well known, and indeed the term adverb has been used as “a wastebasket for all modifiers” (McCawley 1998:196). AdvPs include general AdvPs e.g. happily, quickly, theoretically; AdvPs used adverbially e.g. perhaps, now, there; and degree AdvPs e.g. very, too, so. AdvPs now most commonly occupy a position after the subject (and tensed operator, where one is present) but there appear to have been changes in this position during the last two centuries (Denison 1998:240-1).
6.1.6.1.1 Comparison
A few adverbs can carry bound morphemes for comparative and superlative forms (e.g. working hard~harder~hardest), but in most cases degrees of comparison are shown by the adverb more/most. The two methods yield periphrastic equivalents (Quirk & Greenbaum 1973:130).
6.1.6.2 Adverbials
Adverbials, since they are optional elements, have greater freedom of position than have obligatory elements (Denison 1998:232), as they are unordered with respect to one another and have interchangeable scope. Adverbials convey such concepts as place, time, manner, reason, purpose, and means, and are typically realised as bare NPs/DPs or PPs e.g. [DPThis morning John woke up PPin a good mood]. Bare NPs/DPs come from a restricted range, dealing mainly with time (yesterday, last time), place (this side), and manner (that way). Various other bare NP adverbials used to be possible in 18th and 19th century English (Denison 1998:233) but are no longer current. Non-finite clauses may also function as adverbials, and may be distinguished by the mobility which is the defining characteristic of adverbials (Burton-Roberts 1997:107) e.g. [(Feeling happy) John (feeling happy) had breakfast (feeling happy)]. Non-finite clauses, whether infinitive or participial, introduced by a preposition were similarly counted as adverbials e.g. [people learn PPthrough copying], [John left early PP(in order) to meet Mary]. It has been claimed (Cinque 1999:28-9) that circumstantial adverbials cannot appear in any of the pre-VP functional category positions, however this appears not always to be the case in spoken English.
No distinction was made between adjunct adverbials (expressing such concepts as time, manner and place) e.g. already, clockwise, on the bus; conjunct adverbials (linking elements into coherent discourse) e.g. furthermore, nevertheless, on the contrary; and disjunct adverbials (expressing the speaker’s attitude) e.g. of course, personally, supposedly. Conjuncts show dialectal and possibly chronological variation, as is shown by the possibility of using sentence-initial as well in Canadian and Australian English, and sentence-initial too in some American varieties (Denison 1998:242). Disjuncts tend to appear either in initial position (especially for new sentence adverbials, such as [Reluctantly …]) or in post-verbal position (for well-established sentence adverbials, such as […apparently]) (Denison 1998:234-5).
The agent (by) phrase of a passive was categorised as an adverbial, since it is optional, and a PP in form. Adverbials in the form of AdvP were categorised as AdvPs.
6.2 Index of Language Complexity: development
Once it had been resolved which elements were to be included in the categorisation as constituting complexity, it was necessary to decide how the final complexity metric, the Index of Language Complexity (ILC), was to be calculated. (The calculations are justified in more detail in the study 1 results chapter, in the section dealing with the relationship between complexity and working memory.)
Although each of the four constituent parts of complexity (optional CPs, Adverb Phrases, Modifier Phrases, and adverbials) individually comprised only one aspect of complexity, considered jointly they represented complexity as a whole. As an analogy, although a person’s height, shoe size or waist measurement individually gives only a (potentially inaccurate) suggestion of his stature, those same measurements considered jointly give a more reliable indication of overall size.
There was no a priori reason to expect any one of the scores to be more or less important than another to complexity as a whole. It was decided, therefore, simply to add together each subject’s scores on the four constituent parts to yield a score for complexity. Clearly, since each subject produced a different number of words, this had to be taken into account, by dividing a subject’s total complexity score by his number of intelligible words. The resultant number was then multiplied by one hundred, to yield a complexity score per hundred intelligible words. These scores were over a standardised denominator, and could therefore be compared across subjects.
6.3 Summary
This chapter has described the way in which, through iterative experimentation, the syntactic categorisation of the spontaneous speech data was arrived at, along with the syntactic reasoning behind the categorisation decisions, and how the ILC was calculated from its constituent parts.
The next chapter will detail the precise methods developed, and used, in study 1.
7. Study 1: method
This first section (8.1) deals with the selection of subjects. Section 8.2 covers the administration of the test, and section 8.3 deals with the subsequent transcription of the spontaneous speech elicited. Section 8.4 sets out in detail the categorisation protocol while section 8.5 describes the procedures involved in the categorisation of the data.
7.1 Subjects
Subjects were sampled across a broad range of (presumed) language ability (from university lecturers and students to attendees at literacy classes), and were selected on the basis of opportunity samples. Three of the subjects in study 1 came from local authority Adult Basic Education classes, which are intended for people who have problems with literacy and/or numeracy, or who wish to acquire basic computer skills. The subjects from the Adult Basic Education classes had left school at the age of fifteen or sixteen, and had no further or higher education. The remaining nine subjects in study 1 came from the population at large, recruited through informal advertisement. Two of these subjects had had only compulsory education, the three youngest subjects were in full-time education (two in the VI form, and one undergraduate), and four had a degree or degree-equivalent qualification.
Criteria for inclusion
>18 years and < 70 years of age
native speaker of British English
no evident pathology of CNS
no evident speech / language pathology
community-dwelling
employability, or further / higher education
success in test of attention (reverse months of year)
Table 8-1 Criteria for inclusion of subjects
Subjects were aged between eighteen and sixty-nine. Eighteen was taken as the lower limit because developments in language are still taking place throughout puberty, and a number of syntactic constructions are recognised to be acquired late (Nippold 1988:1). Seventy was imposed as the upper age limit because some studies have claimed that syntactic complexity declines beyond the age of seventy (Kemper 1988:61).
All subjects were native speakers of British English: no speakers of other national varieties of English were included in the study, in order to avoid the potentially confounding effects of different usage norms in other national varieties. Subjects with evident pathology of the central nervous system were excluded, since such damage could cause a variety of effects on language (Kandel et al. 1995:639). Similarly, the subjects demonstrated no evident speech or language pathology. Three subjects were in further or higher education, while the remaining nine subjects were currently, or had been previously, in normal employment. All the subjects were community-dwelling. The criteria of employability and community-dwelling were intended to ensure that subjects did not suffer from intellectual retardation to a pathological extent, since this is known to affect language (Fowler 1998:291).
In order to ensure that subjects were alert and able to concentrate, their attention was tested by asking them to recite the months of the year in reverse order. Since the months constitute an overlearned sequence, the ability to recite them in reverse order is a good measure of sustained attention (Hodges 1994:111). All the subjects passed this test of attention: had any not done so, their interview would have had to have been discarded from the data.
7.2 Test administration
The subjects were recorded in surroundings with which they were familiar, so that they would feel relaxed, in order to optimise their performance. In so far as was possible, the subject and experimenter were seated at an angle of some one hundred and twenty degrees, to permit eye contact, without appearing threatening. This position is sometimes referred to as the open triangular position, and is considered to be conducive to informality and a relaxed attitude (Pease 1997:121) Throughout each interview the experimenter listened attentively to the subject, providing encouragement by nodding, producing phatic murmurs, and smiling where appropriate. General encouragement was provided between tasks, as appropriate. All subjects were aware that the interview was being recorded, and had given their consent to this. (That the interview was being recorded was also pointed out on the consent form that subjects signed.) Recordings were carried out on Sony EF Super cassette tapes, using a Sony TCS-580V cassette recorder and separate microphone.
Before the interview started, subjects were asked to sign a consent form, thanked for taking part, and asked their current age, their age and level of educational achievement when they left school, and what sort of employment they had had. At the start of the session, subjects were told that the experimenter would explain the purpose of the test afterwards, reminded that the interview was being recorded so that what they said could be transcribed later, and reassured that no-one else would hear the tape.
All interviews followed the same format, with the test items delivered in the same order. The sequence of the test items was determined such that the subject was presented consecutively with tasks requiring different responses, in order to maintain his interest. Another consideration was that the memory tests should be separated from one another, and that any feeling of failure (from potentially poor performance on memory tests) should be counteracted by the more pleasant sensations evoked by having one’s opinions sought. The interview proceeded in the order Digits Forward and Digits Backward, What & Why, AMIPB Story Recall, selection of a picture for Story Telling, Aural Working Memory Span, Story Telling, and Speculation. The tests followed directly on from one another, introduced by a few words of explanation, or instructions, as appropriate.
Name of test
followed by
months of the year in reverse order
instructions for DF and DB
Digits Forward and Digits Backward
explanation for What & Why
What & Why
instructions for AMIPB Story Recall
AMIPB Story Recall
instructions, and selection of picture for Story Telling; then instructions for Aural Working Memory Span
Aural Working Memory Span
reminder of instruction for Story Telling
Story Telling
explanation for Speculation
Speculation
thanks for participation; then explanation of the purpose of the test
Table 8-2 Order of test administration
Attention and concentration were also tested by investigating digit span forwards and backwards. In both Digits Forward (DF) and Digits Backward (DB) there were two strings of each given length, and the test proceeded until the subject had two failures at the same level (as described in section 6.2.6). DB is a demanding test, and towards the limits of their ability subjects may experience several failures before the two consecutive failures that signal the end of the test, so at the end of it subjects were reassured with the words That’s a really difficult task.
What & Why was introduced by These questions have no right or wrong answers. I’d just like you to tell me what you think about them before the first question. As soon as the subject had finished his answer to a question the next was posed, and, if the subject stated that he did not know the meaning of one of the proverbs, the experimenter said Don’t worry: it’s not important and moved on to the next question.
The AMIPB Story Recall task followed the end of What & Why, and was introduced with the words I’m going to tell you a little story, and when I’ve finished, I’ll ask you to tell it back to me. The story was then read to the subject at the same conversational speed as the questions and instructions, and this took approximately forty seconds. The subjects had as long as they wanted for their re-telling of the story, which was recorded, and was scored later according to the AMIPB scoring guidelines.
The subject was next presented with the loose-leaf binder containing the picture stimuli for the Story Telling task. The pictures were displayed on white A4 sheets, inside clear plastic pockets, with the pictures on the recto sides only. The experimenter introduced the task with the words I’d like you to look through these pictures, and then choose one. In a few minutes I’m going to ask you to pretend that it’s a still from a film, and tell me the story. The subject was allowed as long as he wanted to make his choice from the six pictures, and the binder was left with the subject, so he could refer back to the picture if he wished.
Once the picture was chosen, the experimenter introduced the Aural Working Memory Span test. Since the instructions were somewhat complicated, they were given in short sentences, and the experimenter checked that the subject had taken in each sentence, before proceeding to the next, repeating parts of the instructions if requested. The instructions were given in the following words: I’m going to give you some sentences. After I’ve said a sentence, you say whether it’s true or false. Then I’ll give you another sentence, and you say true or false. And then I’ll ask you to tell me the last word in each of the sentences. The number of sentences will go up, but I’ll tell you when it does. We’ll have a practice first. At this point, the practice items were given to ensure that the subject understood what he was being asked to do. If the subject was uncertain about the task, the instructions were given again, and the practice items repeated. After the practice items were successfully completed, the experimenter checked the subject’s readiness with the words Okay? Here we go then. The test items were administered in groups of three sets, each set containing two, three, four, or five sentences. At the end of the first group (of the sets of two sentences), the experimenter told the subject that the following groups would be longer, with the words We’re going up to three sentences now, and so on, mutatis mutandis. When the subject was unable to give the final words of two consecutive sets, the test was terminated, and the experimenter remarked That is an extremely difficult task. As with DF and DB, and the AMIPB task, the test was recorded, and scored afterwards.
The Story Telling task was introduced with the words Have you decided on a picture? You’re telling me the story of the film. What’s happened already, what’s going on in the picture, and what’s going to happen afterwards. No time limit was imposed, and the subject could take as long as he wished. If the story was extremely short, and unresolved, the subject was prompted with And what happens in the end? to try to elicit more speech.
Immediately after the end of the story, Speculation was introduced with the words These are some more questions that ask your opinion. Please, just tell me what you think. The next question was posed as soon as the subject had finished answering the previous one. If the subject did not give reasons for his choice of animal or place to live, the experimenter asked Why? or What is it about X? to try to prompt a fuller answer.
At the end of the interview the subjects were thanked for their participation, with the words Thank-you for taking part in this experiment. Now I can tell you what it’s about, if you’d like to know. The purpose of the experiment was explained, subjects’ questions were answered, and, if the subject requested it, feedback on performance on the memory tests was given.
Cassette tapes were labelled immediately after the recording with the subject’s first name. This was necessary when several subjects were interviewed sequentially (as at the Adult Basic Education classes), and it served as a temporary identifier until the subject’s identification code had been decided.
7.2.1 Working memory test scoring
The memory tests were recorded as part of the test interview, and they were scored during the transcription process, as the relevant sections of tape were reached.
Scores for each of the tests were recorded initially on paper, and were subsequently added to an Excel file of working memory scores.
7.2.1.1 Digits Forward/Digits Backward
The score on Digits Forward (DF) is the highest string length repeated correctly in the order given, and that on Digits Backward (DB) is the highest string length repeated correctly in the reverse order. The score was recorded on paper after listening to the taped test.
7.2.1.2 AMIPB
AMIPB was scored in accordance with the instructions in the AMIPB test manual (Coughlan & Hollows 1985). Two points were awarded for each idea fully recalled, and one point for partial recall, in accordance with the guidelines in the test manual. The score is the sum of the points awarded. Scoring was done on paper, by having a list numbered 1 to 28 (for the 28 ideas to be recalled), and writing down the number of points awarded beside the relevant idea number. The points awarded were then added together, and the total noted on paper.
AMIPB raw scores were subsequently converted to a percentage by division by 56, and multiplication by 100 (in the Excel spreadsheet).
7.2.1.3 AWMS
There were 3 sets of sentences at each level, and correct recall of all the sentence-final words in a set was noted. A single failure on a set was ignored, but the test was terminated after the second consecutive failure. Correct recall of all the sets of any given level gave a score of that length level. Recall of one set at a level gave a score of .3 on top of the length below, and recall of two sets at a level gave a score of .6 on top of the length below.
Scoring was done on paper, by having a list of all the sets, and marking each one with a tick or cross to indicate whether it was correctly recalled or not: for example 2/1ü 2/2ü 2/3 ü 3/1ü3/2ü 3/3ü4/1ü4/2ü4/3X 5/1X (which would represent a score of 3.6, since all the sets of level 3 were recalled correctly, as were two of level 4). The score achieved was noted on paper.
AWMS raw scores were subsequently converted to a percentage by division by 5, and multiplication by 100 (in the Excel spreadsheet).
7.3 Transcription
Necessarily, there was a variable time lag between recording the interview and the transcription of the tape. The time lags varied from one day up to three weeks, with most tapes being transcribed within ten days of the recording. Each tape was played on a Pioneer stereo cassette tape deck (CT-F2121) to record it in the computer using Sound Recorder software. This computer recording was then used to transcribe the subjects’ spontaneous speech into Microsoft Word 7.0. The slight loss of sound quality was compensated for by the ease of multiple replays of recorded material, since it was frequently necessary to replay sections several times, especially where speech was particularly fast or indistinct, in order to ensure accurate transcription. Speakers who used larger amounts of nonpropositional language were more difficult to transcribe, as the lack of semantic content meant that chunks of only as few as four or five words could be held accurately in the transcriber’s memory for long enough to type them.
The computer recording was played and replayed in short sections, until all the words were deciphered and transcribed. Occasionally it was simply not possible to interpret what the subject had said: in this case capital Xs were used to indicate the approximate number of words that remained unintelligible. At the end of the transcription of each section of the computer recording, that section was replayed as a preliminary accuracy check. If any errors were found, the section was played again, and amendments were made where necessary. After the entire interview had been transcribed from the computer recording, the transcription file was saved, to be checked again, on a later occasion, while listening to the original tape recording. The reason for doing this on a different day was to be able to approach the unintelligible words afresh, rather than with the preconceptions engendered by numerous unsuccessful attempts to decipher them.
As a further check on accuracy, two of the transcriptions were verified by a second person, resulting in greater than 99% concord. In instances where disagreements existed between the experimenter and the verifier, these were resolved by checking the original tape recording again, and amendments were made as necessary to the transcriptions, categorisations and word counts. It was concluded that the transcription procedure was sufficiently accurate.
7.3.1 Transcription protocol
The aim of the transcriptions was to create an orthographic representation of the spontaneous language produced, and the transcribed data included all hesitations, repetitions, reformulations, and incomplete utterances. The shortened forms common in fluent speech were represented orthographically e.g. cos, I’ll, he’d, gonna, wouldn’t’ve. Hesitations (also known as filled pauses), including any of a variety of sounds made while turn-holding or word-seeking, were represented as um, er, ah, pf, etc., and were treated as being part of the next utterance, rather than an utterance in themselves. Following normal practice (Saffran et al. 1989:446), capitalisation was avoided (except for proper and place names). The response to each stimulus item was started on a new line.
Prosody was of interest only in so far as it marked clause and utterance boundaries, or semantic content in a string that would otherwise be considered non-propositional (e.g. actually). Commas, exclamation marks and question marks were used to show prosodic contours which assisted in the construal of phrases and clauses, e.g.
[commas] and they’ve also been given the place to ride these mountain cycles, through a forest, something like Kielder Forest
[exclamation mark] there’s got to be more to it than Alan Titchmarsh!
[question mark] what do they call her? um? Delia Smith
Commas also marked the difference between you know, as a non-propositional element, and you know Æ introducing a clause. Emphasis and stressed words were marked by underlining. The end of an utterance was marked by a Z, attached to the utterance-final word, e.g. it’s er pre-empting something that’s happeningZ. This was done because utterance endings were in danger of being missed in Word (since there was no following capital letter) and it proved very difficult to see full stops against cell grid lines in an Excel spreadsheet.
punctuation mark
used to convey
comma
prosodic separation
exclamation mark
prosody: exclamation
question mark
prosody: question
underlining
emphasis
Z (attached to preceding word)
end of utterance
square brackets
repetition of stimulus question
curly brackets {name}
replaces information identifying subject
hyphen (attached to preceding word)
maze, or abandoned utterance
Table 8-3 Punctuation marks used in the transcriptions
Square brackets were used to mark the repetition, or partial repetition, of a stimulus question, as such a repetition was counted in the word count, but was not categorised. Curly brackets containing name i.e.{name} were used to replace any names of people or places, that could possibly be used to identify a subject. A hyphen attached to the end of a string indicated that the string was repeated or amended in a maze, or abandoned, e.g. Jo- John said- John said that he wou-.
7.4 Categorisation protocol: complexity
This section describes the categorisation criteria used in the study for those elements considered to represent complexity. A distinction has long been drawn in syntax between those elements which are obligatory (complements required by the subcategorisation frame of the verb), and those which are optional (adjuncts, whether phrasal or clausal, modifying some other element). The emphasis was therefore placed not on the syntactic category (e.g. noun, verb, adjective) but rather the sentential function (e.g. subject, complement, adjunct) of a constituent. The overarching principle was that it was only optional elements, which could therefore be omitted, that were counted as measures of complexity. Dialectal or non-standard forms were treated throughout in the same way as their equivalents in standard English.
7.4.1 Optional Complementiser Phrases
A clear distinction was maintained between obligatory, and optional Complementiser Phrases (CPs), since only optional CPs were counted. An optional CP was defined as a CP that did not function as an argument (i.e. not as subject or complement required by the verb’s sub-categorisation frame): namely adverbial clauses, relative clauses, or (in certain cases described below) clauses headed by co-ordination. Restrictive relative clauses clearly function as modifiers, and, although non-restrictive relatives may be regarded as being appositive, they, and sentential relatives, are nonetheless informationally optional. Only tensed clauses with overt subjects were counted.
7.4.1.1 Adverbial clauses
Adverbial clauses are tensed Inflection Phrases (IPs) with overt subjects, introduced by subordinating conjunctions (e.g. after, (al)though, as, because, before, once, since, unless, until, whereas, while, whilst) or by expressions of time (e.g. immediately that/Æ, the next time that/Æ, the minute that/Æ). Conditionality may be introduced by subordinating conjunction if (not replaceable by whether), by inversion of the subject and auxiliary, or by the use of the imperative: these clauses were counted as being optional CPs.
A tensed clause with an overt subject, introduced by a correlative such as as X as, so X as, more/less X than was counted as an optional clause e.g. [John sings as well [as his brother did]]. In such correlatives as either…or, neither…nor, whether…or, and not only…but (also), the second clause would be counted in any case under the criteria for co-ordination. Non-finite clauses with an adverbial function e.g. [Smiling broadly John waved to Mary], [John made her happy by waving] were counted as adverbials.
Phrasal (or compound) subordinators include as far as, as if, as soon as, as though, considering (that), except that, in case, in order that, in that, now (that), provided (that), so (that), supposing (that). Explicit rules distinguished subordinating conjunction so from Adverb Phrase (AdvP) so. Where so is replaceable by so that or in order that (in purpose clauses) or by so that or such that (in result clauses) it was counted as a subordinating conjunction introducing an optional CP. So was counted as an AdvP, introducing a new utterance, where it is separated prosodically, does not continue semantically from the previous utterance, or is replaceable by therefore or thus.
7.4.1.2 Relative clauses
Relative clauses function as modifiers, supplying additional optional information about one of the arguments of a clause or the entire clause itself, and were therefore counted as optional clauses. Both restrictive and non-restrictive clauses were counted as optional CPs.
Care had to be taken not to confuse relative clauses with subordinate interrogatives which function as arguments, be it subject e.g. [[Whether John had arrived] was the big question] or direct object e.g. [John asked [which bus he could get]], and are therefore not optional.
7.4.1.3 Co-ordination
Co-ordination was counted at no other level than that of a CP or a tensed IP with an overt subject. Co-ordination within an IP (i.e. both verbs falling under the scope of the same subject) e.g. [John bought some bread but didn’t eat it] was not counted.
A tensed IP, with an overt subject, introduced by but or or was counted as an optional CP: however, a tensed IP, with an overt subject introduced by and was counted as an optional CP only if it fell incontrovertibly within the scope of a higher subordinating conjunction. Co-ordination was counted only when the co-ordinated clause followed another clause: it was not counted when the co-ordinator appeared utterance-initially.
In cases of correlatives such as either…or, neither…nor, whether…or, and not only…but (also) the second clause, provided that it is a tensed IP with an overt subject, was counted as an optional CP e.g. [Either John should take his umbrella [or he should stay indoors]].
7.4.2 Adverb Phrases
AdvPs include general AdvPs e.g. happily, quickly, theoretically; AdvPs used adverbially e.g. perhaps, now, there; and degree AdvPs e.g. very, too, so. Adverbs which were nonpropositional automatisms e.g. basically, actually were not counted as adverbs. Multiple AdvPs were each counted: thus [John could very fortunately most probably almost always arrive early] contains seven AdvPs.
7.4.2.1 Comparison
Adverbs taking -er and -est were treated as though they took the adverbs more/most or less/least when expressing degrees of comparison. This therefore leads to a slight over-representation of the number of AdvPs.
Tensed clauses with an overt subject, introduced by correlatives were counted as optional CPs e.g. [Mary baked more biscuits [than John could eat]]; however correlatives introducing a phrase e.g. DP [taller [than John]], AP [less [than ecstatic]], AdvP [more rapidly [than carefully]], PP [more in sorrow [than in anger]] were counted as AdvPs.
7.4.3 Modifier Phrases
Modifier Ps include attributive adjectives, noun modifiers, and non-finite verbal participles. Attributive adjectives were counted as optional elements, but predicative adjectives, being complements, were not. Post-modifying adjectives were counted, but any modification of the adjective (by a PP) was not. When multiple attributive adjectives occurred, they were all counted, so, for example [a APnice APsoft APcomfy chair] counted as three ModifierPs.
Care was taken not to confuse adjectives with pre-determiners (e.g. all, both, double, half), determiners (e.g. any, each, every, his, John’s, some), demonstrative pronouns (e.g. this, those), or quantifiers (e.g. enough, a few, a little, many, much, several).
7.4.3.1 Comparison
Adjectives taking -er and -est were treated as though they took the adverbs more/most and less/least when expressing degrees of comparison. This therefore led to a slight over-representation of the number of AdvPs.
7.4.4 Adverbials
Adverbials convey such concepts as place, time, manner, reason, purpose, and means, and are typically realised as bare NPs/DPs or PPs. No distinction was made between adjunct adverbials, conjunct adverbials, and disjunct adverbials. Adverbials which were nonpropositional automatisms e.g. at the end of the day were not counted as adverbials.
Non-finite clauses with an adverbial function were counted as adverbials. The agent (“by”) phrase of a passive was categorised as an adverbial (since it is optional, and a PP in form). Adverbials in the form of AdvP were categorised as AdvPs.
7.5 Analysis of data : categorisation
Categorisation was done in Microsoft Excel 7.0 which allowed easy totalling of scores, along with calculations of instances per hundred words. In addition, these data could be saved as Excel 4 worksheets and thence pasted into SPSS 7.5, which was subsequently used for statistical analysis.
Before transferring a subject’s data into Excel, the total number of words was counted. It was possible to use the Word Count facility of Word, as it had previously been checked for accuracy by comparing its counts for twenty strings of various lengths with hand counts of the same strings: there was complete agreement, and it was concluded that counts using Word Count were sufficiently accurate.
count no.
hand count
count in Word
agreement?
1
5
5
ü
2
8
8
ü
3
11
11
ü
4
16
16
ü
5
19
19
ü
6
22
22
ü
7
24
24
ü
8
29
29
ü
9
32
32
ü
10
33
33
ü
11
37
37
ü
12
41
41
ü
13
45
45
ü
14
48
48
ü
15
50
50
ü
16
7
7
ü
17
14
14
ü
18
27
27
ü
19
36
36
ü
20
44
44
ü
Table 8-4 Comparison of word counts by hand and in Word
After the word count, a copy in Word was made of the transcription, and in this copy were inserted carriage returns, such that no line of text extended beyond about 6 on the on-screen ruler. Wherever feasible, phrase boundaries were the line-break points, as this made the categorisation conceptually easier.
Each subject’s data was pasted into a separate worksheet within an Excel workbook, and was labelled with the subject’s identification code. In Excel, the text formed the leftmost column on the worksheet (in a frozen pane), and the columns for the categorised elements followed to the right, scrolling across. It was first necessary to check that all of a subject’s data had been pasted successfully from Word into Excel, and then the column headings row was inserted.
The categorisation could then be started, working systematically, row by row, and inserting the number of occurrences of an element in the relevant column for each row. After the categorisation was completed, the total for each column was calculated (using the Sum function in Excel) at the end of the data in the worksheet. The file was then saved, to be checked on a subsequent occasion, since the categorisation process is attentionally demanding, and very liable to keystroke errors. After the categorisation had been checked, the totals for each subject were then pasted (using the Paste Links function) into a new worksheet, where calculations per hundred words were carried out. The calculations of the Index of Language Complexity (ILC) for each subject was carried out in the Excel spreadsheet.
The subject identifiers, scores per hundred words, and ILC scores were pasted to an Excel 4 Worksheet, and the subject data (age, gender, education, and scores on DB, AMIPB, and Aural Working Memory Span) added. This Excel 4 Worksheet was accessible to SPSS, which was subsequently used for statistical analysis.
The Combined Memory Score was calculated in SPSS, after the correlations between the working memory scores were established.
7.5.1 Index of Language Complexity
In the Excel spreadsheet, for each subject, the number of occurrences of each component element of complexity (i.e. optional CPs, adverb phrases, modifier phrases, and adverbials) was divided by the number of intelligible words produced by that subject, and the resultant number multiplied by 100, yielding a score per hundred intelligible words for each element. These scores per hundred intelligible words are therefore directly comparable between subjects, and are the scores reported in the results.
Each of the four component constituents of complexity (optional CPs, adverb phrases, modifier phrases, and adverbials) instantiates an aspect of complexity, yet none of them individually embodies complexity as a whole. The Index of Language Complexity (ILC) therefore consists of a summation of the scores per hundred intelligible words for the four component elements.
A subject’s score on the Index of Language Complexity was calculated by adding together that subject’s scores per hundred intelligible words for optional CPs, adverb phrases, modifier phrases, and adverbials. This was also calculated in the Excel spreadsheet.
7.5.2 Combined Memory Score
The raw scores for AMIPB were out of a total possible 56 points (dictated by the AMIPB scoring system). These scores were converted to a percentage by division by 56, and multiplication by 100. The raw scores for AWMS appear as .3, .6, or whole integers, as a result of the scoring system reflecting 1, 2, or 3 words successfully recalled at a given level. The highest possible score was 5, so the raw scores were converted to a percentage by division by 5, and multiplication by 100. These calculations were performed in the Excel spreadsheet. The two percentage scores were then comparable.
The Combined Memory Score consisted of an average of the standardised scores (z-scores) on AMIPB and AWMS, and was calculated by adding together the two component z-scores, and dividing by 2. This calculation was performed in SPSS.
7.6 Summary
This chapter gave information about the subjects in study 1, and detailed the methods used for the administration of the test interview, transcription, categorisation, and analysis of the data.
The next chapter reports the results of study 1.
8. Study 1: results
Before any analysis of the data was undertaken, tests of normality were performed, using various programmes in SPSS: the outcomes of these tests are reported below in section 9.1. There were no missing data in the data set. The relationships between the measures of working memory, working memory and complexity, and complexity and its constituents are reported in section 9.2.
The significance level was set at p=0.05: a level commonly used in psychology, which means that a Type 1 error (rejection of the null hypothesis when it is true) will occur on one in twenty occasions.
8.1 Descriptive statistics and tests of normality
Subjects were categorised according to four subject variables: age, sex, education, and occupation. Their working memory performance was measured by three different tests: the Adult Memory and Information Processing Battery Story Telling subtest (hereafter AMIPB), the Aural Working Memory Span (hereafter AWMS), and Digits Backward (hereafter DB). Standardised scores (z-scores) on AMIPB and AWMS were amalgamated to form the Combined Memory Score (hereafter CMS). These constitute the independent variables: subject variables are described first in section 9.1.1, followed by the variables for working memory in section 9.1.2.
The dependent variables are those for the subjects’ performance on the various measures of complexity, which are described in section 9.1.3.
8.1.1 Subject variables
The age variable is described first in section 9.1.1.1, followed by those for sex in section 9.1.1.2, education in section 9.1.1.3, and occupation in section 9.1.1.4.
8.1.1.1 Age
Table 9-1 Descriptive statistics for age
The age variable may be considered to be normally distributed, as neither the Kolomogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.1.2 Sex
There were 4 male subjects and 8 female subjects in study 1.
8.1.1.3 Education
subject
age
to age 16
further education
degree/ equivalent
1
18
ü
2
33
ü
3
18
ü
4
20
ü
5
68
ü
6
60
ü
7
54
ü
8
69
ü
9
40
ü
10
52
ü
11
58
ü
12
34
ü
total
5
3
4
Table 9-2 Subjects' ages and educational levels
8.1.1.4 Occupation
With the exception of the three students, subjects’ occupations were categorised according to the Standard Occupational Classification 2000 (Standard occupational classification 2000 2000), and are shown in Table 9-3.
occupation
number of subjects
student
3
unskilled
2
clerical and sales
2
professional
5
total
12
Table 9-3 Subjects’ occupations
8.1.2 Measures of working memory
The distribution of subjects’ scores on each working memory test is reported separately. Scores on DB are dealt with in section 9.1.2.1, those on AMIPB in section 9.1.2.2, those on AWMS in section 9.1.2.3, and scores on the amalgamated CMS in section 9.1.2.4.
8.1.2.1 Digits Backward
Most of the subjects scored either 4 or 5 on DB, which scores are regarded as reflecting normal ability, whereas a score of 3 is classified as borderline defective (Lezak 1995:367).
Table 9-4 Descriptive statistics for DB
The DB variable may be considered as normally distributed, since neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.2.2 Adult Memory and Information Processing Battery
One subject scored lower than 1SD below the mean.
Table 9-5 Descriptive statistics for AMIPB
The distribution of scores on AMIPB may be assumed to be normal, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.2.3 Aural Working Memory Span
Some scores were achieved by no subjects, whereas others were achieved by several subjects.
Table 9-6 Descriptive statistics for AWMS
The distribution of scores on AWMS may be considered normal, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.2.4 Combined Memory Score
The CMS was fairly successful in reflecting the scores on both AMIPB and AWMS, while also eradicating tied scores, since only two subjects achieved exactly the same score on CMS. (These two subjects also scored identically on each of AMIPB and AWMS.)
Table 9-7 Descriptive statistics for CMS
The distribution for CMS may be assumed to be normal, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.3 Measures of complexity
The descriptive statistics and tests of normality for the amalgamated complexity variable are given in section 9.1.3.1, followed by those for its constituent parts, namely: optional Complementiser Phrases in section 9.1.3.2; adverb phrases in section 9.1.3.3; modifier phrases in section 9.1.3.4; and adverbials in section 9.1.3.5.
8.1.3.1 Complexity
Table 9-8 Descriptive statistics for complexity
The complexity variable may be considered to be normally distributed, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.3.2 Optional Complementiser Phrases
Table 9-9 Descriptive statistics for optional CPs
The distribution of values on optional CPs may be assumed to be normal, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.3.3 Adverb phrases
Table 9-10 Descriptive statistics for adverb phrases
The distribution of values for adverb phrases may be considered to be normal, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.3.4 Modifier phrases
Table 9-11 Descriptive statistics for modifier phrases
The distribution of values for modifier phrases may be assumed to be normal, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.1.3.5 Adverbials
Table 9-12 Descriptive statistics for adverbials
The distribution of adverbials may be assumed to be normal, as neither the Kolmogorov-Smirnov nor the Shapiro-Wilk test achieves significance (p<0.05).
8.2 Relationships between variables
The study does not seek to perform experimental manipulation: rather, it examines pre-existing memory and linguistic variables, and looks for a relationship between them. It is, therefore, necessarily correlational in nature.
The correlations between the variables are described in this section, and the scattergrams showing these relationships are given in the appendix.
8.2.1 Choice of statistical tests
In order for the use of parametric statistics to be permissible, a number of assumptions must be met, videlicet: independence of data, interval or ratio scale of measurement, normally distributed data, and homogeneity of variance (Field 2000:37). Although the data are independent, and of interval or ratio level, the other assumptions underlying the use of parametric statistics could not be met. Despite having passed the tests for normality, many of the distributions suffer from considerable amounts of skewness and/or kurtosis. Homogeneity of variance, and hence bivariate normality, could therefore not be guaranteed.
For this reason, correlations between variables were tested using nonparametric Spearman’s rho, which has an efficiency of 91% compared with the Pearson product-moment correlation coefficient (Siegel & Castellan 1988:244). Parametric single-sample t-tests which were used to compare the AMIPB mean scores with those in the published norms (Coughlan & Hollows 1985:56-60). The AMIPB scores passed the tests for normality of distribution, so the assumptions underlying t-tests were not violated in this case.
8.2.2 Correlation matrix
The results of the Spearman rank-order tests of correlation are shown in the correlation matrix below.
Table 9-13 Correlation matrix of working memory and complexity
8.2.3 Organisation of the section
The relationships between the measures of working memory are described first, in section 9.2.4. These are followed by the relationships between complexity and the various measures of working memory in section 9.2.5. The relationships between complexity and its component constituents are shown in section 9.2.6.
8.2.4 Relationships between measures of working memory
Comparisons are made firstly between DB and AMIPB in section 9.2.4.1, and between DB and AWMS in section 9.2.4.2. Comparisons are then made between AMIPB and AWMS in section 9.2.4.3, The scores on AMIPB are compared with the published AMIPB norms in section 9.2.4.4.
The development of the Combined Memory Score is described in section 9.2.4.5, and comparisons are then made between AMIPB and CMS in section 9.2.4.6, and between AWMS and CMS in section 9.2.4.7. This is followed by a summary in section 9.2.4.8
8.2.4.1 DB and AMIPB
There was no significant correlation between DB and AMIPB (rho=0.524, N=12, p>0.05, two-tailed).
8.2.4.2 DB and AWMS
There was no significant correlation between DB and AWMS (rho=0.533, N=12, p>0.05, two-tailed).
Since DB did not correlate significantly with either AMIPB or AWMS, it was not included in the CMS.
8.2.4.3 AMIPB and AWMS
There was a significant positive correlation between AMIPB and AWMS (rho=0.781, N=12, p=0.003, two-tailed).
The CMS was constructed as an amalgamation of the standardised scores (z-scores) on AMIPB and AWMS, since they were highly correlated, in order to yield a unified measure of working memory which would reflect subjects’ performance on both tasks.
8.2.4.4 AMIPB compared with AMIPB norms
The mean of the raw scores on AMIPB was compared to the mean in the published norms, to see whether they differed significantly, and thus could be assumed to be drawn from different populations.
The first comparison was that of the study mean (n=12) with the mean of the norms whole sample (N=180). The observed whole sample mean did not differ significantly from the whole sample mean in the norms (t=0.162, df=11,p=0.874, two-tailed).
The study subjects were then split into four age groups, and the mean raw scores from these groups were compared with the norm means for the relevant age groups.
The 18-30 years age group mean score did not differ significantly from the score of the norm 18-30 years age group (t=0.138, df=2, p=0.903, two-tailed).
The 31-45 years age group mean score did not differ significantly from the score of the norm 31-45 years age group (t=-.173, df=2, p=0.879, two-tailed).
The 46-60 years age group mean score did not differ significantly from the score of the norm 46-60 years age group (t=-.259, df=3, p=0.813, two-tailed).
The 61-75 years age group mean score did not differ significantly from the score of the norm 61-75 years age group (t=1.046, df=1, p=0.486, two-tailed).
Since the observed means do not differ significantly from the means in the norms, the subjects in this study may be assumed to be drawn from the same population as that from which the subjects in the published norms had been drawn.
8.2.4.5 Development of the Combined Memory Score
It was desirable to formulate a single measure of working memory which would provide greater precision, by reflecting scores on more than one test, giving a wide spread of scores, and reducing the effect of tied scores. DB, scored as the maximum number of digits that can be recalled in reverse order, has possible scores of integers ranging from 2 to 8, and consequently tied scores are frequent. AMIPB scores can range freely between zero and the maximum possible score of 56, because, although 2 points are awarded for full recall of an idea, 1 point is awarded for partial recall. AWMS scores reflect discrete intervals of ability between 1 and 5, and consequently tied scores are a frequent occurrence. Scores on AMIPB and AWMS were translated into percentages, to give ease of comparability.
As was shown in the preceding sections, correlations were sought between the different working memory measures. DB was found not to be significantly related to either AMIPB or AWMS, but scores on AMIPB and AWMS were significantly correlated (rho=0.781, N=12, p=0.003, two-tailed). AMIPB scores were found not to differ significantly from those in the published norms, which act as a validating “gold standard”. It was therefore decided to amalgamate the scores on AMIPB and AWMS to form a Combined Memory Score, computed as 50% standardised score (z-score) on AMIPB plus 50% standardised score (z-score) on AWMS.
The scores on AMIPB, AWMS, and CMS for each of the subjects are shown for comparison in Table 9-14.
subject
AMIPB
AMIPB
z-score
AWMS
AWMS
z-score
CMS
1
78.57
.80
86
1.65
1.23
2
96.43
1.6
80
1.29
1.49
3
58.93
-.16
66
.46
.15
4
75.00
.62
66
.46
.55
5
78.57
.80
66
.46
.63
6
78.57
.80
66
.46
.63
7
46.43
-.77
52
-.36
-.57
8
55.36
-.33
52
-.36
-.35
9
30.36
-1.56
52
-.36
-.96
10
39.29
-1.12
46
-.72
-.92
11
69.64
.36
40
-1.07
-.36
12
39.29
-1.12
26
-1.90
-1.52
Table 9-14 Comparison of AMIPB, AWMS, and CMS scores
The CMS reflected scores on more than one test, achieved a broad spread of scores, and almost entirely eliminated tied scores. (The two subjects with the same CMS score had scored identically on both AMIPB and AWMS.)
8.2.4.6 AMIPB and CMS
There was a significant positive correlation between AMIPB and CMS (rho=0.961, N=12, p<0.0005, two-tailed).
8.2.4.7 AWMS and CMS
There was a significant positive significant correlation between AWMS and CMS, (rho=0.905, N=12, p<0.0005, two-tailed).
8.2.4.8 Summary
Since DB did not correlate significantly with either AMIPB or AWMS, DB was not included in the combined measure. The CMS was therefore a 50:50 amalgamation of AMIPB and AWMS.
8.2.5 Relationship between complexity and working memory
Once the CMS was established, it could then be used to probe the measures of complexity.
8.2.5.1 Index of Language Complexity
It was necessary to define the relationship between the four component elements that were to be combined to form the complexity variable, the score on which constitutes the Index of Language Complexity (ILC). There was no a priori reason to presume that any one of the four component elements of complexity was more or less important than the others, and there was the additional consideration that the combined complexity variable should, ideally, pass the tests for normality of distribution.
A variety of different ratio weighting combinations for the four components was tried out heuristically, using weightings ranging from 40% through to 10%, checking for correlation with CMS and for normal distribution. The ratio weighted scores therefore consisted of the sum of a proportion of the score for each element. The disadvantage of using ratio weightings was that the combined scores were very low, with only a very small range, typically with minima about 2.5, maxima about 4.5, and range about 2. In view of this, and because there was no principled reason not to combine the four elements in equal measure, it was decided to straightforwardly add together the four component elements as a total score to form the complexity variable. This had the advantage firstly of reflecting the true frequency of occurrence of each of the component elements (i.e. the number of times per hundred intelligible words the elements appeared), and secondly of increasing the scores (minimum 9.66, maximum 18.62) and range (8.96). This is exemplified by the scores for one subject, in Table 9-15.
variable
score
optional CPs
5.355
adverb phrases
6.403
modifier phrases
3.027
adverbials
3.143
25:25:25:25 ratio weighting score
4.482
totalled complexity score
17.928
Table 9-15 Example of complexity scoring
The complexity variable, representing the score on the ILC, therefore consisted of the summation of the four component elements. Its correlation with the various measures of working memory was then investigated.
The relationship between complexity and AMIPB in section 9.2.5.2, that between complexity and AWMS in section 9.2.5.3, and that between complexity and CMS in section 9.2.5.4.
8.2.5.2 Complexity and AMIPB
There was a significant positive correlation between complexity and AMIPB (rho=0.794, N=12, p=0.002, two-tailed).
8.2.5.3 Complexity and AWMS
There was a significant positive correlation between complexity and AWMS (rho=0.782, N=12, p=0.003, two-tailed).
8.2.5.4 Complexity and CMS
There was a significant positive correlation between complexity (ILC) and CMS (rho=0.820, N=12, p=0.001, two-tailed).
8.2.6 Relationship between complexity and its constituents
The internal validity of the variable is shown by the correlation of its component elements with the combined measure.
The relationship between complexity and optional CPs is shown in section 9.2.6.1; followed by that between complexity and adverb phrases in section 9.2.6.2; that between complexity and modifier phrases in section 9.2.6.3; and that between complexity and adverbials in section 9.2.6.4.
8.2.6.1 Optional CPs and complexity
There was a significant positive correlation between complexity and optional CPs (rho=0.860, N=12, p<0.0005, two-tailed).
8.2.6.2 Adverb phrases and complexity
There was a significant positive correlation between complexity and adverb phrases (rho=0.762, N=12, p=0.004, two-tailed).
8.2.6.3 Modifier phrases and complexity
There was a significant positive correlation between complexity and modifier phrases, (rho=0.818, N=12, p=0.001, two-tailed).
8.2.6.4 Adverbials and complexity
There was no significant correlation between complexity and adverbials (rho=0.427, N=12, p=0.167, two-tailed).
8.3 Summary
This chapter reported the descriptive statistics for each variable, and the inferential statistics showing the relationships between variables. The development was described of the two amalgamated measures, the Combined Memory Score (CMS) and the Index of Language Complexity (ILC).
The discussion of what was learned as a result of study 1 follows in the next chapter.
9. Study 1: discussion
The first section (10.1) summarises the main results of study 1, and the import of those results is discussed under the headings of working memory tests (section 10.2), the Index of Language Complexity (section 10.3), and complexity and working memory (section 10.4).
Matters arising from study 1 are dealt with in the following sections: test formulation in section 10.5, elicitation stimuli in section 10.6, and the analysis of data in section 10.7. The chapter ends with the conclusions drawn from the study.
9.1 Main results
Although all the variables passed the Kolmogorov-Smirnov and Shapiro-Wilk tests for normality of distribution, it was nonetheless decided to use nonparametric statistical tests, because five of the distributions displayed considerable kurtosis (>-1), and graphical tests of normality showed that the distributions of several variables were underlyingly non-normal.
9.1.1 Working memory
AMIPB and AWMS were significantly correlated (rho=0.781, n=12, p=0.003, two-tailed), whereas neither of them correlated significantly with DB. For this reason, it was decided not to include DB in CMS, the amalgamated memory measure, and CMS therefore consisted of an average of the z-scores on AMIPB and AWMS.
The significant correlation between AMIPB and AWMS gave CMS internal consistency. Additional evidence of the internal consistency of CMS came from the significant correlations between AMIPB and CMS (rho=0.961, n=12, p<0.0005), and between AWMS and CMS (rho=0.905, n=12, p<0.0005).
The scores on AMIPB were compared with the AMIPB norms (Coughlan & Hollows 1985) and neither the whole sample nor any age group was significantly different from the published norms. The comparison with this “gold standard” gave criterion validity (Abramson 1990:154) to the AMIPB scores in this study. Since AMIPB correlated significantly with both AWMS and CMS they, in turn, both achieved criterion validity.
9.1.2 Complexity
The internal consistency of the complexity variable (the scores on the Index of Language Complexity (ILC)) was demonstrated by the correlations between the four constituent components and complexity as a whole. There were significant correlations between complexity and three of the four components: optional CPs (rho=0.860, n=12, p<0.0005), adverb phrases (rho=0.762, n=12, p=0.004), and modifier phrases (rho=0.818, n=12, p=0.001). The correlation with adverbials was non-significant, but indicates a tendency in the right direction. Adverbials were kept as part of the ILC, because the inclusion of the variable gave extra information, and lent extra precision to the measure.
9.1.3 Complexity and working memory
Complexity (ILC) was significantly correlated with CMS (rho=0.820, n=12, p=0.001). If it were replicated, this relationship between complexity and working memory would constitute the primary result of study 2.
Complexity was also significantly correlated with the constituents of CMS, correlating with both AMIPB (rho=0.794, n=12, p=0.002) and AWMS (rho=0.782, n=12, p=0.001). It was therefore clear that both AMIPB and AWMS were contributing to the relationship with complexity.
9.2 Working memory tests
Each of the WM tests is discussed separately in this section: first DB, then AMIPB, AWMS, and finally the amalgamated measure CMS.
9.2.1 Digits Backward
As a result of having undertaken study 1 as a pilot, it was decided that DB would no longer be used as one of the tests of working memory. The results show that DB did not correlate significantly with either AMIPB or AWMS, which implies that DB was not measuring the same construct as were AMIPB and AWMS. Neither did DB correlate significantly with complexity. Consultation of a table of critical values for Spearman’s rho (Sheskin 2000:962) shows the critical value of rho for N=12 at a significance level of .05 to be .587. The correlations of DB with AMIPB, AWMS and complexity did not achieve this value.
Apart from that, there are a number of problems inherent in DB. It is easy for the subject to use some form of memory other than the phonological loop to encode the numbers. Such forms might potentially include such things as mental imagery of the numbers in their written form or as they appear on a clock face or telephone keypad, tactile memory of fingers representing numbers pressed against something, knowledge of number representation in British Sign Language, or mental associations with birthdays, house numbers, or golf greens. Curiously, this problem does not appear to be reported in the literature and is seemingly ignored by neuropsychologists, who very commonly use Digit Span (i.e. DF and DB) for measuring the span of immediate verbal recall (Lezak 1995:357).
Another problem with DB as a test, is that some subjects reported having tried to find a pattern in the digits presented to them, and subjects may therefore distract themselves from the task of simply remembering the digits. If there were a pattern, this could be a good strategy to aid recall (as a standard mnemonic practice) but, as the digits are quasi-random, it is counter-productive, and the additional self-imposed pattern-seeking task may lead to subjects appearing to have a lower level of ability than is actually the case. This is also absent from the literature.
DB was, for these reasons, no longer regarded as part of the test, to be analysed. It was, nonetheless, left as part of the interview format, because of the way in which the data was collected. There was a time constraint on the availability of the people attending Adult Basic Education classes, three of whom were part of study 1, and, in order to have access to the ABE subjects (for study 2), the test interview had to be administered as it stood at that time, which included DB, as not all the study 1 results had been analysed at that time. In order to maintain the equivalence of the test interview for all the subjects, DB was retained for the other subjects (in study 2), although the data resulting from DB were not analysed (and are not reported in study 2).
9.2.2 AMIPB
The AMIPB (Coughlan & Hollows 1985) is a standard neuropsychological test battery, which is in common clinical use in the north east of England, among neuropsychologists and speech and language therapists. AMIPB has therefore achieved consensual validity (Abramson 1990:153-4), in being accepted by experts as a test of working memory.
The scores on AMIPB of the subjects in study 1 did not differ significantly from those in the published norms (Coughlan & Hollows 1985). AMIPB can therefore be regarded as a “gold standard” (Abramson 1990:154) by comparison with which criterion validity is achieved. Both AWMS and CMS were thus validated by their significant correlations with AMIPB.
Scores on AMIPB could be any integer between zero and 56 (the maximum possible), because zero, one or two points were awarded for each idea recalled. Consequently the percentage scores, used in this study, could also range virtually continuously between zero and 100%.
9.2.3 Aural Working Memory Span
Since the subjects in study 1 had a wide variety of educational achievement, it was anticipated that there could be both floor and ceiling effects, and so the two sentence level was included in the scoring, although some previous WM span studies had treated the two sentence level as practice and excluded it from the scoring. One of the study 1 subjects scored only 1.3 (26%) on AWMS, being able to recall the sentence-final words of only one set at the two sentence level. Her AMIPB score was below the 25th percentile in the norms for her age, although her DB was normal. This subject, however, had a month-old baby as well as a school age child, and was possibly suffering from sleep deprivation.
A disadvantage of the AWMS scoring system, of stopping the test after two consecutive failures, was the “sudden death” aspect, in that a brief lapse of attention, or perhaps a change in strategy, could lead to consecutive errors and thus the cessation of the test, resulting in a score that was lower than a subject’s true ability. The alternative, however, would have meant asking subjects to attempt the test right through to the end of the five sentence level, which would have presented many subjects with a prolonged and demotivating experience of failure.
Another disadvantage of AWMS was the number of tied results it generated, as a result of its quantised scoring, but this is inevitable in any test which has pre-specified levels of ability to be achieved. It was partly in the attempt to eradicate tied scores that the CMS was formulated.
9.2.4 Combined Memory Score
The CMS score was composed of an average of standardised scores (z-scores) on AMIPB and AWMS. This measure proved robust, and operationally effective. The AMIPB and AWMS scores were significantly correlated with each other, and with CMS, and therefore CMS was internally consistent as a measure of working memory.
The aims of this amalgamation of scores into CMS were to reflect scores on more than one WM test, to eradicate tied scores, and to achieve a better spread of results. CMS was almost completely successful in eliminating tied scores. Only one tied result remained in CMS, and that was the consequence of two subjects scoring identically on both AMIPB and AWMS. The AMIPB component introduced a free-ranging element to the CMS score, and consequently CMS showed the same spread of scores as AMIPB (i.e. one tied score), and achieved a better spread of scores than those on AWMS, where four subjects had scored 66%, and three 52%.
9.3 Index of Language Complexity
One of the aims of this study was to produce an objective method of quantifying complexity in spontaneous language. The use of numbers to describe language performance is sometimes considered distasteful, and has been criticised for losing information in the reduction of behaviour to numbers (Hughes et al. 1992:3). The obvious problem with any single numerical score lies, of course, in its very singularity, in that it will not convey which combination of sub-scores led to the final score, and any given score inevitably may represent a number of different profiles. However, it is highly desirable to have a numerical score that can be compared across subjects, and across studies, or possibly across time for the same individual. A quantified measure is also necessary for comparison with other variables, such as working memory.
The ILC was formulated as a summation of the scores, per hundred intelligible words, on each of the components: optional CPs, adverb phrases, modifier phrases, and adverbials. Ratio weightings had been tried out (as was described in the study 1 results section) but the simple addition was found to be operationally robust, giving a wider range of scores than did the ratios, and a better correlation with CMS for the combined variable than with the components individually.
Each of the individual components has a positive relationship with complexity as a whole, in three of the four cases giving significant correlations. Each of the four component elements provides additional information, and lends extra precision to the ILC measure as a whole. The ILC was therefore internally consistent as a measure of complexity.
The evidence in favour of these four component elements as the instantiation of complexity in language production was presented in earlier chapters. Each of the four components represents a locus of difficulty in language acquisition and/or disorders of various kinds. There are syntactic arguments for their difficulty, as they involve adjunction (under the Minimalist Program (Chomsky 1995)), or additional checking operations by attaching to functional categories (Cinque 1999). Computational considerations must also apply, in that their simple presence (no matter how they are syntactically represented) makes an utterance longer, and therefore more costly to process (Levelt 2000).
9.4 Complexity and working memory
Study 1 showed a significant correlation between complexity and working memory: this could, however, have been a result of the way in which these measures were constructed, since this was, of necessity, a circular process of refinement. For this reason the analysis arrived at in study 1 needed to be tested as a prior hypothesis, on a new independent data set, as was subsequently done in study 2.
It was important to have subjects from a mixed group, with an assumed wide range of working memory and language ability. (The last three subjects added to study 1 came from the Adult Basic Education classes, and they provided the lower end of the range of WM scores.) Since all the data for each subject was collected in one session, it was impossible for the experimenter (E) to remain completely blind to subjects’ WM scores when analysing their data for complexity, because she had administered the WM tests to the subjects, transcribed the tapes, and scored the WM tests. In mitigation, it should be pointed out that the WM tests were scored as part of the transcription process (some time before categorisation took place), and that the WM scores were kept in a different spreadsheet file from the data which was to be categorised for complexity. In the initial stages of categorisation, E would have had specifically to have looked for the subjects’ WM scores, in order to know them before categorising the data. (This was not done.) In the later stages of the development of the categorisation analysis, of course, E had become very familiar with the relative scores of the subjects, since she had performed numerous calculations on them.
Nonetheless, the categorisation process should be regarded, at worst, as semi-blinded, since, although E might know a subject’s WM scores, the objective scoring of syntactic elements (as detailed in the categorisation protocol, in the method chapter) ensured that complexity scores could not be faked. This is another instance of the superiority of the count of elements per hundred intelligible words over per utterance, since a degree of subjectivity can all too easily creep into judgements of where utterances begin and end.
The first requirement in the analysis was to formulate a single measure of WM which would be internally consistent, so that this putative measure could then be used to probe the measures of complexity. The CMS answered this requirement, and it was used to check for relationships with complexity elements. It was assumed, throughout the study, that there would be individual variation in the amount of complexity produced. Indeed, elements that did not vary between subjects were ruled out from consideration as components of complexity. The four components included in the ILC therefore showed evidence of variation between subjects.
9.5 Test formulation
The overall point of the test interview was to elicit sufficient output to provide a reasonably representative sample of a subject’s spontaneous speech. It is freely acknowledged that such a sample would not be truly representative of the subject’s normal output, because of the artificiality of the test situation, and the monologic nature of the subject’s replies. Had the interviewer participated in a dyadic interaction, the subjects might have produced more normal conversational speech, but this study was concerned not with pragmatic skills or conversational dynamics, but rather with the amount of complexity produced by the subject. The additional task of having to compete for the conversational floor was therefore removed by the interviewer producing only phatic communication (e.g. mmm, mm?).
The mere fact of being recorded can be slightly unnerving, being asked to perform memory tests is stressful, and having to sign a consent form, along with the slight suspicion attaching to the public perception of psychology could have led to subjects being apprehensive, especially at the start of the test. As Lezak points out (1995:141), anxiety can lead to mental slowing, scrambled or blocked thoughts and words, and memory failure, and is not conducive to representative behaviour. Care was therefore taken to put subjects at their ease before the test interview, and to be as informal as possible during it. It must be borne in mind, however, that anxiety may still have diminished some subjects’ performances, on memory tests, in spontaneous speech, or both, such that they performed at less than their optimal ability.
The amount of time taken by the test interview had to be taken into account, especially since subjects were giving their time freely. The need to include memory tests within the format had to be balanced against the number of stimuli to elicit speech. The final version of the test took approximately 20-25 minutes, depending on an individual subject’s memory ability and prolixity. This appeared to be acceptable, as no subjects complained about it taking too long.
9.6 Elicitation stimuli
It is possible to elicit speech by simply asking a subject to talk about anything he wishes (Morice & Ingram 1982:14). This may be acceptable in a hospital setting where people may well be bored and consequently glad to have someone to talk to, however, there would be no comparability between subjects of the topics discussed, and hence some participants may address topics that inherently encourage more complex language than others. It was important, therefore, to formulate a set of stimuli which were the same for all participants, to ensure that everyone was presented with equally challenging tasks, and equal opportunities to produce complex language.
All the stimuli were presented in the same order to every participant (as would be the case in any neuropsychological test) because the study did not attempt experimental manipulation, but rather the observation of pre-existing variables under natural conditions. Not all subjects answered every question, because, especially in What & Why, some subjects did not know a particular saying, or said they had no idea why a particular state of affairs pertains.
There was a fine balance to be struck: questions should not entail anything other than very basic general knowledge, yet they should be interesting enough to challenge more intelligent subjects, but not be so difficult that they caused less intelligent subjects to lose face by being unable to answer. The nine subjects from study 1 who undertook the NART all scored as average or above average intelligence (with presumed IQs from 108 to 124), so it may be the case that some of the What & Why questions were slightly too demanding for less intelligent subjects.
One of the questions in What & Why, Why are people [who are born deaf] usually unable to talk?, contained a centre-embedded clause, and was therefore difficult for subjects to process. This problem was considered, but the alternative wordings that suggested themselves were either scarcely an improvement, or excessively verbose (cf. If people are born deaf, why are they usually unable to talk?, Some people are born deaf, and usually they’re unable to talk : why is that?) The question was kept in the interview, despite its difficulty, because it was effective at eliciting elements of complexity, and care was taken in administering this question to pause at the clause boundaries, and to monitor the subject to ascertain comprehension. Pausing at syntactically and prosodically appropriate places in order to allow time for processing is helpful to older adults, increasing recall performance significantly (Wingfield 2000:192). During the administration of all test tasks, pauses were made in relevant places, to ensure that the subject had processed the instructions, and understood the task.
The questions in the test had been devised with a view to inviting the production of optional CPs during the explication. A question that asks why… almost requires an answering because…, and describing the meaning of a saying (e.g. when the cat’s away the mice will play) involves setting up the situation in which it is relevant (e.g. if/ when the boss is away…). There was no guarantee of success in eliciting a particular form, however. The question what make the ideal friend? generally elicited a response such as someone who…, but sometimes evoked a list of qualities (e.g. honesty, trust…). Although an equal opportunity to produce complex language was presented to each subject, there was nothing to compel the subject to take advantage of that opportunity. The assumption of this study is therefore that the production of an utterance of lower complexity was motivated by the constraint of limited working memory capacity, which would indicate that the subject was unable to both produce a more complex utterance and simultaneously handle the concepts involved.
There was considerable variation between subjects with regard to the kind, and sophistication, of the story they produced. Story telling demands that the speaker allocate his resources, because it comprises three tasks, requiring him simultaneously to produce a narrative structure, present the story both grammatically and coherently, and monitor the hearer’s comprehension and interest (Wingfield & Stine-Morrow 2000:400). In some cases there was characterisation, development of a situation, and a resolution; whereas in others the story was extremely rudimentary, amounting to little more than a brief physical description of the picture. It had been planned originally to divide up the data for each subject, in order to compare performance in the narrative style of Story Telling versus the expository style engendered by answering questions. This had to be abandoned because some stories were so short, and so minimal structurally, that they could not be considered to give a representative sample of language.
Another problem with the Story Telling task was that a subject could amass considerable numbers of modifier phrases through the reiteration of a phrase such as the little boy, describing a protagonist in the story. Although there is still the requirement for agreement between these elements, assuming that the phrase remains activated, repetitions may not represent the same computational cost as the original formulation. The choice lay between not counting any reiterations of the same phrase within the story, counting them but only as a fraction of a point, or counting all reiterations as normal. None of these options was satisfactory, but the decision was made to count each reiteration, and this may therefore have led to a slightly inflated complexity score for some subjects.
The pilot test showed that the tasks that were included in the final form of the test interview were generally effective at eliciting complexity elements from the subjects, despite the occasional poor performance on the Story Telling task.
9.6.1 Corpus size
It is desirable to have a fairly large data set of spontaneous language, in order to have a representative sample of output: the difficulty lies in deciding how large it should be. Analyses of data from people with aphasia have used samples as small as 150 words (in the Quantitative Analysis of Agrammatic Production (Saffran et al. 1989)); it has been suggested that a minimum sample size of 350 words is necessary in order to compute a lexical type-token ratio (Perkins 1994:329); and it has been claimed (Brookshire & Nicholas 1994) that sample size has a direct effect on the reliability of an analysis, and that samples of 300-400 words give the best test-retest reliability. It was therefore decided that minimum permissible sample size for this study should be set at 400 words: so that if fewer than 400 words were produced by a subject, that subject would be excluded from the study. The samples elicited in study 1 ranged from 752 to 2538 in length (mean 1274, SD 518). The median was 1112, and the interquartile range 719. As may be seen from these figures, the distribution was skewed, with one subject producing a very high number of words. With a larger sample of subjects, this would be less of a problem, since in a larger sample estimates of the mean would be more precise and the sampling error (or standard error) would be lower (Coolican 1994:211).
People vary greatly in how loquacious or laconic they are, as an inherent characteristic, and it is likely that such considerations as mood, tiredness, anxiety or busyness also affect the amount of speech people uttered in response to the stimuli. The subject who produced the highest number of words was also very garrulous during the conversation following the test, whereas the subject who produced fewest words was an academic, probably aware of the advent of appointments subsequent to the test interview. A subject’s garrulity or taciturnity would not affect his complexity score adversely, because the elements were calculated per hundred intelligible words, and therefore the measure was proportional.
9.7 Analysis of data
The categorisation analysis that was finally implemented in study 1 was the result of repeated passes through the data, using successively modified versions of the categorisation protocol, in order to establish the level of analysis at which the elements comprising complexity could best be described.
Theoretical considerations had to be balanced against such pragmatic factors as which elements could be reliably elicited: for example, no practicable means of eliciting anaphoric reference at varying distances from the referent suggested itself. Another factor was that elements to be counted as comprising complexity should actually occur sufficiently frequently in subjects’ spontaneous speech to be measurable: for example, centre-embedded relative clauses are rare in normal spontaneous speech. Another factor was that, although there was assumed to be variation between subjects, the complexity elements should be produced by all or at least the majority of subjects. For example, the lexical item nevertheless may be considered to develop late in language acquisition, and therefore be conceptually complex, but it might be produced by only one subject in ten. There would be little point in creating an analysis that was optimal from the linguistic point of view, but that was unworkable because the elements it counted were impossible to elicit reliably, were vanishingly rare, or were produced by only a small minority of subjects.
9.7.1 Data handling
Many lessons were learned the hard way, by using an unsuitable procedure first, and refining the process in the light of experience. An example of an unsuitable procedure was trying to count the overall depth of embedding. At first this was done in Word, by placing a number (representing the incremented count of embeddings within an utterance) at the beginning of each embedding, and going through the Word file, manually counting (as five-bar gates on a piece of paper) how many embeddings there were of each depth within a subject’s output. This was extremely slow, and very error-prone, since a moment’s inattention could mean losing track of whether any given instance had been counted or not (and therefore necessitated a recount of the whole file). The suggestion to use Word’s Edit-Replace facility helped greatly, but it became apparent that embeddings could best be counted in an Excel spreadsheet, on which it was clearly visible whether an embedding had been counted or not, and which enabled both totals and sub-totals to be produced automatically.
In the earliest stages of the development of the categorisation protocol, the spreadsheet was over thirty columns wide, because so many disparate elements were being counted. Where such high numbers of columns are in use, there is necessarily a higher likelihood of mistakes being made, due to keystroke errors, or lapses of attention. A balance had to be struck in the analysis between completeness and workability and, indeed, efficacy. Although it would have been possible to count every element, at every level of analysis, there would be little point in so doing, if no useful information was gained thereby. For example, it was decided at an early stage that counting verb forms (e.g. auxiliaries, tensed, and participial forms) was not producing the desired effect of differentiating between subjects of varying ability, so the verb form count was discontinued. This also had the beneficial effect of removing eight columns from the spreadsheet, and going some way towards streamlining the analysis.
During the formulation of the analysis many aspects came under consideration, and the influence of the various published analyses of spontaneous speech and of complexity should not be underplayed. In some cases this pertains to methods to be emulated or adapted: in others, to methodological pitfalls to be avoided.
9.7.2 Units of analysis
The first question to be addressed in quantifying language was what the basic units were to be: sentences, utterances, text units, or words. In none of the published analyses surveyed for this study were the implications of this decision addressed.
9.7.2.1 Sentences
The sentence is frequently taken to be the basic unit of analysis, despite the fact that it is notoriously difficult to define (McArthur 1996:836), largely because of the issue of grammaticality. A sentence is a syntactical entity, and is affected by considerations of grammaticality, as distinct from an utterance, which occurs in a context, and is judged on its acceptability (Burton-Roberts 1986:102). The notion of grammatical sentence does perhaps have a place in analyses directed towards speech and language therapy, where it is important to know whether or not a speaker is capable of producing the full complementation of a verb, or in studies of speech from people with schizophrenia, where loss of subject-verb agreement appears to be symptomatic. It is not, however, relevant to normal speech interactions, which rely to a large extent on pragmatic discourse phenomena for interpretation. Sometimes an analysis (e.g. Hirschman 2000:258) uses only complete sentences as data. This is very wasteful of data, and may also lead to biased results, as many of the elements that the analysis seeks may well be present in incomplete sentences. It may also be the case that what are referred to as sentence boundaries are in reality utterance boundaries: for example, those generated by the criteria of using syntax, intonation and meaning, in that order (Morice & Ingram 1982:14).
9.7.2.2 Utterances
The notion of utterance seems more useful, until a strict definition is attempted. An influential definition is that given by Shewan (1988:124), where the criteria are the completeness of a thought; a connected grouping of words; and separation by content, intonation, and/or pausing. Although this is a highly plausible description, the perception of each element within it must necessarily be subjective. An utterance containing a greater amount of complexity will present a greater WM costs, and will consequently be more likely to be left unfinished and abandoned. In an analysis using only complete utterances, the amount of complexity would therefore be underestimated.
A more inclusive definition is given by Kemper et al. (1989:53), where an utterance may be a “conventional sentence”; an incomplete sentence, rephrasing or revision; an addition following a pause; or a lexical or non-lexical filler. This has the benefit of greater inclusivity, and requires fewer elements to be discarded, but nonetheless remains open to the major disadvantage of using utterances as the basic unit, namely that subjects may produce an identical number of words but different numbers and different lengths of utterances. In a count of elements per utterance, where only a specified number of utterances are analysed, the length of utterances makes a critical difference, as longer utterances are more likely to contain elements counted as complex.
9.7.2.3 T-units
An alternative unit is the text unit, which may be lexical, phrasal, or clausal (Edwards & Knott 1994:56).It was not considered helpful to have such disparate elements all regarded as a basic unit of analysis. Another unit is the “minimal terminable unit” or T-unit (Hunt 1970), which appears to achieve the impossible, as it is claimed to be not only a main clause plus any subordinate clause or nonclausal structure attached to or embedded in it; and the shortest unit grammatically allowable as a sentence; but also intermediary between the clause and the sentence (Hunt 1970:4-5). Apart from the problem of this muddled definition, the T-unit was designed for use with written material, which is not subject to the same working memory constraints as is spontaneous speech, and would therefore be expected to exhibit more complexity. Because T-units were originally for written data, it is unclear how mazes or abandoned utterances should be treated under a T-unit analysis.
9.7.2.4 Words
A problem with using words as the basic unit of analysis was that it would clearly be nonsense to talk about the number of optional Complementiser Phrases per word. This absurdity was avoided by using a denominator of 100 intelligible words. Unintelligible words were not included in the word count, because, by definition, they remained unidentifiable and therefore unquantifiable. (Their presence was represented in transcriptions by Xs, but the number of Xs expresses only a best guess as to how many unintelligible words there were. This was described in the transcription section of the methods chapter.)
The disadvantage in using the 100 intelligible words unit was the loss of comparability with studies that use sentence or utterance counts. This seemed a small price to pay, however, because the many different definitions of sentences or utterances already diminish any comparability between those studies. One of the benefits of using the 100 intelligible words unit as the denominator was that every intelligible word produced was available for analysis, with no data being discarded because it was part of an utterance that was incomplete, or contained an unintelligible word. Another advantage of using the 100 intelligible words unit was the avoidance of potential subjectivity in the construal of where an utterance begins and ends. A further benefit was that by having a proportional score, it controlled for the variable number of words per subject, giving direct comparability between samples of different sizes.
9.8 Conclusions
Study 1, as a pilot study, was crucial to the refinement of the working memory measure, to the distillation of the conceptualisation of complexity, and to the development of the methodology for elicitation, transcription, and analysis of the data.
The Combined Memory Score was formulated as an internally consistent amalgamation of scores on the AMIPB, a pre-existing and ecologically valid test of memory, and the AWMS, newly-devised for this study, as a version of the working memory span paradigm, which had been used in previous studies of working memory and language comprehension. The CMS gives a single score for working memory against which complexity may be measured.
Although there had always existed in the mind of the investigator a theoretically based, albeit somewhat nebulous, concept of those elements instantiating complexity, it required the empirical investigation of study 1 to produce a rigorous and detailed definition. The Index of Language Complexity provides an internally consistent and objective measure of what constitutes complexity in language production.
The interview developed in study 1 comprises a set of stimuli which are effective in eliciting complex language in sufficient quantity to be a representative sample of a subject’s output. Through piloting in study 1, standardised methods were arrived at for transcribing, categorising, and analysing the elicited spontaneous speech data.
The measures, developed in a circular process of refinement during study 1, were subsequently tested on a new, larger, and independent data set in the replication study, study 2, which is the topic of the next chapter.
10. Study 2: introduction
The purpose of a pilot study is to try out a prototype on a small sample to discover snags in procedures, or to develop a workable measuring instrument (Coolican 1994:21). This indeed was the intention of study 1, the pilot study, described in the preceding chapters.
As was set out in chapter 5, study 1 served several purposes. Firstly, it was undertaken to discover what would constitute a viable test stimulus to elicit complex language (described in chapter 6). Secondly, it provided a means of refining a standard combined measure of working memory (also discussed in chapter 6), and of devising an objective method for quantifying those elements that constitute complexity in language production (presented in chapter 7). Thirdly, it served to establish a standard, reliable, and replicable methodology for the collection, transcription, categorisation and measurement of spontaneous speech data (detailed in chapter 8). Fourthly, it provided evidence of a continuum of ability in both working memory and the production of complexity in spontaneous language (reported in chapter 9). Fifthly, study 1 indicated the presence of a significant relationship between working memory (measured by the CMS) and complexity (measured by the ILC), and this was discussed in chapter 10.
Because of the exploratory nature of study 1 (undertaken as a pilot) and the practicalities of multiple re-analyses of the data in order to optimise the methodology for the categorisation of complexity, only a small number of subjects were used in study 1. Nonetheless, the study suggested the presence of inter-individual variation in the production of complex language, on a continuum of ability. With N=12, and an alpha level of .05 (two tailed), the critical value for Spearman’s rho is .587 (Sheskin 2000:962), whereas the correlation between CMS and complexity in study 1 was .820 (p=.001). Study 1 therefore indicated a significant correlation between complexity in language production and measures of working memory. Study 2 was undertaken to establish whether a significant correlation between CMS and complexity could be replicated, using new data, from an independent set of participants.
The two studies were conducted successively, although some of the data collection for study 2 (from subjects attending Adult Basic Education (ABE) classes) was undertaken before the analysis of the study 1 data was completed, because of time constraints on the availability of these subjects. Three subjects from the ABE classes were included in study 1, as it was felt necessary to have some representation of the lower end of the working memory ability spectrum in the study. However, although data from other ABE class subjects were collected and transcribed at this time, these data were not analysed in any way, remaining untouched until the analysis of all the study 1 data had been completed, and the final methodology firmly fixed.
Study 2 made use of the test interview, methods of elicitation, collection, transcription, categorisation and analysis formulated and piloted in study 1. However, study 2 was conducted subsequently to, and entirely separately from, study 1. Since study 2 used data from a new, different sample of 50 subjects, its purpose was to test the measures developed and refined in study 1, on a larger, independent data set.
The aim of study 2 was therefore to examine the relationship between working memory (measured by the Combined Memory Score) and complexity in spontaneous language production (measured by the Index of Language Complexity), in order to test the hypothesis that language complexity is constrained by working memory.
It is proposed that those elements that comprise complexity in spontaneous speech not only present a challenge to working memory, but also instantiate social intelligence information.
11. Study 2: method
Since one of the aims of study 1 was to establish a methodology, the method used in study 2 reproduces that detailed in the study 1 method chapter (chapter 8). The only substantive differences lie in the information gathered about the subjects, and the addition of a reliability check on the categorisation.
This first section deals with the selection of subjects, and the remaining sections refer back to the relevant sections in chapter 8.
11.1 Subjects
The 50 subjects were sampled across a broad range of (presumed) ability, and were an opportunity sample. Thirteen of the (presumed low-performing) subjects in study 2 came from local authority Adult Basic Education (ABE) classes, which are intended for people who have problems with literacy and/or numeracy, or who wish to acquire basic computer skills. Eleven of the subjects from the ABE classes had left school at the age of fifteen or sixteen, and had no further or higher education; and one had done RSA typing examinations after her O-levels. Fifteen (presumed high-performing) subjects were postgraduate students, of whom 14 were working towards a PhD, and one was taking a PGCE course. Five of the postgraduates held a master’s degree. The remaining 22 subjects came from the population at large, recruited through personal contacts. Seven of these subjects had had only compulsory education, one had also done banking examinations equivalent to O-levels, and 14 had a degree or degree-equivalent qualification, of whom four held a master’s degree.
source
education to 15/16
education to age 17
degree / equivalent
higher
degree
total
ABE classes
12
1
0
0
13
postgraduate
0
0
10
5
15
population
7
1
10
4
22
total
19
2
20
9
50
Table 12-1 Highest educational level attained by subjects
Subjects were aged between 22 and 66: mean 40.34 (SD 12.57). Twenty-one was taken as the lower limit (in preference to 18, as in study 1) to allow additional time for the completion of late developments in language. In all other respects, the criteria for inclusion were identical to those in study 1.
All subjects were community-dwelling native speakers of British English, and all passed the test of attention. None of the subjects demonstrated any evident pathology either of the CNS, or of speech or language. The 15 postgraduates were in full time education, while the remaining 35 subjects were currently, or had been previously, in normal employment. Twenty-five of the 50 subjects were male, and 25 were female. Subjects’ sex, age, years of education, and memory scores are listed in Appendix 6.
The means, standard deviations, minima, maxima and ranges for subjects’ age, years of education, AWMS score, AWMS percentage, AMIPB score, AMIPB percentage, and Combined Memory Score of these measures are shown in Table 12-2. The distributions for AMIPB, and CMS passed the tests for normality: those for age, years of education, and AWMS did not, and therefore these three variables have non-normal distributions.
measure
mean
SD
minimum
maximum
range
age
40.34
12.57
22
66
44
years of education
14.68
3.26
11
20
9
AWMS score
2.946
.740
1.6
4.6
3
AWMS percentage
58.92
14.803
32
92
60
AMIPB score
34.060
10.119
8
54
46
AMIPB percentage
60.821
18.069
14.29
96.43
82.14
CMS
0
.8434
-1.93
1.76
3.68
Table 12-2 Means and SDs for subject information
11.2 Test administration
The administration of the test followed the procedure detailed in section 8.2, except that, although Digits Forward (DF) and Digits Backward (DB) were included in the test interview, the data from them were not analysed, and they are not reported in the results. They were included in the interview because of the constraint on the availability of the subjects from ABE classes, such that these subjects had to be interviewed before all the study 1 data had been analysed, and it was felt desirable to maintain uniformity across all the interviews. DF and DB therefore appear in the methodology, but not in the results or analysis.
11.2.1 Working memory test scoring
The AMIPB and AWMS tests were scored according to the method detailed in section 8.2.1.
11.3 Transcription
The transcription was carried out according to the method detailed in section 8.3, and the transcription protocol was that described in section 8.3.1.
As a further check on accuracy, six of the transcriptions were verified by a second person, resulting in greater than 99.8% concord. Since no specifically linguistic knowledge is needed to check the accuracy of a transcription, the verifier was linguistically naïve, but was a native speaker of Geordie English (as were the majority of the subjects).
11.4 Categorisation protocol: complexity
The categorisation protocol was identical to that specified in section 8.4.
11.5 Analysis of data : Categorisation
The categorisation of the data was done according to the method described in section 8.5.
11.5.1 Verification of categorisation
As an additional check on accuracy, the categorisations for five of the subjects (i.e.10% of the total) were verified by a second person. The verifier was a linguistically trained researcher in aphasia, having a BA in English Language, and an MSc in Human Communication Science.
From a total of 3750 words in these transcriptions, 4 errors in the categorisation were found. The agreement was therefore better than 99.89%, and it was concluded that this level of accuracy was sufficient.
11.6 Summary
This chapter gave information about the subjects in study 2, and referred back to the requisite sections of the study 1 method chapter, where detailed description of the method is to be found.
The next chapter reports the results of study 2.
12. Study 2: results
Before any analysis of results was undertaken, all the data were examined through various SPSS programs for fit between the distributions and the expectations of normality, since nonnormally distributed data is a counter-indication for the use of parametric statistics. There were no missing values in the data set.
12.1 Data screening for normality
Histograms of each variable were produced and examined not only for symmetry about the mean (since it is possible for a distribution to be symmetric and still not be normal (Afifi & Clark 1996:54)), but also for resemblance to a Gaussian curve. In such a curve, 1SD falls at the point where the downward curve inflects from an inward to an outward direction, and the area enclosed between this point and the mean represents 34.13% of the scores (Coolican 1994:222). Hence, in a normal distribution, 68.26% of scores fall within ±1SD, 95.44% within ±2SDs, and 99.74% within ±3SDs (Coolican 1994:223). Although a visual check of a histogram may be regarded as a simple diagnostic test for normality, the interpretation of histograms is subjective and open to abuse (Field 2000:46). Another problem is that the very construction of the histogram, in terms of the number or width of the categories, can distort the appearance to such an extent that visual analysis is useless (Hair et al. 1995:65). In addition, a sample histogram may be irregular in appearance, consequently making the assessment of normality difficult (Afifi & Clark 1996:54).
Normal probability plots were produced and examined. A normal Q-Q plot compares the values expected from a normal distribution with those observed in the actual data. The expected values are shown as a straight diagonal line; while the observed values are shown as individual points. Any deviation of the points from the line represents a deviation from normality (Field 2000:48). In small samples, the normal probability plot even of normally distributed data may not be perfectly straight, especially at the extremes (Afifi & Clark 1996:58). The middle 80 or 90% of the graph should be approximately a straight line (Afifi & Clark 1996:58), although authors appear to vary as to how much divergence from the line is permissible before it represents a serious deviation from normal (cf. (Coakes & Steed 1999:29-33),(Field 2000:48),(Hair et al. 1995:65),(Norusis 1998:226) and (Tabachnick & Fidell 2001:76)). For this reason, little reliance was placed on the interpretation of these plots.
To obtain more objective tests of the normality of distributions, Kolmogorov-Smirnov, and Shapiro-Wilk tests were performed. These tests compare the set of scores in a sample to a normally distributed set of scores with the same mean and standard deviation (Field 2000:46). If the tests are significant (that is, p<0.05) the distribution of the sample is significantly different from a normal distribution, and is nonnormal: whereas if the tests are nonsignificant (p>0.05), the sample is probably normal (Field 2000:46). Of these two tests, the Shapiro-Wilk is more accurate (Field 2000:51), and has been shown to have a good power against a wide range of nonnormal distributions (Afifi & Clark 1996:62).
Skewness measures the extent to which a distribution deviates from symmetry around the mean. A positively skewed distribution has a greater number of smaller values and a long tail to the right; whereas a negatively skewed distribution has a greater number of larger values and a long tail to the left. The skewness statistic is sensitive to extreme values (Afifi & Clark 1996:61). Kurtosis measures the peakedness or flatness of the distribution. A positive value for kurtosis indicates that the distribution is peaked, with short, thick tails; whereas a negative value for kurtosis indicates that the distribution is flat, with many cases in the tails. Nonnormal kurtosis produces an underestimate of the variance of a variable (Tabachnick & Fidell 2001:73). In a normal distribution values for skewness and kurtosis are zero (Coakes & Steed 1999:30). Skewness and kurtosis values between ±1.0 are considered excellent for most psychometric purposes, while values between ±2.0 may also be acceptable in many cases (George & Mallery 1995:48).
If the data pass the test of normality, and are not significantly skewed or kurtotic, the use of parametric tests is permissible. If, however, the data are nonnormal, skewed or kurtotic, nonparametric test must be used. Three variables (age, years of education, and AWMS) were shown to be nonnormal on one or both of the tests of normality: two of these variables (age and years of education) were also kurtotic. Transformations of age and AWMS were unsuccessful, necessitating nonparametric statistics to be used for these variables.
12.2 Distributions and tests of normality
Information about the independent variables are presented first. These are the subject variables of age, sex, education, and occupation (in section 13.2.1), and the measures of working memory (in section 13.2.2).
The descriptive statistics for the dependent variables, the measures of complexity, are then presented in section 13.2.3.
12.2.1 Subject variables
Descriptive statistics are shown for age in section 13.2.1.1, sex in section 13.2.1.2, education in section 13.2.1.3, and occupation in section 13.2.1.4. These are all independent variables, in the sense that they represent pre-existing and unmanipulated socio-economic differences between subjects. They are also potentially confounding variables.
12.2.1.1 Age
Although there is a reasonable spread across the age range, some ages are represented by two, three or four subjects.
Table 13-1 Descriptive statistics for age
There is slight positive skewness, and considerable negative kurtosis. The distribution of age must be considered to be nonnormal, since the Shapiro-Wilk test achieves significance (p=0.016). Transformations (successively logarithm, square root and inverse) were tried, but none resulted in a distribution that was nearer to normal. The untransformed variable is therefore used, which necessitates the use of nonparametric statistics with this variable.
12.2.1.2 Sex
There are equal numbers of male (25), and of female (25) subjects.
12.2.1.3 Education
Subjects are represented at their highest level of achievement. Eleven years of education represents compulsory schooling; 16 years corresponds to a degree or degree-equivalent qualification, and 19 years to a degree and PhD. Twenty-one subjects had no qualifications higher than CSEs, O levels, GCSEs, or equivalents; whereas 29 had a degree or degree equivalent qualification.
Table 13-2 Descriptive statistics for years of education
There is some negative skewness and considerable negative kurtosis. The distribution is clearly non-normal, as both tests of normality are significant: the Kolmogorov-Smirnov test at p<0.0005, and the Shapiro-Wilk test at p=0.01.
12.2.1.4 Occupation
Apart from postgraduate students, occupations are categorised in accordance with the groupings in the Standard Occupational Classification 2000 (Standard occupational classification 2000 2000).
The number of subjects whose occupations fall in each grouping is shown in the table below.
Occupation
number of subjects
Postgraduate student
15
Unskilled
7
Clerical and sales
11
Skilled and vocational
10
Professional
7
Total
50
Table 13-3 Table of subjects' occupations
12.2.2 Measures of working memory
The descriptive statistics for the two separate working memory tasks are presented: the AMIPB Story Recall subtest (hereafter referred to as AMIPB) in section 13.2.2.1, and the AWMS in section 13.2.2.2, followed by those for the Combined Memory Score (CMS) in section 13.2.2.3. These are all independent variables.
Subjects’ scores in both the AMIPB and the AWMS are presented as percentages of the maximum possible score in the relevant test.
12.2.2.1 Adult Memory and Information Processing Battery
Table 13-4 Descriptive statistics for AMIPB
The kurtosis value, at 0.005, is very close to zero, indicating that the peakedness of the distribution is close to normal. There is some negative skew, with a long tail at the left reflecting the three subjects who scored at, or below, the cut-off (set at the integer nearest to 2 SDs below the mean in the norms (Coughlan & Hollows 1985:54-60)). Approximately half of the scores are tied.
The distribution of AMIPB may be assumed to be normal, since neither test of normality achieves a significance level of p<0.05.
12.2.2.2 Aural Working Memory Span
When AWMS scores are presented as percentages, it will be noted that they occur at intervals of 6% or 8%. This is a consequence of the original scoring system, which reflects discrete packets of achievement.
The quantised nature of the scoring system resulted in almost all of the scores being tied, often multiply: for example, 14 subjects scored 60%, and 9 scored 52%. However, although the other scores are represented by at least one subject, no-one scored 80%, and consequently the highest scores appear to be outliers.
Table 13-5 Descriptive statistics for AWMS
The small positive skew reflects the preponderance of lower scores, and the slight positive kurtosis shows that the distribution is somewhat more peaked than a normal distribution.
The distribution of AWMS is clearly nonnormal, as both tests of normality achieve significance (p<0.05): the Kolomogorov-Smirnov at p=0.001, and the Shapiro-Wilk at p=0.01.
The distribution is thus a candidate for transformation. Although it is standard practice to remove outliers to improve the normality of distributions (Afifi & Clark 1996:67), it was felt that the disconnection of the topmost five scores was an epiphenomenon of the scoring system, rather than their truly not belonging to the same population as the other scores. Also, the removal of these five scores would mean the removal of 10% of the data set: a sizeable proportion.
One of the criteria for the success of transformation is that the ratio of the variable’s mean divided by its SD should be less than 4.0 (Hair et al. 1995:71). The ratio in this case is 3.980 (i.e. 58.920 / 14.803). Transformations are more effective in inducing normality if the SD is large relative to the mean, and if the SD divided by the mean is less than ¼, transformation may not be necessary (Afifi & Clark 1996:63). In this case the SD divided by the mean is 0.251 (i.e. 14.803 / 58.920). The implication here is that the likelihood of success and the need for transformation are marginal.
In order to achieve the skewness and kurtosis values nearest to zero, it may be necessary to try first one transformation then another (Tabachnick & Fidell 2001:81). As the distribution has a slight positive skew, the first transformation tried was a logarithm. Since this was unsuccessful, inverse, square root and inverse logarithmic transformations were tried in turn. None of these was successful in producing a distribution any closer to normality than the original distribution.
The untransformed variable is therefore used, and the nonnormality of this distribution necessitates the use of nonparametric statistics.
12.2.2.3 Combined Memory Score
The CMS is the average of the standardised scores (z-scores) on AMIPB and on AWMS, to reflect both tasks, and to achieve a better spread of results. Only four scores are tied, and each of these was achieved by two subjects apiece. Four disconnected scores at the lower end of the distribution reflect the three subjects who scored at or below cut off on the AMIPB and the two subjects who scored less than 2 on the AWMS. (One subject appears in both of these groups.)
Table 13-6 Descriptive statistics for CMS
There is a small negative skew, and very slight positive kurtosis, but the distribution of scores may be assumed to be normal, since neither test of normality achieves significance (p<0.05).
12.2.3 Measures of complexity
Descriptive statistics are shown for the complexity variable in section 13.2.3.1, followed by each of the four variables which combine to constitute complexity: respectively, optional CPs in section 13.2.3.2, adverb phrases in section 13.2.3.3, modifier phrases in section 13.2.3.4, and adverbials in section 13.2.3.5. They are all dependent variables.
12.2.3.1 Complexity
The complexity variable consists of the amalgamated scores of the four component variables: optional CPs, adverb phrases, modifier phrases, and adverbials.
There was clearly considerable inter-individual variation in the ability to produce complex language, and the subjects’ scores on complexity appeared to demonstrate a continuum of ability.
Table 13-7 Descriptive statistics for Complexity
Skewness is almost zero, and there is some negative kurtosis. The distribution may be assumed to be normal, as neither test achieves significance (p<0.05).
12.2.3.2 Optional Complementiser Phrases
Table 13-8 Descriptive statistics for optional CPs
The skewness is almost zero, and there is only slight kurtosis. The distribution may be assumed to be normal, since neither test achieves significance (p<0.05).
12.2.3.3 Adverb Phrases
Table 13-9 Descriptive statistics for Adverb Phrases
The skewness is almost zero, and there is very slight negative kurtosis. The distribution may be assumed to be normal, since neither tests achieves significance (p<0.05).
12.2.3.4 Modifier Phrases
Table 13-10 Descriptive statistics for Modifier Phrases
Skewness is almost zero, and there is slight negative kurtosis. The distribution may be assumed to be normal, since neither test achieves significance (p<0.05).
12.2.3.5 Adverbials
Table 13-11 Descriptive statistics for Adverbials
There is some positive skewness, and slight negative kurtosis. The distribution may be assumed to be normal, since neither test achieves significance (p<0.05).
12.3 Relationships between variables
A significance level of p=0.05 was selected and used for all tests, since this is the level at which, by convention in psychology, the null hypothesis may be rejected (Brace et al. 2000:260). At this level, a Type 1 error (rejection of the null hypothesis when it is true) will occur, on average, on one in twenty occasions. The critical value for Spearman’s rho with N=50, at a significance level of .05 (two-tailed), is .279 (Sheskin 2000:962).
Since this study examines pre-existing variables, without any experimental manipulation, it is necessarily correlational. It had originally been planned to perform a multiple regression analysis, but this had to be abandoned, since a number of the necessary assumptions (normal distributions, homoscedasticity, and the unboundedness of the outcome variable (Field 2000:128-9)) could not be met.
12.3.1 Choice of statistical tests
Although the data are independent, and of interval or ratio level, several of the variables are nonnormally distributed, and the variances may not be homogeneous. Since attempts to transform the relevant variables were unsuccessful, several of the variables therefore violate the assumptions for the use of parametric statistical tests, and necessitate the use of nonparametric tests. Correlations were performed using the Spearman rank-order correlation coefficient throughout, in order to maintain comparability.
Comparison of several groups was done using the Kruskal-Wallis test, which is the nonparametric equivalent of the one-way between groups ANOVA. The Kruskal-Wallis test has an efficiency of 95.5% when compared to the F test (Siegel & Castellan 1988:215).
As in study 1, parametric one-sample t-tests were used to compare mean scores on the AMIPB with means listed in the test norms. In addition, parametric partial correlations were carried out to investigate whether the link between working memory and complexity is caused by age, and whether there were unique links between CMS and elements of complexity.
12.3.2 Correlation matrix
Correlations between the various working memory and complexity variables, and age, using the Spearman rank-order test are shown in the correlation matrix below.
Table 13-12 Correlation matrix of working memory, complexity and age
12.3.3 Organisation of the section
The primary result, the relationship between complexity (measured by the Index of Language Complexity) and CMS, is shown in section 13.3.4.
The interactions between complexity and its various constituent elements are shown in section 13.3.5.These are a measure of the internal validity of complexity.
Section 13.3.6 presents firstly the internal correlation between AMIPB and AWMS, secondly the comparison of AMIPB scores with the AMIPB norms, and thirdly the correlations between AMIPB and CMS, then AWMS and CMS.
In section 13.3.7 the relationships are shown between complexity and AMIPB, and complexity and AWMS. These correlations reinforce the primary correlation between complexity and CMS (shown in section 13.3.4).
The relationships between CMS and the component constituents of complexity are shown in section 13.3.8. These relationships provide corroboration of the primary result of the correlation between complexity and CMS.
The relationships between age and the measures of working memory are shown in section 13.3.9, followed by those between age and complexity in section 13.3.9.5
12.3.4 Relationship of complexity and CMS
There was a significant positive correlation between complexity and CMS (rho=0.571, N=50, p<0.0005, two-tailed).
12.3.5 Relationship between complexity and its constituents
The relationships are shown between complexity as a whole, and its four constituent parts, videlicet: optional CPs, adverb phrases, modifier phrases, and adverbials. This is a measure of the internal validity of the complexity variable.
12.3.5.1 Optional CPs and complexity
There was a significant positive correlation between optional CPs and complexity (rho =0 288, N=50, p=0.042, two-tailed).
12.3.5.2 Adverb phrases and complexity
There was a significant positive correlation between adverb phrases and complexity (rho =0.775, N=50, p<0.0005, two-tailed).
12.3.5.3 Modifier phrases and complexity
There was a significant positive correlation between modifier phrases and complexity (rho =0.400, N=50, p=0.004, two-tailed).
12.3.5.4 Adverbials and complexity
There was a significant positive correlation between adverbials and complexity (rho =0.707, N=50, p<0.0005, two-tailed).
12.3.6 Relationships between measures of working memory
The internal correlation between AMIPB and AWMS is shown first, followed by the comparison of the AMIPB scores with the published AMIPB norms in section 13.3.6.2. The relationships are then shown between AMIPB and CMS in section 13.3.6.3, and between AWMS and CMS in section 13.3.6.4.
12.3.6.1 AMIPB and AWMS
There was a significant positive correlation between the AMIPB and the AWMS, (rho=0.407, N=50, p=0.003, two-tailed).
12.3.6.2 AMIPB scores compared with AMIPB norms
The mean of the AMIPB raw scores for the whole sample was compared with the mean for the whole sample, as listed in the AMIPB norms (Coughlan & Hollows 1985:56), using a one-sample t-test, as shown in Table 13-13.
Table 13-13 AMIPB mean and AMIPB norm (whole sample)
There was no significant difference between the mean of the sample in the study, and the whole sample mean listed in the AMIPB norms (t=-0.168, df=49, p>0.05). The population surveyed in this study may thus be assumed not to differ significantly from the population covered by the AMIPB norms.
12.3.6.3 AMIPB and CMS
The standardised scores (z-scores) from the two working memory tasks AMIPB and AWMS were combined (in a 50:50 ratio) to yield the Combined Memory Score.
As was to be expected, there was a significant positive correlation between the AMIPB and the CMS (rho= 0.847, N=50, p <0.0005, two-tailed).
12.3.6.4 AWMS and CMS
There was also a significant positive correlation between the AWMS and the CMS (rho=0.813, N=50, p <0.0005, two-tailed).
It is to be expected that the correlation between AMIPB and CMS would be higher than that between AWMS and CMS, since the Spearman rank-order correlation is based on rank ordering, and AWMS scores include large numbers of ties, particularly those at 60%. Indeed, it was partly in order to avoid numerous tied ranks that AMIPB and AWMS were amalgamated into CMS.
12.3.7 Relationship of complexity with AMIPB and AWMS
The relationships are described first between complexity and AMIPB, and then between complexity and AWMS.
12.3.7.1 Complexity and AMIPB
There was a significant positive correlation between complexity and scores on the AMIPB (rho=0.506, N=50, p<0.0005, two-tailed).
12.3.7.2 Complexity and AWMS
There was a significant positive correlation between complexity and scores on the AWMS (rho=0.474, N=50, p=0.001, two-tailed).
12.3.8 Relationship of CMS with the constituents of complexity
The relationships between CMS and the component constituents of complexity are shown below.
12.3.8.1 CMS and optional CPs
There was no significant positive correlation between CMS and optional CPs (rho=0.257, N=50, p>0.05, two-tailed).
12.3.8.2 CMS and adverb phrases
There was a significant positive correlation between CMS and adverb phrases (rho=0.439, N=50, p=0.001, two-tailed).
12.3.8.3 CMS and modifier phrases
There was no significant positive correlation between CMS and modifier phrases (rho=0.168, N=50, p>0.05, two-tailed).
12.3.8.4 CMS and adverbials
There was a significant positive correlation between CMS and adverbials (rho=0.378, N=50, p=0.007, two-tailed).
12.3.9 Relationships with age
That mental abilities, including memory, change with age is well known (Lezak 1995:292-3): consequently the examination of the interactions between age and memory, and age and complexity was planned in advance. In order to try to localise approximately when it is that the changes occur, subjects were stratified into five age groups (up to 25, 26-35, 36-45, 46-55, and 56-66). The nonparametric Kruskal-Wallis test was used to investigate differences between these groups.
The relationships between age and measures of working memory are shown below: the relationship with CMS in section 13.3.9.1, with AMIPB in section 13.3.9.2, the comparisons with AMIPB norms in section 13.3.9.3, and with AWMS in section 13.3.9.4.
The relationship between age and complexity is shown in section 13.3.9.5, and finally the relationships between CMS and complexity, and between CMS and the constituents of complexity, all controlling for age, are shown in section 13.3.9.6.
12.3.9.1 Age and CMS
There was a significant negative correlation between age and scores on the CMS (rho= -0.550, N=50, p<0.0005, two-tailed).
The Kruskal-Wallis test showed that at least one of the groups differed significantly from the others (c2 =15.699, df=4,p=0.003).
Table 13-14 Kruskal Wallis test of age groups and CMS
12.3.9.2 Age and AMIPB
There was a significant negative correlation between age and scores on the AMIPB (rho= -0.494, N=50, p<0.0005, two-tailed).
The Kruskal-Wallis test showed that at least one of the groups differed significantly from the others (c2 =13.597, df=4, p=0.009).
Table 13-15 Kruskal Wallis test of age groups and AMIPB
12.3.9.3 Comparisons with AMIPB norms
The subjects were split into four age groups, in order to correspond to the age groups in the AMIPB norms, and the mean of each group was compared to the mean in the relevant section of the AMIPB norms, using a parametric one-sample t-test.
Table 13-16 AMIPB mean and AMIPB norm (young group)
The young age group aged 22-30 (N=15) corresponds to the AMIPB age group of 18-30 year olds (N=45). There is no significant difference between the mean score of the young age group and that of the AMIPB norm group, as shown in Table 13-16 (t= -0.105, df=14, p>0.05).
Table 13-17 AMIPB mean and AMIPB norm (prime group)
The prime age group aged 31-45 (N=16) corresponds to the AMIPB age group of 31-45 year olds (N=45). There is no significant difference between the mean score of the prime age group and that of the AMIPB norm group, as is shown in Table 13-17 (t=0.939, df=15, p>0.05).
Table 13-18 AMIPB mean and AMIPB norm (mature group)
Those subjects in the mature age group aged 46-60 (N=16) correspond to the AMIPB age group of 46-60 year olds (N=45). There is no significant difference between the mean score of this subset of the mature age group and that of the AMIPB norm group, as is shown in Table 13-18 (t= -1.552, df=15, p>0.05).
Table 13-19 AMIPB mean and AMIPB norm (old group)
Those subjects in the mature age group aged 61-66 (N=3) correspond to the AMIPB age group of 61-75 year olds (N=45). There is no significant difference between the mean score of this subset of the mature age group and that of the AMIPB norm group, as is shown in Table 13-19 (t= -2.303, df=2, p>0.05).
12.3.9.4 Age and AWMS
There was a significant negative correlation between age and scores on the AWMS (rho= -0.423, N=50, p=0.002, two-tailed)
The Kruskal-Wallis test showed that at least one of the groups differed significantly from the others (c2 =9.743, df=4, p=0.045).
Table 13-20 Kruskal Wallis test of age groups and AWMS
12.3.9.5 Age and complexity
There was a significant negative correlation between age and complexity (rho= -0.443, N=50, p=0.001, two-tailed).
The Kruskal-Wallis test showed that the differences between the groups were not significant (c2 =8.819, df=4, p>0.05).
Table 13-21 Kruskal Wallis test of age groups and complexity
12.3.9.6 CMS, complexity, and age
A partial correlation was carried out to examine whether age is causing the relationship between CMS and complexity. There was significant positive correlation between CMS and complexity, controlling for age (r=0.423, N=50. p=0.002, two-tailed), implying that 17.9% of the variance in complexity is explained by CMS.
Further partial correlations were performed, to investigate the unique links between CMS and the constituents of complexity, after the effects of age were removed. The results are shown in the table below.
variables (controlling for age)
correlation
significance
CMS vs optional CPs
0.220
0.129
CMS vs adverb phrases
0.144
0.323
CMS vs modifier phrases
0.342*
0.016
CMS vs adverbials
0.323*
0.024
Table 13-22 Partial correlations between CMS and constituents of complexity, controlling for age
It should be noted, however, that, since in every case the assumption of the bivariate normality of each pair of variables is violated, because the age variable is non-normally distributed and data transformations were unsuccessful (as described in section 13.2.1.1), all these partial correlation results must be interpreted with great caution.
12.4 Summary
The descriptive statistics for each of the variables were reported, as were the inferential statistics describing the relationships between the variables.
The next chapter discusses the significance of the results.
13. Study 2: discussion
The main findings are summarised in the first section (14.1), and the following three sections deal with separate aspects of the study: working memory (in section 14.2), complexity (in section 14.3), and the relationship between working memory and complexity (in section 14.4). Each of these sections discusses matters relating to validity and reliability pertinent to that aspect of the study, and relates the relevant aspect of the present investigation to the context of previous research.
The effect of ageing on both working memory and complexity is dealt with in section 14.5. Section 14.6 concerns the limitations of this study, while section 14.7 discusses the implications for future research.
The separate strands of language complexity, working memory, and social intelligence are drawn together in section 14.8, which is followed by the conclusions of the study.
13.1 Main results
The results are summarised in the order of their appearance in the preceding chapter, viz: the primary correlation between CMS and ILC in section 14.1.1, the secondary correlations between the measures of working memory in section 14.1.2, and between complexity and its constituents in section 14.1.3. The tertiary relationships between complexity and the constituents of memory follow in section 14.1.4, and between CMS and the constituents of complexity in section 14.1.5. Finally, the relationships of age with working memory, and with complexity are summarised in section 14.1.6.
13.1.1 CMS and ILC
The principal result was the finding of a significant correlation (rho=0.571**, p<0.0005) between working memory (measured by the Combined Memory Score) and complexity (measured by the Index of Language Complexity). This replicates the finding of study 1, and is consistent with the hypothesis that working memory constrains language complexity in production.
13.1.2 CMS and its constituents
The secondary result of a significant correlation (rho=0.407**, p=0.003) between AMIPB and AWMS demonstrates the internal validity of the CMS variable. This is confirmed by the correlations both between CMS and AMIPB (rho=0.847**, p<0.0005) and between CMS and AWMS (rho=0.813**, p<0.0005).
The validity of the AMIPB scores in this study is confirmed by the lack of any significant difference between them and the scores in the published AMIPB norms in a one-sample t-test (t= -0.168, df=49, p=0.867). The criterion validity of AWMS and CMS are demonstrated by their correlations with AMIPB.
13.1.3 ILC and its constituents
The secondary result, that there are significant correlations between ILC, representing complexity as a whole, and each of the component constituents of complexity demonstrates the internal validity of the ILC as a measure. The correlations are: ILC vs optional CPs (rho=0.288*, p=0.042); ILC vs adverb phrases (rho=0.775**, p<0.0005); ILC vs modifier phrases (rho=0.400**, p=0.004), and ILC vs adverbials (rho=0.707**, p<0.0005).
13.1.4 ILC and working memory constituents
The tertiary result of significant correlations between complexity (measured by ILC) and both AMIPB (rho=0.506**, p<0.0005) and AWMS (rho=0.474**, p=0.001), the component constituents of CMS, provides an additional check on validity.
13.1.5 CMS and complexity constituents
The tertiary relationships between CMS and the constituent components of ILC provide an additional check on validity.
The Spearman rank-order correlation coefficients were: CMS vs optional CPs rho=0.257, p=0.072; CMS vs adverb phrases rho=0.439**, p=0.001; CMS vs modifier phrases rho=0.168, p=0.243; CMS vs adverbials rho=0.378**, p=0.007. Although all the relationships were positive, two were not significantly correlated. In this case, it was possible also to perform parametric Pearson product-moment correlations because the distributions of all of these variables passed the tests for normality, and had low values for both skewness and kurtosis, so the underlying assumptions were not violated.
The Pearson product-moment correlations were respectively: CMS vs optional CPs r=0.227, p>0.05; CMS vs adverb phrases r=0.354*, p=0.012; CMS vs modifier phrases r=0.349*, p=0.013; and CMS vs adverbials r=0.348*, p=0.013.
That the correlation between CMS and modifier phrases is not significant on the nonparametric Spearman test, but is significant on the parametric Pearson test, shows the effect of giving full weight to extreme values, since nonparametric tests lose the extremities of range.
The greater significance of the correlation between CMS and ILC as a whole shows the benefit of having the combined measure.
13.1.6 Relationships with age
The relationship between age and working memory is described first, in section 14.1.6.1 and this is followed by that between age and complexity (measured by ILC) in section 14.1.6.2. These relationships were investigated because the decrement in WM in older adults is well known, and because previous research has indicated a diminution in complexity (albeit measured in a different way) in old age.
13.1.6.1 Age and working memory
The results showed the expected negative correlation between age and working memory: in each case it was significant. The Spearman rank-order correlation coefficients were: age vs CMS rho = -0.550**, p <0.0005; age vs AMIPB rho = --0.494**, p <0.0005; age vs AWMS rho = -0.423**, p = 0.002.
The scores on AMIPB were divided into 4 age groups, to correspond to those in the AMIPB norms, and comparisons were made with the norm age group scores, using one-sample t-tests. None of the age groups had scores that differed significantly from those of the equivalent group in the norms.
Scores on each of the WM tests were divided into 5 age groups (up to 25, 26-35, 36-45, 46-55, and 56 and over) to establish whether the groups’ scores differed from each other. The results were: CMS age groups c2 =15.699, p=0.003; AMIPB age groups c2 = 13.597, p = 0.009; AWMS age groups c2 = 9.743, p = 0.045. On each WM test, at least one group was significantly different from the others on a Kruskal Wallis test (df=4).
13.1.6.2 Age and ILC
Age was found to be significantly negatively correlated with complexity (measured on ILC) rho = -0.443**, p = 0.001.
However, none of the age groups was significantly different from the others, in a Kruskal Wallis test (c2=8.819, df=4, p=0.066).
13.1.6.3 CMS, ILC, and age
Partial correlations were conducted to investigate the relationships between CMS and complexity, and CMS and its constituents, when controlling for the effects of age. The partial correlations appeared to show that 17.9% of the variance in complexity is explained by CMS, and that modifier phrases and adverbials have unique links with working memory, whereas the relationships between CMS and both optional CPs and adverb phrases are non-significant once age is controlled for.
However, since the age variable is non-normally distributed, the assumption of bivariate normality was violated in each case, and consequently these results should be regarded with considerable circumspection.
13.2 Working memory
This section discusses the aspects of the study concerned only with working memory. It begins by reviewing the validity and reliability of the WM measures (in 14.2.1), and then relates the WM aspects of the present investigation to the context of previous research (in section 14.2.2).
13.2.1 Validity and reliability of WM measures
Validity refers to how adequately the test instrument actually measures the characteristic under investigation (Abramson 1990: 151).
The measurement of all the component elements (Abramson 1990:153) and the overall cohesiveness of the elements (Reber & Reber 2001:782) of a composite variable show its content validity. CMS consisted of an amalgamation of the standardised scores on both the component elements, AMIPB and AWMS, and the high correlation between them demonstrates their cohesiveness. The internal consistency of the WM analysis was validated by each of the two component elements (AMIPB and AWMS) correlating significantly with both each other and the overall measure CMS.
The format of WM span tests (following the paradigm of the Daneman and Carpenter reading span test) has been endorsed by years of use for delivering a measure of WM ability, and so has achieved consensual validity. Nonetheless, Wingfield points out (2000:185) that the term working memory is a descriptive convenience, referring more to the ability to perform well in tests designed to measure WM ability (both storing and manipulating information) than to any tangible construct.
AWMS was created in four parallel forms, so as to permit re-testing on subsequent occasions, since this is highly desirable were it to be used as a neuropsychological test to assess improvement or deterioration in performance over time (Lezak 1995:120). The availability of four parallel forms might make AWMS useful for other researchers in the field of language and memory. Although only one form of AWMS was used in this study, a future study is planned to test and measure the reliability between the four forms.
Convergent validity (also known as construct validity) is appraised by the existence of associations with other variables that there are reasons to believe should be connected to the item being investigated (Abramson 1990:156). Scores on WM are generally acknowledged to decrease with age, and this decrement is confirmed by the AMIPB norms (Coughlan & Hollows 1985). The expected age-related decline in performance levels on AMWS was found, and was significant negatively correlated with age (rho= -0.423**, N=50, p=0.002). The decline was also present on CMS, which was significantly negatively correlated with age (rho= -0.550**, N=50, p<0.0005)
Ecological validity is concerned with the extent to which the findings of a study generalise to other environments, and are replicable in real life settings (Coolican 1994:55). It is used as a cover term for mundane realism (where the task resembles everyday life, but is not necessarily engaging to the participants) and experimental realism (where the artificiality of the experiment is compensated for by its exciting and attention grabbing nature) (Coolican 1994:55,63). One of the stated aims of AMIPB (Coughlan & Hollows 1985:19) was to reflect the memory demands of everyday life, and the Story Recall task does indeed have mundane realism, whereas AWMS is an unnatural task, that makes great demands on attention. One of the reasons for the amalgamation of the two tasks to yield the CMS scores was to reflect both aspects of ecological validity.
Response objectivity refers to the degree in which an assessment will be unaffected by the subject’s tendencies to fake his responses (Pawlik 2000:377). Subjects were naïve to the purpose of the investigation, having been told only that it concerned language and memory. From the point of view of language, subjects did not know which elements were of interest in the investigation, and could therefore not fake their performance in either direction. Although it is possible to deliberately perform lower than one’s true ability level on WM tests, subjects appeared to relish the intellectual challenge, and (in the discussion after the interview) were interested in how well they had done on the memory tests. The reading span test is claimed (Daneman 1984:370,373) to be a test of functional WM capacity, that is, of the efficiency of processes and procedures for the maximal utilisation of capacities. It is therefore unlikely that anyone can fake a higher performance than his true ability level.
13.2.2 Relationship with previous research
Although the AMIPB test battery is a working neuropsychological tool, rather than a research medium, the raw scores resulting from this study were compared with those listed in the norms (Coughlan & Hollows 1985). The study mean 34.06, SD 10.12, and range (8-54) may be contrasted with the mean 34.3, SD 11.1, and range (7-55) in the norms. The study values did not differ significantly from the norms, and the 50 participants in this study therefore do not appear to differ significantly in their WM ability from the population (N=180) sampled for the AMIPB norms.
AWMS raw scores ranged from 1.6 to 4.6 (i.e. 32% to 92%) mean 2.95, SD 0.74 (i.e. mean 58.92%, SD 14.8%) and these scores were compared informally with published scores on the Daneman and Carpenter listening span test. Daneman and Carpenter had administered a listening span test to university students (n = >200) whose scores ranged from 1.5 to 5 (Daneman 1984:373-4). A mean score for the listening span of 2.95 (SD 0.72) was reported for 21 students, whose scores ranged from 2 to 4.5 (Daneman & Carpenter 1980:460). It appears that AWMS scores are comparable in nature to those on the original listening span task.
Daneman noted (1984:373-4) that, even among such a circumscribed population as university students, considerable differences in scores were to be found, and that an upper limit clearly existed, since fewer than 10% of the students performed at the highest level. In the present study, only 4 of the 50 subjects (i.e. 8%) achieved AWMS scores of 4.6 (equivalent to a Daneman and Carpenter score of 5). Two of these four were 25 year old postgraduates: the other two (one 36 years, one 40 years) had no education beyond O-level equivalent examinations. Almost all the subjects found the test extremely difficult, and were clearly exerting considerable effort, giving the words in random order, although one subject gave all his answers quickly, confidently, and in the correct order.
Tompkins et al. noted (1994:903) that none of their subjects had difficulty in performing at level two: this was true even for the subjects who had suffered cerebrovascular accidents. Two subjects in the present study, however, did have difficulty at level two, scoring 1.6, as they were unable successfully to complete all three sets at that level. A further 5 subjects scored only 2 on AWMS, being unable to do any of the three-sentence sets. That more subjects had low scores than high scores on WM tests is to be expected, in view of the many disparate phenomena that can lead to poor performance: among them brain pathology, illness, anxiety, distraction, tiredness, intoxication, and age.
It is not possible to compare the CMS scores with previous studies, as this amalgamation of scores has not been reported elsewhere.
13.3 Complexity
Complexity was measured by the ILC, and the ILC elements instantiate complexity, so the two terms are used interchangeably. The first section (14.3.1) assesses the validity and reliability of the ILC, and section 14.3.2 relates it to the context of previous research on complexity.
13.3.1 Validity and reliability of the ILC
Validity is the extent to which a test measures that which it purports to measure. Face validity concerns whether elements to be included in a test seem likely to yield information of relevance to what is being investigated (Abramson 1990:152). Because of the inherent subjectivity, this is described as a rather fuzzy procedure for validity (Reber & Reber 2001:782): nonetheless, study 1 provided evidence to suggest that the complexity metric was measuring a real construct. The construct validity of a measure depends on its yielding empirical results which conform with the hypotheses of the theory on which the construct is based (Pawlik 2000:376). The construct of complexity is founded on a theoretically coherent and consistent body of evolutionary, neuroscientific, and linguistic knowledge, which points to the benefits for social intelligence, WM and computational demands, and linguistic difficulty inherent in producing complex language.
Content validity is shown, in a composite variable, by whether all the component elements of the variable are measured (Abramson 1990:153) and by the overall cohesiveness of the items (Reber & Reber 2001:782). The complexity metric ILC measures four classes of optional elements (optional CPs, adverb phrases, modifier phrases, and adverbials) which are claimed to instantiate complexity in productive language, whereas elements said to represent complexity in comprehension, such as object-trace relative clauses, constitute only a subset of one of these classes. This shows that the ILC offers an inclusive measure of the elements comprising complexity. These individual components are cohesive, not only in their difficulty for children and groups of people with language disorders, but also in their grammatical status. Content validity is a largely subjective operation (Reber & Reber 2001:782), but it is probable that there would be general agreement among linguists, despite the inevitable slight idiolectal variation, about the optionality of the elements designated as representing complexity.
Construct validity is improved by taking a variety of measures of the same concept (Coolican 1994:53), and accordingly ILC benefits from consisting of its four component elements, each of which is a partial measure of complexity. The internal consistency of the complexity analysis was validated by the significant correlation between each of the four component elements (optional CPs, adverb phrases, modifier phrases, and adverbials) and ILC, the overall complexity measure.
Reliability refers to the consistency and stability of information gained when a measurement is performed more than once, although high reliability does not necessarily mean that a procedure is satisfactory for its purpose (Abramson 1990:138-9). This can be illustrated by the example of the complete reliability, but also total inutility, of a broken watch (Abramson 1990:139).
The elements comprising complexity are not in opposition to each other, instead they tend to measure the same entity, and display internal consistency (Coolican 1994:156,151). Indeed, the use of composite measurements, based on a number of related items, usually increases reliability (Abramson 1990:145).
Inter-rater reliability was assessed for the accuracy of transcription of the language data elicited by the interviews, showing concord of greater than 99% between the two raters. Inter-rater reliability was also assessed for the accuracy of the categorisation undertaken on the language data, and, again, reliability was better than 99%. (These procedures were described in the method section.)
The use of standard procedures, and clear operational definitions enhances reliability (Abramson 1990:144). Because the definition of complexity and the protocol for the categorisation of language data were extensively detailed, the concept of complexity is rigorously defined. This explicitness and objectivity increases the reliability of the ILC as a measure, and of complexity as a concept.
13.3.2 Relationship with previous research
Complexity as measured by ILC was found to vary between subjects, as had been anticipated. Each of the four component variables correlated significantly with ILC as a whole, which confirmed the internal validity of the complexity measure.
There have been remarkably few studies of complexity in language production, in contrast to the vast literature in the field of language comprehension. Since the present study investigated complexity in adult participants, no comparisons will be made with research on language complexity in children, because they are concerned with verifying developmental stages in the acquisition process, rather than with complexity as it is represented in adult language. Similarly, no comparisons will be made with analyses of language produced by people with aphasia, since those analyses are concerned with such elements as the presence or absence of determiners, or of subject-verb agreement, rather than with complexity as instantiated in the language of a person who does not suffer from aphasia.
One of the non-aphasic adult groups whose language production has been studied for complexity is people with schizophrenia, since disordered speech with lower complexity is reportedly symptomatic (Morice & Ingram 1983), despite the fact that schizophrenia itself cannot be regarded as a unitary phenomenon (Charlton 2000:127). Of these studies, not all compare their analysis of disordered speech with language produced by control subjects, and among those which do, reporting of performance by controls is perfunctory, and not quantified. The measures of complexity used in studies of schizophrenic speech owe much to the analysis by Morice and Ingram (1982). They rely on division of the data into sentences or T-units, and count such elements as percentage of well formed sentences, mean length of sentence, percentage of simple sentences, percentage of sentences containing embedded clauses, and mean depth of embedding (Thomas et al. 1996a). The lack of quantification, and the disparity in the kind of element regarded as complex, means that no comparison between the present study and those is possible.
The other non-aphasic adult group whose productive language complexity has been analysed is older people. Kemper et al. (1989) used an analysis of Mean Clause per Utterance, plus a categorisation of embedded clauses as main, left-branching, right-branching, or “other” (for clauses in sentence fragments). Embeddings at all levels were counted: gerunds (VP), infinitive complements (IP), that-clauses (IP), Wh-clauses (CP), and relative clauses (CP), whatever sentential function they performed (Kemper et al. 1989:53). The analysis is of complexity only at the clausal level, and insufficient data are given to be able to compare the scores on their clausal complexity measure with optional CPs in this study.
Another study of older people’s language production (Cheung & Kemper 1992) compared the analysis under each of several complexity metrics to establish how well each metric indicated age group differences in complexity. Since the overall performance of each metric was at issue, insufficient data were given to allow any meaningful comparison of complexity with the current study.
Developmental Level (Rosenberg & Abbeduto 1987), the analysis of the language production by a small group of adults with learning disabilities, was used in the original study only on that group, with no control subjects. The Developmental Level analysis has, however, been used by Kemper and her co-workers to analyse written data from the Nun Study.
The Nun Study is a long-standing epidemiological study in America, investigating Alzheimer’s Disease, using as subjects the elderly nuns of one particular religious order. The Nun Study found an association between the nuns’ scores on cognitive tests undertaken in their old age, and the grammatical complexity and idea density in the diaries they had written in young adulthood (Snowdon 2001:112). Grammatical complexity was measured on Developmental Level (Rosenberg & Abbeduto 1987) a 7-point scale that had been devised to describe the language of learning disabled adults, and idea density is a measure of the number of propositions expressed per ten words (Snowdon 2001:109,112). Low ability in grammatical complexity (measured on Developmental Level (Rosenberg & Abbeduto 1987)) has been claimed (Kemper & Sumner 2001:313) to be associated with increased likelihood of poor performance on cognitive and memory tests in old age. Idea density overlaps, to a certain extent, with the complexity metric used in this study, since the propositions counted include adjuncts as well as arguments. Snowdon suggests (2001:114) that low idea density in early life means that the brain is already compromised in some way. The obverse of this is that high performance ability advertises that the brain has not been compromised.
With the exception of Hirschman’s study (Hirschman 2000) on language remediation for children with SLI, which also assessed the phrasal level, previous studies on the production of complex language have taken into account only complexity at the clausal level.
13.4 Working memory and complexity
The main finding of this study is the significant correlation (rho=0.571**, N=50, p<0.0005) between working memory (measured by CMS) and complexity (measured by ILC).
The first section (14.4.1) describes the validity and reliability of the relationship between CMS and ILC, and hence of the study as a whole. This is followed by the fit of the current investigation with previous research in the area (in section 14.4.2).
13.4.1 Validity and reliability of the CMS/ILC relationship
The stability of a measure is the extent to which it can be repeated, with similar results (Coolican 1994:64). The replication, in the present study, of the previously found significant correlation between WM and complexity demonstrates the stability of the WM and complexity measures. Where an effect can be replicated in a sample that is not specifically different from the original sample, it tests how well the effect generalises to the population from which the samples were drawn (Coolican 1994:59). That a significant correlation was demonstrated between WM and complexity in both study 1 and study 2 suggests that the effect is genuinely present in the population from which the subjects were sampled.
The empirical validity of the analysis, the degree to which a test works in a real sample of subjects (Reber & Reber 2001:782) was indicated by the replication in study 2 of a significant correlation between WM ability and the amount of complexity produced (CMS and complexity: rho=0.571**, N=50, p<0.0005), as had been evident in study 1. It therefore represents a form of convergent validity of the memory measure CMS and the complexity measure ILC.
The study was designed to be explicit, objective, and replicable. One of the ways in which reliability can be enhanced is by reducing variation to reasonable limits (Abramson 1990:144). This entails the use of standard procedures, and clear operational definitions (Abramson 1990:144). The test interview was administered in a standard way to each of the participants (described in the method chapter), and the detailed protocol for the categorisation of language data means that the concept of complexity is tightly defined, explicit and objective.
One source of variation which detracts from the consistency of the information gained through a procedure is variation in the characteristic being measured (Abramson 1990:140). It is simply not known whether a normal individual’s WM and language complexity abilities fluctuate, the extent to which they may do so, or the time-scale over which this may occur. Subjects were not asked about their levels of anxiety, tiredness, hunger, inebriation, or medication, all of which would potentially affect their performance. It is possible that the same individual may perform very differently at different times of day, depending on his circadian rhythms. Appointments with subjects were made to suit their convenience, so the investigator had no control over when the test interviews were undertaken. There is current research interest in the effects of the menstrual cycle (and hormone replacement therapy) on memory, and these effects may well extend to WM and/or language complexity. The investigation of these kinds of fluctuation constitute possible future research topics.
Another source of variation which would detract from reliability was a form of observer variation (Abramson 1990:141), namely the inevitably differing reactions of the various subjects to the personal characteristics, and speech/language characteristics of the interviewer. This is essentially what Labov termed the observer’s paradox: the investigator’s presence and verbal interventions alter the nature and quality of that which is to be observed. The use of a single investigator (as in this study) enhances reliability by minimising inter-observer variation (Abramson 1990:145). Accommodation theory (Giles & Powesland 1997:233) predicts that a speaker will attempt to modify his persona to make it more acceptable to his interlocutor. This could take the form of convergence towards the interviewer as a consequence of the prestige and power inherent in that role, or divergence away from the interviewer as a marker of regional solidarity (since the interviewer has modified RP, whereas several of the subjects have Geordie accents, and some use dialectal variants). Performing the interview in a place familiar to the subject was an attempt to redress the power balance, but some observer effect is unavoidable in a study where the stimuli have to be presented orally. A corollary to this is that not all the subjects would have felt the same about the interview, and its perceived purpose, formality, and level of difficulty: neither would they all have felt an equal desire to impress the interviewer. Similarly subjects will differ in their willingness to make an effort to respond to questions whose answers they do not know or are unsure of. These aspects, too, would affect the reliability of the measure.
Subjects were blind to the purpose of the study, having been told only that it was concerned with the psychology of language, and that they would be asked to undertake some memory tests. However, the problem of the investigator (E) knowing how a subject had performed on the WM tests when she was categorising their language data had to be addressed. As was the case in study 1, E had administered the WM tests, and had scored them as part of the transcription process: in this sense, it was impossible for E to be blind to the AMIPB and AWMS scores. She was however, blind to the CMS scores, which were calculated later in SPSS. Moreover, the transcription and categorisation processes for a given subject’s data were not carried out sequentially: rather the two processes were separated in most cases by a matter of weeks. The subjects’ AMIPB and AWMS scores were tallied initially on paper, and then entered into an Excel file. This WM file was separate from the workbooks in which the data were categorised and calculated, and was not consulted before or during the categorisation process. In this way, although E had scored the WM tests, this information was not currently activated in her recollection. It should also be noted that ILC scores (as the sum of the four component constituents) were calculated not on the individual subject’s worksheet page where the categorisation was done, but on a “totals” page where summary data for 10 subjects were pasted, preparatory to transfer to the Excel 4 worksheet that was accessible to SPSS. It may thus be seen that E had access to neither CMS nor ILC scores while undertaking the categorisation process: moreover, the rigorous definition of complexity elements made the analysis and categorisation objective.
13.4.2 Relationship with previous research
The finding of a significant correlation between CMS and ILC was the primary result of this study. The is very little previous research on working memory and complexity in language production, in normal subjects, and consequently there are few direct comparisons to be made.
In a study based on a background of research into schizophrenia, Barch and Berenbaum (1994) investigated the effect on language of reduced processing capacity, using 50 undergraduates as subjects. WM was tested by WAIS Digit Span, using the total score (Barch & Berenbaum 1994:243). When the score on WAIS Digit Span is reported as the combined score of Digits Forwards and Digits Backwards, valuable information is lost, because DF and DB test different things (Lezak 1995:357). Language was elicited by a series of “open-ended questions”, such as describe the perfect vacation or describe the perfect date (Barch & Berenbaum 1994:243). The study aimed to compare language performance between two conditions: one interview as a control, and the other with a concurrent category monitoring task, because people with schizophrenia are though to have particular problems with dual tasks (Barch & Berenbaum 1994:243). The category monitoring task was to read words on a computer screen, judge whether each word belonged to the “body-parts” category, and press a key to indicate this.(Barch & Berenbaum 1994:243). Language complexity was assessed by the mean number of words per T-unit, and the mean number of dependent clauses per T-unit (Barch & Berenbaum 1994:244). The Digit Span scores were regarded as part of a combined information processing measure, and were not reported separately, so their relationship with the language variables is not ascertainable, although differences in information processing were shown to predict differences in the mean number of words per T-unit, and the mean number of dependent clauses per T-unit (Barch & Berenbaum 1994:245). Because of the rudimentary analysis of both the complexity measures, and the amalgamation of Digit Span into an overall measure, no comparison can usefully be drawn with the present study.
Kemper and Sumner (2001) tested 100 young (18-28 years) subjects and 100 older (63-88 years) subjects on a number of vocabulary tests, and WAIS Digits Forwards and Digits Backwards, even though DF cannot be considered a measure of WM (Lezak 1995:359). A sample of spontaneous speech was elicited by asking the subjects to describe an influential person or interesting experience that had affected their life (Kemper & Sumner 2001:315). The speech was segmented into utterances (using pausing as the criterion), and the final 10 complete utterances were then analysed according to Developmental Level (D Level) (Rosenberg & Abbeduto 1987) yielding a mean score for each subject, over the 10 utterances. Correlations were reported between DB and D Level of 0.78 for the young subjects, and 0.74 for the older subjects (although no significance levels were given). The language and WM measures are both inadequate for the task, and the categorisation into utterances is necessarily subjective. Their findings are broadly consistent with those of the present study, in that complexity and WM co-varied, albeit they were measured differently.
A study by Kemper et al. (1989) investigated the differences between young adults (18-28 years) and elderly adults (60-92 years) in their language complexity and WM ability. Complexity was measured by Mean Clauses per Utterance, and the division of embeddings (of all levels: VP, IP, and CP) into main clauses, left-branching, right-branching, and “other”. WM was measured on WAIS Digit Span, whose scoring system is criticised by Lezak (1995:357-8) for obscuring meaningful data, by giving a point for each correct trial at each level, thus confounding length of span with reliability of span performance. Kemper et al. do remark (1989:64) that Digit Span may not be the best measure of WM to have used. Kemper et al. keep DF and DB scores separate, but report the comparisons with scores on their complexity metric only in partial correlations, with age partialed out (Kemper et al. 1989:60). It is therefore impossible to gauge directly the relationship between memory and complexity, in order to compare the findings with those of the present study.
Older adults (aged 50-89) were asked by Kemper (1988:64-5) to relate a narrative about a significant event in their life, and the resultant embedded clauses (of all levels: VP, IP, and CP) were categorised as left-branching or right-branching. The subjects’ WM was measured by WAIS Digits Forwards and Digits Backwards, and correlations were obtained between these memory measures and Mean Clauses per Utterance (confusingly referred to as mean clause length), and the mean number of both left-branching and right-branching clauses per sentence (Kemper 1988:66). Significant correlations were found between DB and both Mean Clauses per Utterance (MCU) and the mean number of left-branching clauses per sentence (Kemper 1988:66). This is broadly consistent with the present study, since WM and complexity co-varied, however, complexity was measured only by MCU and the left- vs right-branching position of clauses: no account was taken of what sort of clause was involved. All the data were counted per utterance/sentence, and computed on that basis: the measure therefore was dependent on the inevitably subjective construal of utterances. There is an additional worrying factor, in that, earlier in the paper, examples of left-branching or right-branching sentences were listed (Kemper 1988:61), and two noun complement clauses were erroneously described as relative clauses, one example was ungrammatical, and another of dubious grammaticality.
A study of the language of older adults by Cheung and Kemper (1992:64) found that speakers with larger Digit Spans produced sentences with more embedded clauses. Because the study was comparing different complexity metrics, the results of the memory and language measures were not reported in such a way as to allow comparison with the present investigation.
The common thread through all of Kemper’s work seems to be that she uses only one (poor) measure of WM, the analyses are only at the clausal level, embedding of every level is included and valued equally, and the spontaneous speech stimuli are not standard, by allowing the subjects largely to choose their own topics, which can be inherently more or less complex. These are methodological weaknesses, which the present study has sought to address.
The majority of the research into language complexity and WM has been in comprehension. This was one of the triggers that prompted the current study, that so much research effort had gone into comprehension, yet the relationship between production and WM in normal subjects remained almost uninvestigated.
An association between WM capacity and comprehension tasks is predicted (Tompkins et al. 1994:908) only for those conditions which are most demanding of resources, in which even the subjects with the highest spans would experience slowing of performance and error-proneness. The findings of this study indicate that, since there is a correlation between WM and complexity, language production is a sufficiently demanding task to engender differences in performance. The task of language production necessitates attention switching, requiring simultaneous message formulation, syntactic computation, physical articulation, and monitoring of performance. The production of language is, then, intrinsically a WM task. If the task of language production saturates WM capacity, it follows therefore that WM is a constraint on the production of complexity.
It should not, therefore, be surprising that language complexity ability is correlated with WM ability. A study of reading span and contextual vocabulary production fluency (Daneman & Green 1986:15) revealed a significant negative correlation between those tasks. The vocabulary production task could not truly be considered analogous to spontaneous language production, however, since it required subjects to produce orally an appropriate synonym to replace a sentence-final word in a written sentence (Daneman & Green 1986:12).
Daneman and Carpenter (1980:463,462) found that subjects with spans of less than 3.5 were less good at abstracting a theme from a written or spoken passage, and their errors on comprehension questions were more likely to reflect confusion or inability to remember. These researchers argued (1980:464) that working memory capacity differences could result in differences in the chunking process, so that the chunks formed by subjects with high spans would be being qualitatively different from those of the subjects with low spans, in terms of their richness, coherence, and the information contained within them. Only ten of the fifty subjects in the present study scored higher than 3.3 (66%) on AWMS (approximately the equivalent of Daneman and Carpenter’s 3.5) but, as a group, their complexity scores were not quantitatively different from those of the other subjects. In only three subjects (28, 31, and 41) did all their scores for the constituents of complexity fall above the means, which implies that, as a group, they were not qualitatively different either. For the 10 subjects with the top AWMS scores (i.e. 72% and above), their scores for AWMS, and for ILC and its four components, are given in the table below. The scores in bold are those that are above the overall mean.
subject
optcp
advp
modp
advbl
ILC
AWMS
AWMS%
28
4.712
6.387
4.084
3.665
18.848
4.6
92
13
4.198
5.025
3.944
4.707
17.875
4.6
92
37
3.433
7.239
4.104
4.328
19.104
4.6
92
34
4.695
4.468
2.036
3.111
14.310
4.6
92
47
3.033
5.359
2.932
2.326
13.650
4.3
86
8
5.474
6.549
2.737
3.715
18.475
3.6
72
41
5.188
7.103
3.644
3.891
19.827
3.6
72
31
4.611
6.576
2.989
3.672
17.848
3.6
72
45
5.616
4.536
2.376
2.160
14.687
3.6
72
29
4.509
6.185
2.775
2.543
16.012
3.6
72
MEAN
4.13
5.47
2.742
3.17
15.512
Table 14-23 ILC scores of subjects with top 10 AWMS scores
Of the top five subjects on AWMS, who scored 4.3 (86%) and above, only one (subject 28) showed a quantitative or qualitative difference in the complexity scores, by having all the component scores above the mean. (This subject also scored highly (83.9%) on AMIPB, and had the highest CMS score (1.76) of all the subjects.) It is acknowledged that there is a problem with insufficient numbers, as there are very few subjects in these high AWMS groups. A future study is planned, using the current data, to investigate whether those subordinating conjunctions, adverbs and adverbials which mature late in development, and therefore represent more sophisticated concepts, are more likely to occur in the speech of people with higher WM abilities.
One view of WM holds that there is a constantly fluctuating trade-off between the demands of storage and of processing, and that the requirements of the task affect performance. According to this view, although performance differences between subjects with different WM capacities are very small or negligible when a comprehension task is easy, when the task is demanding the differences are large and systematic (Just & Carpenter 1992:124). An alternative view holds that people with high WM spans have intrinsically greater resources to draw on, regardless of the difficulty of the task (Conway & Engle 1996:579). This latter view has been developed, to encompass the need for the WM task to involve controlled effortful processing, which forces the subject to switch his attention away from the storage aspect of the task (Conway & Engle 1996:588).
It could be argued that the difficulty of spontaneous language production can vary according to the context, the purpose of the interaction, the identity of the interlocutor, and the topic discussed. Nonetheless, the essential computational basis of the task of language production remains irreducible, no matter how informal the context or how congenial the interlocutor. The speaker ineluctably must shift his attention between considering the topic under discussion, the various levels of computation necessary to produce an utterance, and monitoring both his own output and the listener’s comprehension. The findings of this study show that subjects’ performances, in terms of productive complexity, correlate significantly with measures of WM. This could, however, be interpreted as meaning either that the task of language production is a sufficiently demanding task to demonstrate differential performance (the Just et al. view of WM) or that language production requires attention switching from storage to processing (the Conway and Engle view of WM).
It is, of course, possible that some other, as yet unsuspected, confounding factor is the explanation of the co-variation of WM and complexity, if some other aspect of brain performance were found to constrain both language and WM.
13.5 Ageing
One problem of including older subjects in a study is that, since both physiological and cognitive changes occur with increasing rapidity in the 50 to 65 age range, some older people who appear healthy and intact may in fact have early or subtle brain disease which only extensive examination would uncover (Lezak 1995:288). Lezak reports (1995:289) that cortical atrophy first shows up in the 40s, and the areas most susceptible to neuronal loss are the hippocampus (associated with memory formation) and the anterior dorsal frontal lobe. This nomenclature is somewhat vague, but implies the prefrontal cortex (BAs 9,10, and 46), which is thought (Engle, Kane, & Tuholski 1999:122) to be the critical brain area that mediates the functioning of WM, controlled attention, and general fluid intelligence (gF). The same prefrontal areas are also considered to be the locus of individual differences in these functions (Engle, Kane & Tuholski 1999:122), and age-related changes in dorsolateral prefrontal cortex have been shown, in a study using functional Magnetic Resonance Imaging (fMRI), to account for WM decline in normal ageing (Rypma & D'Esposito 2000).
13.5.1 Ageing and WM
It is widely acknowledged that increasing age has a deleterious effect on working memory performance, and this is particularly demonstrated in tests measuring recall (Lezak 1995:293). This was demonstrated in the results of this study, in the significant negative correlation between age and CMS. Both AMIPB and AWMS showed significant negative correlations with age, so the problem was not dependent on the individual task requirements of either test, but rather on the fact that both tasks tax WM.
That AMIPB scores would diminish in older adults was to be expected, because elderly people are known to perform less well than younger adults on tests of supraspan (Lezak 1995:293), and this is precisely what the AMIPB Story Recall subtest is. Lower performance on AWMS by older adults was also to be anticipated, because tests that demand concurrent retention and manipulation of information are known to be vulnerable to ageing (Lezak 1995:293).
Age-related changes in performance levels in WM tasks are substantial, declining systematically from early adulthood onwards (Craik 2000:81). Various reasons have been advanced for the age-related decrements in WM performance, including depleted attentional resources, a decline in processing speed, and a diminution of the ability to inhibit unwanted information (Craik 2000:81-2). Older adults have been found (Parkin and Walter 1991, cited by Reuter-Lorenz 2000:107) to perform more poorly than young adults, on a Brown-Peterson distraction task, which is, in essence, the truth~falsity judgement aspect of WM span tasks. Some form of age-related decrement in performance on the AWMS test is therefore to be expected. Scores on AWMS correlated significantly negatively with age (rho = -0.423**, N=50, p=0.002) and the Kruskal Wallis test indicated that at least one of the five age groups differed significantly from the others.
Free-recall tasks (such as AMIPB Story Recall) suffer a substantial age-related decline in performance (Grady & Craik 2000:224), which is exemplified in the declining scores in the AMIPB norms (Coughlan & Hollows 1985). The age-related changes are also evident in the significant negative correlation between age and AMIPB performance (rho = -0.494**, N=50, p<0.0005), and the significant difference found in this study between the five age groups. The subjects were also divided into four age groups corresponding to those in the AMIPB norms, and their raw scores compared with norm age group scores. This comparison is shown in the table below.
age group
à 30
31-45
46-60
61à
N
15
16
16
3
study mean
38.93
35.06
30.06
25.67
study SD
9.88
8.78
10.41
3.79
norm mean
39.2
33.0
34.1
30.7
norm SD
10.5
10.1
10.9
11.1
Table 14-24 Comparison of study and norm age groups
13.5.2 Ageing and complexity
Tasks that necessitate the holding, manipulation, and integration of moderate amounts of information over short time spans are known to be particularly difficult for older adults (Craik 2000:82). This is precisely the task involved in language production, where, in the generally accepted paradigm, concepts formulated at the message level are progressively encoded lexically and syntactically at the functional level, morphologically at the positional level, and phonologically and prosodically at the phonological level (Bock & Levelt 1994:945-6). The additional optional elements representing language complexity therefore increase the computational burden, and the demands on WM. Since WM is known to decline with increasing age (as was also demonstrated in this study) it is to be expected that older subjects will display lower levels of complexity. The present study showed that age was significantly negatively correlated with complexity, measured by ILC (rho = -0.443**, N=50, p =0.001), although the differences in performance of the five age groups did not achieve significance.
It has been noted (Carpenter et al. 1994:1101) that the age-related decline in the comprehension of complexity is not attributable to the loss of any specific linguistic computation. The consensus of opinion is that there is no specific age-related deterioration in syntactic processing, but rather that the decline in syntactic performance is attributable to the heavy WM demands of complex syntax (Wingfield & Stine-Morrow 2000:379). Those elements causing difficulty in comprehension for older adults are those that are considered to make demands on WM, which are also difficult for young subjects (Carpenter et al. 1994:1101).
The age-related decrement in WM appears to be reflected in a similar reduction in the production of multiple embeddings (Cheung & Kemper 1992:63). The steepest decline is reported for left-branching sentences, including those with sentence-initial subordinate clauses, that-clauses and wh-clauses as subjects, and relative clauses modifying the sentence subject (Cheung & Kemper 1992:54).
In a study on the effects of memory and genre on the language production of elderly adults, Kemper et al. (1989:64) suggest that older adults possibly avoid the use of complex syntactic constructions because they have discovered that other people have difficulty in understanding such items. They also remark (Kemper et al. 1989:65) that elderly adults appear to respond to their lower WM abilities by choosing to reduce the syntactic complexity of their production, in preference to producing automatic fillers or sentence fragments (mazes and unfinished utterances).
A problem with any study using participants of widely differing ages is that of comparability, in that time is not the only factor that is different for these subjects. The enormous social and economic changes of the past fifty years will undoubtedly have had an effect on the lives of older people, for example in the increasing availability of higher education (and the higher socio-economic status that entails) and the changing employment opportunities open to school-leavers. Thus an 80 year old who left school at 16 may well have had the intellectual capability to have achieved much more, in terms of education and status, than his socio-economic background made possible: he is not therefore truly comparable to a present-day 16 year old school-leaver. It is also likely that younger people will adopt a more casual style of expression, even in a formal experimental setting, than will older people (Kemper et al. 1989:64). These factors have always to be borne in mind when dealing with comparisons of performance across age cohorts.
13.6 Limitations of the study
Although this study has made reference to research into WM and language comprehension, and although theories of comprehension and productions are closely linked in that they have the same general scheme but with the processes running in the opposite direction (Wingfield & Stine-Morrow 2000:372), there is no actual evidence to show that the same neural architectures and processing machinery are used for both comprehension and production (Hagoort et al. 1999:277). There is no principled reason why the same brain areas and mechanisms should handle both comprehension and production. It is merely a presumption, based on the desire for parsimony, that the same neural architecture is used for both processes, because it is more parsimonious to assume that lemmas (the mental lexicon entry for a word including its syntactic properties) are singly rather than doubly neurally represented (Hagoort et al. 1999:276-7). This presumption is also based on the intuitive association between those sentences that are difficult both for hearers to comprehend and speakers to produce (Hagoort et al. 1999:276-7). On the other side of the argument, there are case reports of people with agrammatism who have deficits in production without a corresponding deficit in comprehension (Hagoort et al. 1999:277), which implies a dissociation between comprehension and production. It is therefore still an open question whether the neural machinery used for grammatical comprehension and production is the same or different (Hagoort et al. 1999:277). This means that, although both comprehension and production will be (at least partially) dependent on WM resources, if they were not represented by the same neural machinery, there is no a priori reason to assume that they will both be dependent on WM in the same way, or to the same extent.
The fact that this study does not attempt any experimental manipulation, but rather merely reports variation in WM and complexity pre-existing within participants, means that it is necessarily correlational in nature. The problem with this is that it can show only an association between variables, and does not allow causation to be attributed. Nonetheless, correlational data provide an important window on to the variation between individuals that is of both theoretical and practical importance to the study of working memory (Carpenter et al. 1994:1080). A corollary to this is that, since the subjects were an opportunity sample, they were not matched for age, sex, education, and social class. This meant that no inferences could be drawn as to the interactions of these variables.
It is acknowledged that no direct measurement of social intelligence was attempted in this study. Any such measurement would be of questionable value, since some tests of social intelligence (e.g.Happé 1994) are dichotomous, measuring only the presence versus the absence of social intelligence, rather than gradations of ability. All the subjects in this study were drawn from the normal population, and, in the absence of such problems as autism, Asperger Syndrome, or right hemisphere damage, ceiling performance would be expected. Other tests of social intelligence purport to provide quantified measures, but these are unsatisfactory, as they are assessed either subjectively (e.g. Van Horn et al. 1992; Yeates et al. 1991,), or on rating scales that are admitted to be crude and arbitrary (Ellis et al. 1994:260-1). Indeed, the production of improved stimuli to test social intelligence is included among possible future research, in section 14.7. It is to be expected that any test of social intelligence that requires the subject to decide between alternative (given) strategies in a social scenario will depend to a very large extent on the subject’s working memory capacity, in order to fully comprehend the nature of the social problem being described by the experimenter. A test that requires the subject to formulate and then describe his own strategy for dealing with a social situation will depend on his working memory capacity to generate and evaluate possible solutions, but also on his verbal abilities to delineate and describe those strategies and their ramifications in such a way that they are optimally comprehensible to the experimenter. Thus, the three elements of social intelligence, working memory, and language complexity may be seen as being complementary to each other.
That this study concentrated solely on language production is a limitation which should be addressed in any future studies. Had the subjects also been assessed for their ability in language comprehension, it would have been possible to have compared that level of performance with ability in production, and WM. However, assuming adherence to the oral/aural modality, the inclusion of additional tests to assess comprehension may cause the entire test interview to become over-long for members of the general public to be willing to participate. Moreover, such a test would probably necessitate the devising of fresh stimuli, as those in the literature frequently sound both unnatural and outdated. An example of this is one of the passages used by Daneman and Carpenter (Daneman & Carpenter 1980) as a stimulus in the comprehension test, telling the story of a group of teenagers in “the Grill”, who are listening to “the latest Rock and Roll favourites”. This passage includes the phrases I like most of the things other teenage boys like… milkshakes… and sneakers. It is not that I dislike rock music but I think it is supposed to be fun and not taken too seriously. And here he was, “all shook up” and serious over the crazy music. It must be recalled that this passage was used in a study published in 1980, not 1960, as might be assumed from its tone and content. The reaction of present day teenagers to this piece can be all too readily imagined.
The present study was restricted to the syntactic level of analysis of the spontaneous speech: no account was therefore taken of cohesion or coherence in the subjects’ output. Cohesion and coherence operate at the discourse level, and refer to the way in which ideas are related within and across sentences or utterances (McArthur 1996:213). Local coherence relies on cohesion between elements occurring in separate clauses, by means of reiteration of semantically linked items, or anaphoric reference (McDonald 1998:488-9); while global coherence depends on the nature of propositional content, its sequencing, and whether necessary information is omitted or irrelevant information included (McDonald 1998:488-9). The production of cohesion undoubtedly makes demands on WM resources. There is a necessity for the speaker continuously to shift his attention between preceding clauses and that currently under production (Thomas & Fraser 1994:589). Local cohesion problems should, therefore, be caught by the continuous self-monitoring that constitutes part of the production process. Global cohesion problems tend to show up in developmental disorders such as semantic-pragmatic disorder, or in people with psychiatric disorders. Children with semantic-pragmatic disorder produce language that is superfluent, but inappropriate to its context, showing little attempt to respond to questions, maintain or follow a topic, or adapt to the hearers’ needs (Brown & Edwards 1989:123-4). One of the characteristics noted in the language of people with psychiatric disorders is derailment, or loose association of ideas, which occurs when the speaker slips onto another idea which may be obliquely related, or entirely unrelated, to what he was previously saying, without any awareness that his reply no longer has any connection with the question asked (Andreasen 1986:476). A drawback to the examination of global cohesion, however, is the subjective and qualitative nature of its description, as it depends on the hearer’s judgements of how related or unrelated ideas may be.
Another level of analysis rejected by this study is that of lexical choice, which will have effects at both the semantic and sociolinguistic level. There can be little doubt that lexis is an excellent medium to demonstrate both personal prowess, through diverse, high register or obfuscatory verbiage, and group inclusivity, through the use of sociolinguistic in-group marked forms (Bradac 1990:396-7). In addition, access to the lexicon may be differentially affected by brain damage, in such conditions as anomia (impaired access to content words, especially nouns), semantic dementia (progressive impairment in word meaning, particularly nouns, eventually leading to a virtually complete dissolution of the semantic components of language, with largely preserved syntax (Hodges et al. 1992:1783)), and primary progressive aphasia (whose first signs are non-fluent aphasia and word production problems (Mesulam 1982:592)). The scrutiny of type-token ratios in child language gives an indication of the extent of a child’s vocabulary at a given stage of acquisition, but their use in the language of normal adults is not particularly informative, since what is considered to constitute a type is quite arbitrary (Reber & Reber 2001:771). What is more, the type-token ratio counts the number of individual different word roots (type) versus the total number of words (tokens). In view of the estimated size of adult vocabularies (conservatively ranging from 30, 000 to 50,000 words (McArthur 1996:1000)) the scrutiny of type-token ratios in the language of normal adults is not particularly informative. There does not, moreover, appear to be any relevant linguistic theory governing lexical choice, and any discussion would therefore necessarily be atheoretical. The study of lexical choice was therefore not appropriate to this study.
It is acknowledged that the end result of this study was not a particularly linguistic analysis, in that it took little account of higher theoretical issues in that field. There is no real reason why it should do so, since those issues may be purely theory-internal considerations, lacking in empirical validity. Leaving aside the pragmatic matter of the demonstrable difficulty in terms of language acquisition and disorders of the complexity elements, the selection of the elements to be investigated as manifestations of complexity was driven by evolutionary theory, since the elements were hypothesised to be those that instantiate social intelligence information. There were also biological considerations, in that working memory, which occupies a substantial amount of prefrontal cortex, will inevitably be costly in metabolic terms. The brain accounts for a mere 2% of body weight, but consumes 15% of the oxygen intake, 25% of metabolic energy, and 40% of blood glucose (Miller 2000:134). There are also developmental costs: the brain at birth represents 10% of a baby’s weight, but consumes 65% of the body’s energy (Badcock 2000:34).
13.7 Implications for future research
Concept formation and abstraction are known to diminish with age, with an increasingly steep decline after 70 (Lezak 1995:296). Verbal reasoning, however, is thought to remain relatively stable throughout the life-span, despite the ubiquitous difficulty of verbal retrieval and access to verbal memory, which affects at least some people in their 60s (Lezak 1995:294). Much would therefore seem to depend on the precise definition of a problem as requiring conceptual versus verbal reasoning. Complexity in language production might, then, be expected to diminish with age as a result of problems in the conceptual sphere, independently of WM decrements, although WM constraints would be expected to be the major factor. This could be investigated by examining whether those subordinating conjunctions, adverbs and adverbials which mature late in development, and therefore represent more sophisticated concepts, are less likely to occur in the speech of older people. A study to this effect, using the current data set, is planned for the future.
The present study has dealt only with English speakers. The complexity metric should, however, also be applicable (mutatis mutandis) to other languages. English is the only language reportedly used in studies of comprehension and WM ability, and, although garden path sentences would be unlikely to be possible in more inflected languages, it is to be assumed that object-trace relative clauses would pose an equal computational burden in other Indo-European languages. There is no a priori reason to suppose that the correlation between WM and complexity in language production should be language-specific to English, and future studies, using the tests and methods developed in this investigation, could investigate this in other languages (with appropriate assistance from native speakers).
Teachers of foreign languages need an objective means of assessing a student’s productive ability in the second language (L2), which is traditionally done in a subjective manner through oral examinations. (In such examinations, examiners informally listen for the presence and grammatical correctness of many of those elements regarded in this study as representing complexity.) If it could be shown that a person’s productive ability in his L2 correlated with his ability on AMIPB and AWMS in that language, it might be possible to measure productive ability in L2, simply and easily through WM tests in L2. It could therefore be possible that scores on WM tests could augment or even replace an oral examination. The major difficulty with this, though, is that a reasonably high level of ability in the second language has to be achieved, before it is possible to undertake the WM test in a second language, such that it would be applicable only to post A-level or undergraduate ability ranges. A study is currently under way of 12 successive bilinguals (6 L1 English~L2 German, and 6 L1 German~L2 English) to investigate the relationship between ability in the production of complexity in L1 vs L2 and ability on AMIPB and AWMS in L1 vs L2.
Long-standing controversy resulted from the conceptualisation of restricted versus elaborated code. Restricted code is characterised by short, simple, often incomplete sentences; repetitive use of conjunctions; limited use of adjectives and adverbs; and frequent use of idiomatic phrases (Bernstein 1959, cited in Edwards 1987:374). This description of restricted code resembles language with a low level of complexity (along with high nonpropositionality). Restricted code tends to develop within closed and multiplex social networks where the expression of solidarity is highly valued, and which are frequently found among working class communities (Ammon 1994:579). By contrast, elaborated code is characterised by sentence complexity, with use of conjunctions and clauses; a range of adjectives and adverbs; and conceptual organisation of experience (Bernstein 1959, cited in Edwards 1987:375). This description of elaborated code resembles language with high complexity. Bernstein noted (1964:62) that although restricted code is available to all levels of society, there is a relatively high probability that people from the working class will be limited to only that code, whereas those from the middle classes may use either restricted or elaborated code. It seems probable that high WM ability is a predisposing factor for a person to enter higher education and thereby to move up the socio-economic class scale, hence people with low WM ability will presumably be disproportionately over-represented in the lower socio-economic groups. It may be that Bernstein had noticed a valid phenomenon, but had imputed it to the wrong causal factor. Lower complexity would be associated primarily with lower WM ability, but with lower socio-economic class only as a corollary.
A possible future study is planned, to try out a new kind of WM task. The intention is that the task would entail the description, in reverse order, of a well-known behavioural script or schema, such as visiting a restaurant, or going to the doctor. Everyone should know (a variant of) the schema, but having to plan it out explicitly, and retell it in reverse order should constitute a demanding task. The test should have ecological validity, by combining the mundane realism of the schema with the experimental realism of considerable demands on attention.
Another planned study is to investigate the amount of complexity produced in the face of additional processing, as Barch and Bernebaum (1994) wanted to do. It is proposed that the test interview questions should be split into two smaller tests (with half the What & Why questions and half the Speculation questions in each). One test would be conducted as a simple interview, while the other would have a concurrent task sorting the kind of picture cards found in all speech therapy clinics into the relevant groups (e.g. food, transport, clothes etc.).
Ericsson and Kintsch maintain (1995:238-9) that domain-specific expert skills and the use of mnemonic strategies are the key to rapid access to information held within long term memory. The question then arises: can people be trained to develop language-specific expert skills? Skilled comprehenders are thought to make use of story schemas (cognitive frameworks that are taken for granted and shared by the members of a society), when approaching a text (Dennis & Lovett 1989:201), and it seems likely that skilled speakers use similar devices when producing utterances. Schemas have great adaptive value, in that they help to generate inferences in situations that contain only partial information (Denis 2000:595) The subordinating conjunctions (e.g. although, unless) and the adverbs and adverbials (e.g. nevertheless, moreover) that act as connective devices between clauses are postulated to activate a schema in long term memory, which would facilitate the construction of the clause. Evidence (e.g. Lee & Canter 1971; Scott 1988b) about the developmental order of acquisition of these conjunctive elements throughout adolescence points in the direction of an association with incremental development in the sophistication of the concepts enshrined in the schema and encoded by the connective elements. This was suggested (Bloom et al. 1980:248) for the connectives emerging in the earliest stages of language acquisition. Hirschman (2000), used classroom therapy sessions with children with SLI to teach them basic metalinguistic concepts, and to introduce them to the conceptual relationships inherent in various subordinating conjunctions. She found that by bringing these elements to the children’s attention, and drilling their use in the classroom situation, it was possible significantly to increase the use of subordinating conjunctions, in not only the children’s written but also their oral language. It would seem plausible that similar therapeutic value could be found in similar work on modifiers, adverbs and adverbials.
From a number of elements that were tried out as putative instantiations of complexity, this study selected the measure that worked best in the study 1 pilot data, by showing a relationship with WM. A future study is planned to examine how well the ILC performs as a measure of complexity, in comparison with other measures, such as the frequency of subject- and object-trace relative clauses, or the frequency of all embeddings at each level (VP, IP, and CP). This could be done initially on the existing study 2 data set.
In a new data set, derived from subjects whose selection had been balanced for age, sex, educational level, and occupation, it would be possible to examine the effects of any of those socio-economic variables on the production of complexity. Sociolinguistic research suggests differences between males and females in language use at the discourse level, and in the use of various sociolinguistic markers, and it would be interesting to examine the effects of sex on the ability to produce complex language. Similarly, a properly balanced subject group would be necessary to make any definitive judgements about the effect of age on the production of complexity. Data from a larger, balanced group of subjects would be expected to offer a better spread of results, especially at the upper and lower ends of the ability spectrum. This would make possible the further refinement of the complexity measure, possibly with differential weightings for different elements. The current measure, although it appears to function well as a group measure, is not absolutely precise at the individual level, and may not differentiate between individuals of similar levels of performance.
The ILC was formulated on the basis that it constitutes a plausible measure of complexity and also embodies social intelligence. A future study should examine the extent to which it measures social intelligence. A possible way of doing this would be to use a focused empirical study of language complexity in people whose occupation would appear to require high ability in complex language, versus those whose occupation would seem to require very little in the way of complex verbal communication skills. Example of the former would be a barrister, or university lecturer, and examples of the latter a gantry crane operator (who spends most of the working day in isolation) or a heavy plant operator (who would be precluded from much verbal communication by high levels of background noise). It would be essential to establish in advance how much complex communication actually takes place in any of the occupations investigated, rather than relying on preconceived ideas. (For example, the public perception of a librarian is of someone who hardly speaks all day, but in fact, a librarian spends the day in the discussion and negotiation of readers’ enquiries.)
Another possible way of testing social intelligence would entail the production of new stimuli along the lines of the stories to test interpersonal negotiation strategies in children (Yeates et al. 1991). Such stories set up scenario in which the protagonists have to resolve conflicting goals. In an example, A and B have to collaborate an a school project: A wants to do one topic, but B wants another (Yeates et al. 1991). The task is to work out how the problem could be resolved without conflict. A similar sort of interpersonal negotiation strategies task was used with adults who had head injuries (Van Horn et al. 1992). An example was that A and B work together in a restaurant kitchen, A wants to leave early before the bank closes, but as he is about to leave the dishwasher overflows and has to be cleaned up (Van Horn et al. 1992). The task is to negotiate through the possible strategies open to the protagonists, describing how each would feel about each possible outcome. The scoring system requires the examiner to judge the subject’s responses on a 4 point scale, from the point of view of developmental levels of reasoning in three social cognitive domains: concepts of persons, interpersonal negotiation strategies, and self-understanding (Van Horn et al. 1992:19). The subjectivity of the scoring makes it unreliable, and a more objective measure would have to be found.
13.8 Language complexity, working memory, and social intelligence
It is reported that health, financial security, social status, cognitive abilities and the ability to exercise common sense correlate with each other, and with longevity (Lehr and Schmitz-Scherzer 1976, cited by Lezak 1995:290). For “common sense”, it makes sense to read “social intelligence”, since this is what governs an individual’s ability to behave appropriately and guides his decision making. The listed attributes will almost certainly be desirable traits in a breeding partner, and it seems likely that an individual possessing them would wish to advertise the fact. Health, wealth and status are easily signalled by physical means, but cognitive ability and common sense, as mental attributes, cannot be signalled by these means. Miller proposes (2000:357) that, through language, minds are on public display, and therefore open to sexual choice. He is not specific, however, about which aspects of language he considers the locus of display.
Four forms of fluency have been proposed (Fillmore 1979:93). One is exemplified by disc jockeys, and consists of the ability to fill time with talk, by talking at length with few pauses. The second is exemplified by intellectual theoreticians, whose speech is coherent, reasoned, and semantically dense. An example of the third type is a person who is comfortable in many conversational environments, able to say the appropriate thing in a range of contexts. The fourth kind of fluency consists of creative and witty language use, where the speaker selects the form of expression that sounds most humorous from several forms open to him. Fillmore points out (1979:93) that the maximally gifted language user combines all these qualities. The problem with these descriptions is that they pay attention only to the speaker and his intention: the hearer’s reaction is unmentioned. The first and second kinds of speaker can both be extremely dull for the listener, providing either no information, or information that is indigestible; while the third may produce only platitudes; and in the fourth form of fluency, the humour may be apparent only to the speaker.
It is proposed, instead, that the optimal form of language display is through complexity. Complexity, as conceptualised in this study, is instantiated by those optional elements which supply information relevant to social intelligence. The speaker cannot supply this information without computational, and perhaps information-gathering, cost to himself. Complexity cannot be expressed without incurring WM costs to the speaker, as he produces the complex message on-line. This, of course, applies only to complexity in spontaneous speech: written complexity is largely irrelevant, since there is almost no WM component in its production.
The number, and particularly the complexity, of the mental representations that can be held in mind is crucial to the sophistication of the mental model available to an individual, and accordingly to his ability to calculate the consequences of behaviour, whether his own or that of others. Social intelligence calculations are thus dependent upon working memory ability. Much of the individual variation in working memory is due to variable degrees of mental retardation, just as much of the variation in height or symmetry is due to stunting, caused by such things as childhood illness or malnutrition (Bruce Charlton, pers. com., 28 August 2002). Proficiency in social intelligence is vital in the short term to the maintenance of an individual’s reputation and social position within a group, and in the long term to his reproductive success. It is therefore in an individual’s best interests to demonstrate to others his flair for social intelligence, and he can do this most easily through producing complex language.
The idea of public speech as covert courtship (Miller 2000:356) presupposes that display is for sexual selection. If, indeed, language is used as a form of sexual display, it may be expected that male performance as a whole would be superior to female performance, and that considerable differences between individual males would be demonstrated, since it is broadly true that males display and females choose from among them, competing for the highest status males (Ridley 1993:136-7). The idea that greater variability is to be found among males than among females goes back at least to Charles Darwin (Darwin 1874:231-2), as females select the best from among the males available to them. Miller comments (2000:375-6) that, by analogy with peahens observing and judging peacocks’ tails, female superiority in language comprehension should be expected, but with a presumed male superiority in language production. Published studies of language comprehension and WM do not appear to differentiate between the performances of males and females, so whether females are superior in comprehension is not known. Miller’s prediction of male productive superiority was not borne out in the present study, since, of the top ten performers on complexity, five were male and five female. The spread of scores on complexity were virtually identical for males and females: this was true both for the ILC overall and for its constituents. It should be noted, however, that this study was not designed to test sex differences, and that the participants were not matched by age, education or occupation, so this observation does not constitute a valid test of Miller’s prediction.
A fitness indicator is a biological trait that evolved to proclaim an individual’s fitness in terms of likelihood of reproductive success (Miller 2000:103). An individual’s fitness is determined chiefly by his genetic quality, which is in turn derived from the number and kind of mutations that have occurred in the genes that he carries (Miller 2000:103). Fitness in the evolutionary sense refers to success of an individual relative to his conspecific competitors, and relative to an environment which, for humans, is predominantly a social environment (Miller 2000:107). Fitness refers to statistical likelihood of success, rather than to an actual consequence (Miller 2000:107). As long as it is expensive to produce, and varies in its magnitude, almost any body part or behaviour can be an indicator of fitness (Miller 1998a:94). The importance of the brain is such that approximately half of the human genome is thought to be involved in the development of the brain, and about a third to be active only in the brain, making the brain a larger target for mutation than any other organ (Miller 2000:121-2), and therefore an excellent indicator of fitness. Miller comments (1998b:193) that it seems reasonable that intelligence serves as an indicator of neurophysiological efficiency and developmental stability. Since WM is intimately bound up with intelligence, it is arguable that complex language acts as a broadcast medium for high WM ability and cognitive fitness.
Undoubtedly a proportion of display performances will be motivated by display for sexual selection. However, there is also the dominance aspect of display, as each individual contests his place in the pecking-order within the same-sex members of his social group. Humans, as much as other primates, pursue high social rank, and an individual will seek out ways of improving his status and of communicating to others that his rank is higher than they would wish to concede (Barkow 1992:632-3). Linguistic ability appears to be admired in all cultures: (male) leaders need to be able to speak persuasively to influence the other men, and women with superior skills could accumulate better resources (Burling 1986:6,10,9). The most influential individuals observed in ethnographic studies are, as Burling points out (1986:11) also the most able verbally, and it is their linguistic skill that makes them appear to others in their group to be suited to positions of responsibility and status. The ability of an individual to outwit and out scheme others of his or her sex is attributable to larger brains (through evolutionary time) which in this way are thought to have contributed to reproductive success (Ridley 1993:21), and as Pinker points out (1994:368) a cognitive arms race could propel a linguistic one. For this purpose, it is in the interests of both males and females to perform to the best of their ability, and it is in this arena that the production of complex language is such a powerful signal.
The elements that make up the constituent parts of complexity represent the same elements that convey information related to social intelligence. The very optionality of these elements indicates that they express information that is not integral to a message, but rather that adds a particular gloss or interpretation to the message. This gloss is self-evidently the interpretation that the speaker wishes to imprint in the mind of the hearer, for his own purposes. The speaker’s intentions may be honest, or they may be manipulative: the means of communication remain the same.
A subordinating conjunction activates a schema, to guide the hearer’s interpretation of events or behaviour; while a relative clause or modifier phrase not only supplies additional information to identify an individual, a place, event or occasion, it also provides a biased description, seen from the speaker’s perspective. Adverbs and adverbials similarly deliver the impressions that the speaker wishes to convey to the hearer.
This is not to deny that the same messages could be communicated in a number of separate simple propositions, however, the desired gloss is most economically expressed as a complex utterance. Contrast John carelessly put the expensive vase that his mother gave him on the rickety old table (16 words) with John was careless. He put the vase on the table. His mother gave him the vase. It was expensive. The table was rickety. The table was old. (27 words). Not only is the collection of simple utterances longer, it is tediously repetitive, and would require no little charisma in the speaker to hold a hearer’s attention throughout its delivery. It is also arguably less efficient as a means of conveying information, since the larger volume of material to be processed, and stored temporarily before being recalled and assembled, would, in itself, create problems for the listener.
The contention is that complex language necessitates both high social intelligence and high WM ability. The presence of the optional social intelligence information elements demonstrates that an individual has a good understanding of the social network, and knows how to manipulate it to his advantage. The inclusion, in their grammatically relevant slots, of a large number of those same optional social intelligence information elements demonstrates that the individual has a large WM capacity, and is adept at rapid integration of multiple pieces of information. This is clearly adaptive, when allied to intelligence, construed as the likelihood of making correct judgements (Barlow 1983:208).
Any diminution in the amount of complexity produced by an individual, either within the totality of his output, or in relation to the output of others, bears significance. The contention of this study is that the production of complex language constitutes an honest signal of cognitive fitness, and therefore a lowered amount of complexity indicates a reduction in cognitive ability. This may be localised, for example, in cases where extra resources are needed at another cognitive level, where perhaps a particularly difficult or convoluted concept is being worked through, and consequently the language used at that particular juncture is less complex than the generality of the individual’s output. Alternatively, it may be a generalised diminution in complexity compared to the individual’s normal output, which might imply that the individual is tired, ill, or intoxicated. It may also be the case that that individual is actually performing to the best of his ability, but that his performance falls short of the norm for the rest of his social group. In this case, it would signal that his cognitive fitness was low in comparison to that of his peers. That individual would therefore be less likely to be successful in social interactions, or make good decisions, and would not be expected to achieve reproductive success. The ability to produce complex language therefore acts as a display of cognitive fitness, equivalent to proclaiming the power and efficiency of an individual’s brain, and consequently that individual’s likelihood to make good decisions, based on social intelligence. This display demonstrates the presence not only of good genes (necessary for long term reproductive success), but also of the individual’s good social aptitude, necessary for surviving and thriving in a social setting.
13.9 Conclusion
This study has attempted to fill a gap in the literature, by investigating the relationship between WM and complexity in language production, while looking at complexity from an evolutionary and biological perspective.
The methodology formulated in this study has provided an operationally usable instrument for examining the co-variation of WM and language complexity, which has performed well on a variety of tests of validity. The replication of the significant correlation, found in study 1, between WM and language complexity shows that the reliability was good when the two studies were compared.
The Combined Memory Score, as a measure of WM, is both internally and externally consistent, and offers greater precision than either of the component tests individually.
The Aural Working Memory Span test offers a new version of the working memory span paradigm, that is controlled for word length, imageability, word class, word frequency, and age of acquisition. The fact that it exists in four forms potentially allows for re-testing of individuals over time.
The test interview developed in the study reliably elicits complex spontaneous speech, in sufficient quantities for analysis, from subjects of differing ages and ability levels. The interview, taking some 20 to 25 minutes in all, is brief enough to be workable in practice
The selection of the elements that instantiate complexity was guided not only by evolutionary theory, and linguistic considerations, but also by the examination of data from language acquisition and disorders of various kinds. The Index of Language Complexity is therefore proposed as a principled measure of complexity.
The categorisation protocol provides detailed and explicit criteria for complexity. This offers a potentially objective and precise measure of complexity, which discriminates between high and low performances.
The complexity variables perform well, and are both internally and externally consistent, making the Index of Language Complexity an operationally viable measure of complexity in spontaneous speech, which now needs further empirical testing.
Bibliography
Abramson, J. H. 1990. Survey methods in community medicine. Edinburgh: Churchill Livingstone.
Adolphs, R. 1999. Social cognition and the human brain. Trends in Cognitive Sciences 3, no. 12: 469-479.
Afifi, A. A. and Clark, V. 1996. Computer-aided multivariate analysis. London: Chapman & Hall.
Ahlsen, E., Nespoulous, J.-L., Dordain, M., Stark, J., Jarema, G., Kadzielawa, D., Obler, L. K., and Fitzpatrick, P. M. 1996. Noun phrase production by agrammatic patients: a cross-linguistic approach. Aphasiology 10: 543-559.
Ammon, U. 1994. Sociolinguistic code. In The encyclopedia of language and linguistics:578-581. Oxford: Pergamon Press.
Andreasen, N. C. 1986. Scale for the assessment of thought, language, and communication (TLC). Schizophrenia Bulletin 12: 473-482.
Badcock, C. 2000. Evolutionary psychology: a critical introduction. Cambridge: Polity Press.
Baddeley, A. 1986. Working memory. Oxford: Clarendon Press.
Baddeley, A. 1996. The fractionation of working memory. Proceedings of the National Academy of Science, USA 93: 13468-13472.
Baddeley, A. 2000a. The episodic buffer: a new component of working memory? Trends in Cognitive Sciences 4: 417-423.
Baddeley, A. 2000b. Working memory: the interface between memory and cognition. In Cognitive neuroscience: a reader, ed. Gazzaniga, M. S.:292-304. Oxford: Blackwell.
Baddeley, A. 2001. The magic number and the episodic buffer. Behavioral and Brain Sciences 24: 117-118.
Baddeley, A., Gathercole, S., and Papagno, C. 1998. The phonological loop as a language learning device. Psychological Review 105: 158-173.
Baddeley, A., Logie, R., Nimmo-Smith, I., and Brereton, N. 1985. Components of fluent reading. Journal of Memory and Language 24: 119-131.
Baddeley, A. and Wilson, B. A. 2002. Prose recall and amnesia: implications for the structure of working memory. Neuropsychologia 40: 1737-1743.
Baddeley, A. D. 1999. Essentials of human memory. Hove: Psychology Press.
Baddeley, A. D. and Hitch, G. J. 2000. Development of working memory: should the Pascual-Leone and the Baddeley and Hitch models be merged? Journal of Experimental Child Psychology 77: 128-137.
Baddeley, A. D. and Logie, R. H. 1999. The multi-component model. In Models of working memory:mechanisms of active maintenance and executive control, ed. Miyake, A. and Shah, P.:28-61. Cambridge: Cambridge University Press.
Barber, C. 1997. Early modern English. Edinburgh: Edinburgh University Press.
Barch, D. M. and Berenbaum, H. 1994. The relationship between information processing and language production. Journal of Abnormal Psychology 103: 241-250.
Barch, D. M. and Berenbaum, H. 1997. Language generation in schizophrenia and mania: the relationships among verbosity, syntactic complexity, and pausing. Journal of psycholinguistic reseach 26: 401-412.
Barkow, J. H. 1992. Beneath new culture is old psychology: gossip and social stratification. In The adapted mind: evolutionary psychology and the creation of culture, ed. Barkow, J. H., Cosmides, L., and Tooby, J.:627-637. Oxford: Oxford University Press.
Barlow, H. B. 1983. Intelligence, guesswork, language. Nature 304: 207-209.
Baron-Cohen, S. 1995. Mindblindness: an essay on autism and Theory of Mind. London: MIT Press.
Beal, J. 1993. The grammar of Tyneside and Northumbrian English. In Real English: the grammar of English dialects in the British Isles, ed. Milroy, J. and Milroy, L.:187-213. London: Longman.
Beaman, K. 1984. Coordination and subordination revisited: syntactic complexity in spoken and written narrative discourse. In Coherence in spoken and written language, ed. Tannen, D.:45-80. Norwood: Ablex.
Beatty, J. 1995. Principles of behavioral neuroscience. Madison: Brown & Benchmark.
Bell, A. 1984. Language style as audience design. Language in Society 13: 145-204.
Bell, A. 1997. Language style as audience design. In Sociolinguistics: a reader and coursebook, ed. Coupland, N. and Jaworski, A.:240-250. Basingstoke: Palgrave.
Benton, A. L. and Hamsher, K. de S. 1989. Multilingual Aphasia Examination (MAE). Iowa City: A J A Associates.
Berndt, R. S. 2001. Sentence production. In The handbook of cognitive neuropsychology: what deficits reveal about the human mind, ed. Rapp, B.:375-396. Hove: Psychology Press.
Bernstein, B. 1959. A public language: some sociological implications of a linguistic form. British Journal of Sociology 10: 311-326.
Bernstein, B. 1964. Elaborated and restricted codes: their social origins and some consequences. American Anthropologist 66: 55-69.
Bishop, D. V. M. 1997. Uncommon understanding: development and disorders of language comprehension in children. Hove: Psychology Press.
Blake, J., Quartaro, G., and Onorati, S. 1993. Evaluating quantitative measures of grammatical complexity in spontaneous speech samples. Journal of Child Language 20: 139-152.
Bloom, L., Lahey, M., Hood, L., Lifter, K., and Fiess, K. 1980. Complex sentences: acquisition of syntactic connectives and the semantic relations they encode. Journal of Child Language 7: 235-261.
Bloom, P. and Markson, L. 1998. Capacities underlying word learning. Trends in Cognitive Sciences 2: 67-73.
Bock, J. K. 1987. Co-ordinating words and syntax in speech plans. In Progress in the psychology of language, ed. Ellis, A. W., 3:337-390. London: Erlbaum.
Bock, K. and Levelt, W. J. M. 1994. Language production: grammatical encoding. In Handbook of psycholinguistics, ed. Gernsbacher, M. A.:945-984. San Diego: Academic Press.
Bowerman, M. 1979. The acquisition of complex sentences. In Language acquisition: studies in first language development, ed. Fletcher, P. and Garman, M.:285-305. Cambridge: Cambridge University Press.
Brace, N., Kemp, R., and Snelgar, R. 2000. SPSS for psychologists: a guide to data analysis using SPSS for Windows (versions 8,9 and 10). London: Macmillan Press.
Bradac, J. J. 1990. Language attitudes and impression formation. In Handbook of language and social psychology, ed. Giles, H. and Robinson, W. P.:387-412. Chichester: John Wiley & Sons.
Bradshaw, J. L. 1997. Human evolution: a neuropsychological perspective. Hove: Psychology Press.
Bradshaw, J. L. and Mattingley, J. B. 1995. Clinical neuropsychology: behavioral and brain science. San Diego: Academic Press.
Broks, P. 1997. Brain, self, and others: the neuropsychology of social cognition. In Schizotypy, ed. Claridge, G.:98-123. Oxford: Oxford University Press.
Brookshire, R. and Nicholas, L. 1994. Speech sample size and test-retest stability of connected speech measures for adults with aphasia. Journal of Speech and Hearing Research 37: 399-407.
Brothers, L. 1990. The social brain: a project for integrating primate behavior and neurophysiology in a new domain. Concepts in Neuroscience 1: 27-51.
Brown, B. B. and Edwards, M. 1989. Developmental disorders of language. London: Whurr.
Brown, C. M. and Hagoort, P. 1999. The cognitive neuroscience of language: challenges and future directions. In The neurocognition of language, ed. Brown, C. M. and Hagoort, P.:3-14. Oxford: Oxford University Press.
Brown, R. 1973. A first language: the early stages. Cambridge, Mass.: Harvard University Press.
Burling, R. 1986. The selective advantage of complex language. Ethology and Sociobiology 7: 1-16.
Burton-Roberts, N. 1986. Analysing sentences: an introduction to English syntax. London: Longman.
Burton-Roberts, N. 1997. Analysing sentences: an introduction to English syntax. 2nd ed. London: Longman.
Byrne, R. W. and Whiten, A. 1997. Machiavellian intelligence. In Machiavellian intelligence II: extensions and evaluations, ed. Whiten, A. and Byrne, R. W.:1-23. Cambridge: Cambridge University Press.
Cappa, S. F. 2000. Cognitive neurology: an introduction. London: Imperial College Press.
Carpenter, P., Miyake, A., and Just, M. A. 1994. Working memory constraints in comprehension: evidence from individual differences, aphasia, and aging. In Handbook of psycholinguistics, ed. Gernsbacher, M. A.:1075-1122. San Diego: Academic Press.
Casaer, P. 1993. The human brain and longitudinal research in human development. In Longitudinal research in individual development: present status and future perspectives, ed. Magnusson, D. and Casaer, P.:51-59. Cambridge: Cambridge University Press.
Chambers, J. K. and Trudgill, P. 1980. Dialectology. Cambridge: Cambridge University Press.
Charlton, B. 2000. Psychiatry and the human condition. Oxford: Radcliffe Medical Press.
Cheshire, J. c1988. Social background to variation in British English syntax. In Regional variation in British English syntax, ed. Milroy, J. and Milroy, L.:8-24. London: Economic and Social Research Council.
Cheung, H. and Kemper, S. 1992. Competing complexity metrics and adults' production of complex sentences. Applied psycholinguistics 13: 53-76.
Chi, J. G., Dooling, E. C., and Gilles, F. H. 1977. Gyral development of the human brain. Annals of Neurology 1: 86-93.
Chomsky, N. 1965. Aspects of the theory of syntax. Cambridge, Mass.: MIT Press.
Chomsky, N. 1995. The Minimalist Program. Cambridge, Mass.: M I T Press.
Cinque, G. 1999. Adverbs and functional heads: a cross-linguistic perspective. New York: Oxford University Press.
Clancy, P. 1986. The acquisition of communicative style in Japanese. In Language acquisition and socialization across cultures, ed. Schieffelin, B. B. and Ochs, E. Cambridge: Cambridge University Press.
Coakes, S. J. and Steed, L. G. 1999. SPSS without anguish (versions 7.0,7.5, and 8.0 for Windows). Brisbane: John Wiley & Sons Australia, Ltd.
Collette, F., Van der Linden, M., and Poncelet, M. 2000. Working memory, long-term memory, and language processing: issues and future directions. Brain and Language 71: 46-51.
Conway, A. R. A. and Engle, R. W. 1996. Individual differences in working memory capacity: more evidence for a general capacity theory. Memory 4: 577-590.
Coolican, H. 1994. Research methods and statistics in psychology. London: Hodder & Stoughton.
Cosmides, L. and Tooby, J. 2000. The cognitive neuroscience of social reasoning. In The new cognitive neurosciences, ed. Gazzaniga, M. S.:1259-1270. Cambridge, Mass.: MIT Press.
Coughlan, A. K. and Hollows, S. E. 1985. The Adult Memory and Information Processing Battery (AMIPB) test manual. Leeds: A K Coughlan.
Cowan, N. 1998. Visual and auditory working memory capacity. Trends in Cognitive Sciences 2: 77-78.
Cowan, N. 2001. The magical number 4 in short-term memory: a reconsideration of mental storage capacity. Behavioral and Brain Sciences 24: 87-185.
Craik, F. I. M. 2000. Age-related changes in human memory. In Cognitive aging: a primer, ed. Park, D. C. and Schwarz, N.:75-92. Hove: Psychology Press.
Cummings, J. L. 1993. Frontal-subcortical circuits and human behavior. Archives of Neurology 50: 873-880.
Damasio, A. R. 1991. Concluding comments. In Frontal lobe function and dysfunction, ed. Levin, H. S., Eisenberg, H. M., and Benton, A. L.:401-407. New York: Oxford University Press.
Damasio, A. R. 1994. Descartes' error: emotion, reason and the human brain. London: Macmillan (Papermac).
Damasio, A. R. 1995. Toward a neurobiology of emotion and feeling: operational concepts and hypotheses. The Neuroscientist 1: 19-25.
Damasio, A. R. 1996. The somatic marker hypothesis and the possible functions of the prefrontal cortex. Philosophical Transactions of the Royal Society of London B 351: 1413-1420.
Damasio, A. R. and Damasio, H. 1992. Brain and language. Scientific American 267: (September) 63-73.
Daneman, M. 1984. Why some people are better readers than others: a process and storage account. In Advances in the psychology of human intelligence: volume 2, ed. Sternberg, R. J.:367-384. Hillsdale: Erlbaum.
Daneman, M. and Carpenter, P. A. 1980. Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behavior 19: 450-466.
Daneman, M. and Green, I. 1986. Individual differences in comprehending and producing words in context. Journal of Memory and Language 25: 1-18.
Darwin, C. 1874. The descent of man. New York: Prometheus Books.
de Geus, E. J. C., Wright, M. J., Martin, N. G., and Boomsma, D. I. 2001. Genetics of brain function and cognition. Behavior Genetics 31, no. 6: 489-495.
Denis, M. 2000. Psychological science in cross-disciplinary contexts. In International handbook of psychology, ed. Pawlik, K. and Rosenzweig, M. R.:585-597. London: Sage Publications.
Denison, D. 1998. Syntax. In The Cambridge history of the English language volume IV 1776-1997, ed. Romaine, S., IV:92-329. Cambridge: Cambridge University Press.
Dennis, M. and Lovett, M. W. 1989. Discourse ability in children after brain damage. In Discourse ability and brain damage: theoretical and empirical perspectives, ed. Joanette, Y. and Brownell, H. H.:199-223. New York: Springer-Verlag.
Dollaghan, C. A. 1987. Fast mapping in normal and language-impaired children. Journal of Speech and Hearing Disorders 52: 218-222.
Dunbar, R. 1996. Grooming, gossip and the evolution of language. London: Faber and Faber.
Dunbar, R. 1998. Theory of mind and the evolution of language. In Evolution of language: social and cognitive bases, ed. Hurford, J. R., Studdert-Kennedy, M., and Knight, C.:92-110. Cambridge: Cambridge University Press.
Duncan, J. and Owen, A. M. 2000. Common regions of the human frontal lobe recruited by diverse cognitive demands. Trends in Neuroscience 23: 475-483.
Edwards, J. 1987. Elaborated and restricted codes. In Sociolinguistics: an international handbook of the science of language and society: volume 1, ed. Ammon, U., Dittmar, N., and Mattheier, K. J.:374-378. Berlin: De Gruyter.
Edwards, S. 1995. Profiling fluent aphasic spontaneous speech: a comparison of two methodologies. European Journal of Disorders of Communication 30: 333-345.
Edwards, S., Garman, M., and Knott, R. 1993. The grammatical characterization of aphasic language. Aphasiology 7: 217-220.
Edwards, S. and Knott, R. 1994. Assessing spontaneous language abilities of aphasic speakers. Language Testing 11: 49-64.
Ellis, H. D., Ellis, D. M., Fraser, W., and Deb, S. 1994. A preliminary study of right hemisphere cognitive deficits and impaired social judgements among young people with Asperger Syndrome. European Child and Adolescent Psychiatry 3: 255-266.
Engle, R. W., Kane, M. J., and Tuholski, S. W. 1999. Individual differences in working memory capacity and what they tell us about controlled attention, general fluid intelligence, and functions of the prefrontal cortex. In Models of working memory: mechanisms of active maintenance and executive control, ed. Miyake, A. and Shah, P.:102-134. Cambridge: Cambridge University Press.
Engle, R. W., Laughlin, J. E., Tuholski, S. W., and Conway, A. R. A. 1999. Working memory, short-term memory, and general fluid intelligence: a latent-variable approach. Journal of Experimental Psychology: General 128: 309-331.
Ericsson, K. A., Chase, W. G., and Faloon, S. 1980. Acquisition of a memory skill. Science 208: 1181-1182.
Ericsson, K. A. and Kintsch, W. 1995. Long-term working memory. Psychological Review 102: 211-245.
Fabbro, F. 1999. The neurolinguistics of bilingualism: an introduction. Hove: Psychology Press.
Field, A. 2000. Discovering statistics using SPSS for Windows: advanced techniques for the beginner. London: Sage Publications.
Fillmore, C. J. 1979. On fluency. In Individual differences in language ability and language behavior, ed. Fillmore, C. J., Kempler, D., and Wang, W. S.-Y.:85-101. New York: Academic Press.
Fishman, J. A. 1997. Language and ethnicity: the view from within. In The handbook of sociolinguistics, ed. Coulmas, F.:327-343. Oxford: Blackwell.
Fishman, P. M. 1997. Interaction: the work women do. In Sociolinguistics: a reader and coursebook, ed. Coupland, N. and Jaworski, A.:416-429. Basingstoke: Palgrave.
Fletcher, P. 1990. The breakdown of language: language pathology and therapy. In The larger province of language, ed. Collinge, N. E.:422-457. London: Routledge.
Fletcher, P. 1999. Specific Language Impairment. In The development of language, ed. Barrett, M.:349-371. Hove: Psychology Press.
Fletcher, P. and Garman, M. 1988. Normal language development and language impairment: syntax and beyond. Clinical Linguistics and Phonetics 2: 97-113.
Ford, M. and Holmes, V. A. 1978. Planning units and syntax in sentence production. Cognition 6: 35-53.
Fowler, A. E. 1998. Language in mental retardation: associations with and dissociations from general cognition. In Handbook of mental retardation and development, ed. Burack, J. A., Hodapp, R. M., and Zigler, E.:290-333. Cambridge: Cambridge University Press.
Frazier, L. 1985. Syntactic complexity. In Natural language parsing: psychological, computational and theoretical perspectives, ed. Dowty, D. R., Kartunnen, L., and Zwicky, A. M.:129-189. Cambridge: Cambridge University Press.
Garrett, M. F. 1980. Levels of processing in sentence production. In Language production: volume 1, ed. Butterworth, B.:177-220. London: Academic Press.
Gathercole, S. E. 1999. Cognitive approaches to the development of short-term memory. Trends in Cognitive Sciences 3: 410-419.
Gathercole, S. E. and Baddeley, A. D. 1993. Working memory and language. Hove: Erlbaum.
Gathercole, S. E., Willis, C. S., Baddeley, A. D., and Emslie, H. 1994. The children's test of nonword repetition: a test of phonological working memory. Memory 2: 103-127.
Gavin, W. J., Klee, T., and Membrino, I. 1993. Differentiating specific language impairment from normal language development using grammatical analysis. Clinical Linguistics and Phonetics 7: 191-206.
Georgakopoulou, A. and Goutsos, D. 1997. Discourse analysis: an introduction. Edinburgh: Edinburgh University Press.
George, D. and Mallery, P. 1995. SPSS/PC+ step by step: a simple guide and reference. London: Wadsworth Publishing Company.
Geschwind, N. and Galaburda, A. M. 1987. Cerebral lateralization: biological mechanisms, associations and pathology. Cambridge, Mass.: MIT Press.
Gevins, A. and Smith, M. E. 2000. Neurophysiological measures of working memory and individual differences in cognitive ability and cognitive style. Cerebral Cortex 10: 829-839.
Giles, H. and Powesland, P. 1997. Accommodation theory. In Sociolinguistics: a reader and coursebook, ed. Coupland, N. and Jaworski, A.:232-239. Basingstoke: Palgrave.
Goldman-Rakic, P. S. 1996. The prefrontal landscape: implications of functional architecture for understanding human mentation and the central executive. Philosophical Transactions of the Royal Society of London B 351: 1445-1453.
Goldman-Rakic, P. S. 1997. Space and time in the mental universe. Nature 386: 559-60.
Gordon, B. 1997. Neuropsychology and advances in memory function. Current Opinion in Neurology 10: 306-312.
Grady, C. L. and Craik, F. I. M. 2000. Changes in memory processing with age. Current Opinion in Neurobiology 10: 224-231.
Grady, C. L., McIntosh, A. R., Horwitz, B., Maisog, J. M., Ungerleider, L. G., Mentis, M. J., Pietrini, P., Schapiro, M. B., and Haxby, J. V. 1995. Age-related reductions in human recognition memory due to impaired encoding. Science 269: 218-221.
Grice, H. P. 1975. Logic and conversation. In Syntax and semantics: volume 3: speech acts, ed. Cole, P. and Morgan, J. L.:41-58. New York: Academic Press.
Gülich, E. and Quasthoff, U. M. 1985. Narrative analysis. In Handbook of discourse analysis: volume 2: dimensions of discourse, ed. van Diyk, T. A.:169-197. London: Academic Press.
Haegeman, L. 1991. Introduction to government and binding theory. Oxford: Blackwell.
Hagoort, P., Brown, C. M., and Osterhout, L. 1999. The neurocognition of syntactic processing. In The neurocognition of language, ed. Brown, C. M. and Hagoort, P.:273-316. Oxford: Oxford University Press.
Hair, J. F., Anderson, R. E., Tatham, R. L., and Black, W. C. 1995. Multivariate data analysis: with readings. New Jersey: Prentice Hall.
Halford, G. S. 1998. Development of processing capacity entails representing more complex relations: implications for cognitive development. In Working memory and thinking, ed. Logie, R. H. and Gilhooly, K. J.:139-157. Hove: Psychology Press.
Happé, F. G. E. 1994. An advanced test of Theory of Mind: understanding of story characters' thoughts and feelings by able autistic, mentally handicapped, and normal children and adults. Journal of Autism and Developmental Disorders 24: 129-154.
Hirschman, M. 2000. Language repair via metalinguistic means. International Journal of Communication Disorders 35: 251-268.
Hodges, J. R. 1994. Cognitive assessment for clinicians. Oxford: Oxford University Press.
Hodges, J. R., Patterson, K., Oxbury, S., and Funnell, E. 1992. Semantic dementia: progressive fluent aphasia with temporal lobe atrophy. Brain 115: 1783-1806.
Hoff, E. 2001. Language development. Belmont: Wadsworth.
Hoff-Ginsberg, E. 1993. Landmarks in children's language development. In Linguistic disorders and pathologies: an international handbook, ed. Blanken, G., Dittman, J., Grimm, H., Marshall, J. C., and Wallesch, C. W.:558-573. Berlin: De Gruyter.
Hofland, K. and Johansson, S. 1982. Word frequencies in British and American English. Bergen: The Norwegian Computing Centre for the Humanities.
Hughes, D. L., Fey, M. E., and Long, S. H. 1992. Developmental Sentence Scoring: still useful after all these years. Topics in Language Disorders 12: 1-12.
Hulme, C. and Mackenzie, S. 1992. Working memory and severe learning difficulties. Hove: Erlbaum.
Hummel, J. 1999. Binding problem. In The MIT encyclopedia of the cognitive sciences, ed. Wilson, R. A. and Keil, F. C.:85-86. Cambridge, Mass.: MIT Press.
Humphrey, N. K. 1988. The social function of intellect. In Machiavellian intelligence: social expertise and the evolution of intellect in monkeys, apes and humans, ed. Byrne, R. W. and Whiten, A.:13-26. Oxford: Oxford University Press.
Hunt, K. W. 1970. Syntactic maturity in schoolchildren and adults. Monographs of the Society for Research in Child Development no.134. Chicago: Chicago University Press.
Hymowitz, P. and Spohn, H. 1980. The effects of antipsychotic medication on the linguistic ability of schizophrenics. Journal of Nervous and Mental Disease 168: 287-296.
Jacobson, M. 1991. Developmental neurobiology. London: Plenum Press.
Johnson, D. and Myklebust, H. 1967. Learning disabilities: educational principles and practices. New York: Grune & Stratton.
Johnston, J. R. and Kamhi, A. G. 1984. Syntactic and semantic aspects of the utterances of language-impaired children: the same can be less. Merrill-Palmer Quarterly 30: 65-86.
Jonides, J., Reuter-Lorenz, P. A., Smith, E. E., Awh, E., Barnes, L. L., Drain, M., Glass, J., Lauber, E. J., Patalano, A. L., and Schumacher, E. H. 1996. Verbal and spatial working memory in humans. Psychology of learning and motivation. 35: 43-88.
Just, M. A. and Carpenter, P. A. 1992. A capacity theory of comprehension: individual differences in working memory. Psychological Review 99: 122-149.
Kagitcibasi, C. 2000. (Cross) cultural psychology. In International handbook of psychology, ed. Pawlik, K. and Rosenzweig, M. R.:328-346. London: Sage.
Kandel, E. R., Schwartz, J. H., and Jessell, T. M., eds. 1995. Essentials of neural science and behavior. London: Prentice Hall International.
Kareev, Y. 1995. Through a narrow window: working memory capacity and the detection of covariation. Cognition 56: 263-269.
Karttunen, L. and Zwicky, A. M. 1985. Introduction. In Natural language parsing: psychological, computational and theoretical perspectives, ed. Dowty, D. R., Karttunen, L., and Zwicky, A. M.:1-25. Cambridge: Cambridge University Press.
Kemper, S. 1988. Geriatric psycholinguistics: syntactic limitations of oral and written language. In Language, memory and aging, ed. Light, L. L. and Burke, D. M.:58-76. Cambridge: Cambridge University Press.
Kemper, S. 1992. Adults' sentence fragments: who, what, when, where, and why. Communication Research 19: 444-458.
Kemper, S., Kynette, D., Rash, S., and O'Brien, K. 1989. Life-span changes to adults' language: effects of memory and genre. Applied Psycholinguistics 10: 49-66.
Kemper, S. and Sumner, A. 2001. The structure of verbal abilities in young and older adults. Psychology and Aging 16: 312-322.
Kertesz, A. 1993. Recovery and treatment. In Clinical neuropsychology, ed. Heilman, K. M. and Valenstein, E.:647-674. Oxford: Oxford University Press.
Kimball, J. 1973. Seven principles of surface structure parsing in natural language. Cognition 2: 15-47.
Kimura, D. 1992. Sex differences in the brain. Scientific American 267: 80-87.
King, J. and Just, M. A. 1991. Individual differences in syntactic processing: the role of working memory. Journal of Memory and Language 30: 580-602.
Kintsch, W., Healy, A. F., Hegarty, M., Pennington, B. F., and Salthouse, T. A. 1999. Eight questions and some general issues. In Models of working memory: mechanisms of active maintenance and executive control, ed. Miyake, A. and Shah, P.:412-441. Cambridge: Cambridge University Press.
Kucera, H. and Francis, W. N. 1967. Computational analysis of present day American English. Providence: Brown University Press.
Kyllonen, P. C. and Christal, R. E. 1990. Reasoning ability is (little more than) working-memory capacity?! Intelligence 14: 389-433.
Labov, W. 1972. Language in the inner city: studies in the Black English Vernacular. Phildelphia: University of Philadelphia Press.
Labov, W. 2001. Principles of linguistic change: volume 2 : social factors. Oxford: Blackwell.
Labov, W. and Waletzky, J. 1967. Narrative analysis: oral versions of personal experience. In Essays on the verbal and visual arts: proceedings of the 1966 annual spring meeting of the American Ethnological Society, ed. Helm, J.:12-44. Seattle: University of Washington Press.
Lakoff, R. 1973. Language and woman's place. Language in Society 2: 45-80.
Lecours, A. R. 1975. Myelogenetic correlates of the development of speech and language: volume 1. In Foundations of language development: a multidisciplinary approach, ed. Lenneberg, E. H. and Lenneberg, E.:121-135. London: Academic Press.
Lee, L. L. and Canter, S. M. 1971. Developmental Sentence Scoring: a clinical procedure for estimating syntactic development in children's spontaneous speech. Journal of Speech and Hearing Disorders 36: 315-340.
Leech, G. and Svartvik, J. 1994. A communicative grammar of English. London: Longman.
Lehman, M. T. and Tompkins, C. A. 1999. Reliability and validity of an auditory working memory measure: data from elderly and right-hemisphere damaged adults. Aphasiology 12: 771-785.
Lehr, U. and Schmitz-Scherzer, R. 1976. Survivors and non-survivors - two fundamental patterns of aging. In Patterns of aging, ed. Thomas, H. Basel: S. Karger.
Lesser, R. 1990. Language in the brain: neurolinguistics. In An encyclopaedia of language, ed. Collinge, N. E.:371-421. London: Routledge.
Levelt, W. J. M. 1999. Producing spoken language: a blueprint of the speaker. In The neurocognition of language, ed. Brown, C. M. and Hagoort, P.:83-122. Oxford: Oxford University Press.
Levelt, W. J. M. 2000. Psychology of language. In International handbook of psychology, ed. Pawlik, K. and Rosenzweig, M. R.:151-166. London: Sage Publications.
Lezak, M. 1995. Neuropsychological assessment, 3rd ed. Oxford: Oxford University Press.
Limber, J. 1973. The genesis of complex sentences. In Cognitive development and the acquisition of knowledge, ed. Moore, T. E.:169-185. London: Academic Press.
Linde, C. 1992. Conversational narrative. In International encyclopedia of linguistics:24-27. Oxford: Oxford University Press.
Lindenberger, U. and Baltes, P. B. 1994. Sensory functioning and intelligence in old age: a strong connection. Psychology and Aging 9: 339-355.
Locke, J. L. 1996. Why do infants begin to talk? Language as an unintended consequence. Journal of child language 23: 251-268.
Locke, J. L. 1997. A theory of neurolinguistic development. Brain and Language 58: 265-326.
Locke, J. L. 1998. Social sound-making as a precursor to spoken language. In Evolution of language: social and cognitive bases, ed. Hurford, J. R., Studdert-Kennedy, M., and Knight, C.:190-201. Cambridge: Cambridge University Press.
Locke, J. L. 1999. Towards a biological science of language development. In The development of language, ed. Barrett, M.:373-395. Hove: Psychology Press.
Logie, R. H. 1996. The seven ages of working memory. In Working memory and human cognition, ed. Richardson, J. T. E., Engle, R. W., Hasher, L., Logie, R. H., Stoltzfus, E. R., and Zacks, R. T.:31-65. Oxford: Oxford University Press.
Markowitsch, H. J. 2000. Memory and amnesia. In Principles of behavioral and cognitive neurology. 2nd ed., ed. Mesulam, M.-M.:257-293. Oxford: Oxford University Press.
Martin, R. C. and Freedman, M. L. 2001. Short-term retention of lexical-semantic representations: implications for speech production. Memory 9: 261-280.
McArthur, T., ed. 1996. The Oxford companion to the English language. Oxford: Oxford University Press.
McCawley, J. D. 1998. The syntactic phenomena of English. Chicago: University of Chicago Press.
McCormick, K. M. 1994. Gender and language. In Encyclopedia of language and linguistics:1353-1360. Oxford: Pergamon.
McDonald, S. 1998. Communication and language disturbances following traumatic brain injury. In Handbook of neurolinguistics, ed. Stemmer, B. and Whitaker, H. A.:485-494. San Diego: Academic Press.
Mesthrie, R. 1994. Linguistic variation. In Encyclopedia of language and linguistics:4900-4909. Oxford: Pergamon.
Mesulam, M.-M. 1982. Slowly progressive aphasia without generalised dementia. Annals of Neurology 11: 592-598.
Miller, G. 1998a. How mate choice shaped human nature: a review of sexual selection and human evolution. In Handbook of evolutionary psychology: ideas, issues, and applications, ed. Crawford, C. and Krebs, D. L.:87-129. New Jersey: Erlbaum.
Miller, G. 1998b. Mate choice turns cognitive. Trends in Cognitive Sciences 2: 190-198.
Miller, G. 2000. The mating mind: how sexual choice shaped the evolution of human nature. London: Vintage.
Miller, G. A. 1956. The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychological Review 63: 81-96.
Milroy, L. 1987. Observing and analysing natural language: a critical account of the sociolinguistic method. Oxford: Blackwell.
Miyake, A. and Shah, P. 1999. Emerging consensus, unresolved theoretical issues, and future research directions. In Models of working memory: mechanisms of active maintenance and executive control, ed. Miyake, A. and Shah, P.:442-481. Cambridge: Cambridge University Press.
Montgomery, J. W. 1992. Easily overlooked language disabilities during childhood and adolescence: a cognitive-linguistic perspective. Pediatric Clinics of North America 39: 513-524.
Morice, R. D. and Ingram, J. C. L. 1982. Language analysis in schizophrenia: diagnostic implications. Australian and New Zealand Journal of Psychiatry 16: 11-21.
Morice, R. D. and Ingram, J. C. L. 1983. Language complexity and age of onset in schizophrenia. Psychiatry Research 9: 233-242.
Morrison, C. M., Chappell, T. D., and Ellis, A. W. 1997. Age of acquisition norms for a large set of object names and their relation to adult estimates and other variables. Quarterly Journal of Experimental Psychology 50A: 528-559.
Morrison, C. M., Ellis, A. W., and Quinlan, P. T. 1992. Age of acquisition, not word frequency, affects object naming, not object recognition. Memory and Cognition 20: 705-714.
Naito, M. and Komatsu, S.-i. 1993. Processes involved in childhood development of implicit memory. In Implicit memory: new directions in cognition, development and neuropsychology, ed. Graf, P. and Masson, M. E. J.:231-260. Hillsdale: Erlbaum.
Nelson, H. E. 1982. National Adult Reading Test (NART) test manual. Windsor: NFER-Nelson Publishing Company.
Nelson, K. 1990. Remembering, forgetting, and childhood amnesia. In Knowing and remembering in young children, ed. Fivush, R. and Hudson, J. A.:310-316. New York: Cambridge University Press.
Neville, H. J. and Bavelier, D. 1998. Neural organisation and plasticity of language. Current Opinion in Neurobiology 8: 254-258.
Nippold, M. A. 1988. Introduction. In Later language development: ages 9 through 19, ed. Nippold, M. A.:1-10. Boston: College Hill.
Norusis, M. J. 1998. SPSS 8.0: guide to data analysis. New Jersey: Prentice Hall.
Ojemann, G. A. 1991. Cortical organization of language. Journal of Neuroscience 11: 2281-2287.
Olson, G. M. 1973. Developmental changes in memory and the acquisition of language. In Cognitive development and the acquisition of language, ed. Moore, T. E.:145-157. London: Academic Press.
Owens, R. 1989. Cognition and language in the mentally retarded population. In Language and communication in people with learning disabilities, ed. Beveridge, M., Conti-Ramsden, G., and Leudar, I.:112-142. London: Routledge. Original edition, first published as Language and communication in mentally handicapped people.
Pagano, R. R. 2001. Understanding statistics in the behavioral sciences. Belmont: Wadsworth/Thomson Learning.
Park, D. C. 2000. The basic mechanisms accounting for age-related decline in cognitive function. In Cognitive aging: a primer, ed. Park, D. C. and Schwarz, N.:3-21. Hove: Psychology Press.
Parkin, A. J. and Walter, B. M. 1991. Aging, short-term memory and frontal dysfunction. Psychobiology 19: 175-179.
Paulesu, E., Frith, C. D., and Frackowiak, R. S. J. 1993. The neural correlates of the verbal component of working memory. Nature 362: 342-345.
Pawlik, K. 2000. Psychological assessment and testing. In International handbook of psychology, ed. Pawlik, K. and Rosenzweig, M. R.:365-406. London: Sage.
Pease, A. 1997. Body language: how to read others' thoughts by their gestures. London: Sheldon Press.
Pennington, B. F. and Bennetto, L. 1998. Toward a neuropsychology of mental retardation. In Handbook of mental retardation and development, ed. Burack, J. A., Hodapp, R. M., and Zigler, E.:80-114. Cambridge: Cambridge University Press.
Perkins, M. 1994. Repetitiveness in language disorders: a new analytical procedure. Clinical Linguistics and Phonetics 8: 321-336.
Piatelli-Palmarini, M., ed. 1980. Language and learning: the debate between Jean Piaget and Noam Chomsky. Cambridge, Mass.: Harvard University Press.
Pinker, S. 1994. The language instinct. New York: Morrow.
Quirk, R. et al. 1985. A comprehensive grammar of the English language. London: Longman.
Quirk, R. and Greenbaum, S. 1973. A university grammar of English. Harlow: Longman.
Radford, A. 1990. Syntactic theory and the acquisition of English syntax. Oxford: Blackwell.
Radford, A. 1997. Syntactic theory and the structure of English: a minimalist approach. Cambridge: Cambridge University Press.
Raichle, M. E. 1993. The scratchpad of the mind. Nature 363: 583-584.
Reber, A. S. and Reber, E. S. 2001. The Penguin dictionary of psychology. London: Penguin Books.
Reuter-Lorenz, P. A. 2000. Cognitive neuropsychology of the aging brain. In Cognitive aging: a primer, ed. Park, D. C. and Schwarz, N.:93-114. Hove: Psychology Press.
Reuter-Lorenz, P. A., Jonides, J., Smith, E. E., Hartley, A., Miller, A., Marshuetz, C., and Koeppe, R. A. 2000. Age differences in frontal lateralization of verbal and spatial working memory revealed by PET. Journal of Cognitive Neuroscience 12: 188-196.
Ridley, M. 1993. The red queen: sex and the evolution of human nature. London: Penguin.
Ridley, M. 1996. The origins of virtue. London: Viking.
Romaine, S. 1994. Language in society: an introduction to sociolinguistics. Oxford: Oxford University Press.
Rosenberg, S. and Abbeduto, L. 1987. Indicators of linguistic competence in the peer group conversational behavior of mildly retarded adults. Applied Psycholinguistics 8: 19-32.
Rypma, B. and D'Esposito, M. 2000. Isolating the neural mechanisms of age-related changes in human working memory. Nature Neuroscience 3: 509-515.
Saffran, E., M., Berndt, R. S., and Schwartz, M. F. 1989. The Quantitative Analysis of Agrammatic Production: procedure and data. Brain and Language 37: 440-479.
Scarborough, H. S. 1990. Index of Productive Syntax. Applied Psycholinguistics 11: 1-22.
Scarborough, H. S., Rescorla, L., Tager-Flusberg, H., Fowler, A. E., and Sudhalter, V. 1991. The relation of utterance length to grammatical complexity in normal and language-disordered groups. Applied Psycholinguistics 12: 23-45.
Scott, C. M. 1988a. Producing complex sentences. Topics in Language Disorders 8: 44-62.
Scott, C. M. 1988b. Spoken and written syntax. In Later language development: ages 9 through 19, ed. Nippold, M. A.:49-95. Boston: College Hill.
Serpell, R. 1977. Strategies for investigating intelligence in its cultural context. Quarterly Newsletter, Institute for Comparative Human Development 3: 11-15.
Shallice, T. and Evans, M. E. 1978. The involvement of the frontal lobes in cognitive estimation. Cortex 14: 294-303.
Sheskin, D. J. 2000. Handbook of parametric and nonparametric statistical procedures 2nd ed. London: Chapman and Hall.
Shewan, C. M. 1988. The Shewan Spontaneous Language Analysis (SSLA) System for aphasic adults: description, reliability, and validity. Journal of Communication Disorders 21: 103-138.
Siegal, M., Varley, R., and Want, S. C. 2001. Mind over grammar: reasoning in aphasia and development. Trends in Cognitive Sciences 5: 296-301.
Siegel, L. S. 1994. Working memory and reading: a life-span perspective. International Journal of Behavioural Development 17: 109-124.
Siegel, S. and Castellan, N. J. J. 1988. Nonparametric statistics for the behavioral sciences. New York: McGraw-Hill.
Simon, H. A. 1974. How big is a chunk? Science 183: 482-488.
Smith, A. 1970. The body. London: Penguin.
Smith, E. E. and Jonides, J. 1998. Neuroimaging analyses of human working memory. Proceedings of the National Academy of Sciences 95: 12061-12068.
Snowdon, D. 2001. Aging with grace: the Nun Study and the science of old age: how we can all live longer, healthier, and more vital lives. London: Fourth Estate.
Standard occupational classification 2000. 2000. London: Stationery Office.
Stuss, D. T. 1992. Biological and psychological development of executive functions. Brain and cognition 20: 8-23.
Tabachnick, B. G. and Fidell, L. S. 2001. Using multivariate statistics. Boston: Allyn & Bacon.
Tager-Flusberg, H. 1999. Language development in atypical children. In The development of language, ed. Barrett, M.:311-348. Hove: Psychology Press.
Thatcher, R. W., Walker, R. A., and Giudice, S. 1987. Human cerebral hemispheres develop at different rates and ages. Science 236: 1110-1113.
Thomas, P. and Fraser, W. 1994. Linguistics, human communication and psychiatry. British Journal of Psychiatry 165: 585-592.
Thomas, P., Kearney, G., Napier, E., Ellis, E., Leudar, I., and Johnston, M. 1996a. The reliability and characteristics of the Brief Syntactic Analysis. British Journal of Psychiatry 168: 334-337.
Thomas, P., Kearney, G., Napier, E., Ellis, E., Leudar, I., and Johnston, M. 1996b. Speech and language in first onset psychosis: differences between people with schizophrenia, mania, and controls. British Journal of Psychiatry 168: 337-343.
Thomas, P., King, K., Fraser, W. I., and Kendell, R. E. 1990. Linguistic performance in schizophrenia: a comparison of acute and chronic patients. British Journal of Psychiatry 156: 204-210.
Thompson, I. M. 1988. Communication changes in normal and abnormal ageing. In Neuropsychology and ageing: definitions, explanations and practical approaches, ed. Holden, U.:121-153. London: Croom Helm.
Tomasello, M. 2000. The item-based nature of children's early syntactic development. Trends in Cognitive Sciences 4: 156-163.
Tompkins, C. A., Bloise, C. G. R., Timko, M. L., and Baumgaertner, A. 1994. Working memory and inference revision in brain-damaged and normally aging adults. Journal of Speech and Hearing Research 37: 896-912.
Tortora, G. J. and Grabowski, S. R. 1996. Principles of anatomy and physiology. Menlo Park, California: Addison Wesley Longman Inc.
Treisman, A. 1996. The binding problem. Current Opinion in Neurobiology 6: 171-178.
Ullman, M. T., Corkin, S., Coppola, M., Hickok, G., Growdon, J. H., Koroshetz, W. J., and Pinker, S. 1997. A neural dissociation within language: evidence that the mental dictionary is part of declarative memory, and that grammatical rules are processed by the procedural system. Journal of Cognitive Neuroscience. 9: 266-276.
Van Horn, K. R., Levine, M. J., and Curtis, C. L. 1992. Developmental levels of social cognition in head-injury patients. Brain Injury 6: 15-28.
Van Petten, C. and Bloom, P. 1999. Speech boundaries, syntax and the brain. Nature Neuroscience 2: 103-104.
Varley, R., Siegal, M., and Want, S. C. 2001. Severe impairment in grammar does not preclude Theory of Mind. Neurocase 7: 489-493.
Wales, R. 1986. Deixis. In Language acquisition: studies in first language development, ed. Fletcher, P. and Garman, M.:401-428. Cambridge: Cambridge University Press.
Wardhaugh, R. 2002. An introduction to sociolinguistics. Oxford: Blackwell.
Wechsler, D. 1955. Manual for the Wechsler Adult Intelligence Scale. New York: Psychological Corporation.
Wechsler intelligence scale for children: revised: Scottish standardization (WISC-R S). ca.1987. London: Psychological Corporation.
Weist, R. M. 1986. Tense and aspect. In Language acquisition: studies in first language development, ed. Fletcher, P. and Garman, M.:356-374. Cambridge: Cambridge University Press.
Whitaker, H. A. and Selnes, O. A. 1976. Anatomic variations in the cortex: individual differences and the problem of the localization of language functions. Annals of the New York Academy of Sciences 280: 844-854.
Wilson, M. and Emmorey, K. 1997. A visuospatial "phonological loop" in working memory: evidence from American Sign Language. Memory and Cognition 25: 313-320.
Wingfield, A. 2000. Speech perception and the comprehension of spoken language in adult aging. In Cognitive aging: a primer, ed. Park, D. C. and Schwarz, N.:175-195. Hove: Psychology Press.
Wingfield, A. and Stine-Morrow, E. A. L. 2000. Language and speech. In The handbook of aging and cognition, ed. Craik, F. I. M. and Salthouse, T. A.:359-416. New Jersey: Erlbaum.
Wright, M., de Geus, E. J. C., Ando, J., Luciano, M., Posthuma, D., Ono, Y., Hansell, N., Van Baal, C., Hiraishi, K., Hasegawa, T., Smith, G., Geffen, G., Geffen, L., Kanba, S., Miyake, A., Martin, N., and Boomsma, D. I. 2001. Genetics of cognition: outline of a collaborative twin study. Twin Research 4: 48-56.
Yakovlev, P. I. and Lecours, A.-R. 1967. The myelogenetic cycles of regional maturation of the brain. In Regional development of the brain in early life, ed. Minkowski, A.:3-70. Oxford: Blackwell.
Yaruss, J. S. 1999. Utterance length, syntactic complexity, and childhood stuttering. Journal of Speech, Language and Hearing Research 42: 329-344.
Yeates, K. O., Schultz, L. H., and Selman, R. L. 1991. The development of interpersonal negotiation strategies in thought and action: a social-cognitive link to behavioral adjustment and social status. Merrill-Palmer Quarterly 37: 369-405.
Ylvisaker, M., Feeney, T. J., and Szekeres, S. F. 1998. Social-environmental approach to communication and behavior. In Traumatic brain injury rehabilitation: children and adolescents, ed. Ylvisaker, M.:271-302. Boston: Butterworth-Heinemann.
Yngve, V. H. 1960. A model and an hypothesis for language structure. Proceedings of the American Philosophical Society 104: 444-466.
Christina Susan Fry,
PhD thesis[ contact BG Charlton : bruce.charlton@ncl.ac.uk ]